Sesión 9B#
Introducción a redes bayesianas#
Objetivos:
Aprender qué es una red Bayesiana y cómo se factorizan distribuciones sobre ellas.
¿Qué son los modelos gráficos probabilísticos?#
Los MGPs son un marco para representar y razonar sobre incertidumbre en sistemas complejos.
El nombre tiene tres palabras clave: modelos, gráficos y probabilísticos.
Modelos#
Representación declarativa de cómo entendemos el mundo.
Permite separar:
La construcción del modelo (por humano o mediante aprendizaje automático).
De los algoritmos de inferencia (que responden preguntas sobre el modelo).
De los métodos de aprendizaje (que ajustan sus parámetros con datos).
Un «modelo» gráfico probabilístico describe cómo creemos que las cosas se relacionan, sin importar todavía cómo las calculamos.
Probabilísticos#
Se llama así porque los modelos tratan con incertidumbre.
«Probabilístico» significa que el modelo admite la duda y razona con ella de forma lógica
Gráficos#
Es gráfico porque usamos grafos (nodos y aristas) para representar las dependencias entre variables.
Cada nodo representa una variable aleatoria.
Cada arista indica una relación probabilística (una dependencia directa).
Estos grafos permiten:
Representar distribuciones gigantes de forma compacta (sin enumerar todas las combinaciones posibles).
Razonar, usando la estructura del grafo para decidir qué variables influyen en cuáles.
Aprender sus parámetros con pocos datos o cinluso con ayuda de expertos humanos.
«Gráfico» significa que el modelo usa conexiones visuales (nodos y aristas) para representar dependencias probabilísticas entre variables.
1. Preliminares#
1.1. Ejemplo: Modelo de estudiante#
Consideramos el caso de un estudiante dentro de un curso.
Queremos razonar acerca de las siguientes variables aleatorias:
I → Inteligencia del estudiante
D → Dificultad del curso
C → Calificación del estudiante dentro del curso
E → Puntaje en las pruebas estandarizadas
R → Carta de recomendación laboral emitida por el profesor
Discretización de variables#
Inteligencia (I)
\(i^0\): inteligencia baja
\(i^1\): inteligencia alta
Dificultad (D)
\(d^0\): curso fácil
\(d^1\): curso difícil
Calificación (C)
\(c^0\): baja (\(C < 6\))
\(c^1\): media (\(6 \leq C < 9\))
\(c^2\): alta (\(C \geq 9\))
Puntaje de examen (E)
\(e^0\): mal puntaje
\(e^1\): buen puntaje
Carta de recomendación (R)
\(r^0\): carta débil
\(r^1\): carta fuerte
❓ Pregunta#
De no usar modelos gráficos probabilísticos, ¿cuántos parámetros necesitaríamos para especificar por completo la distribución sobre las cinco variables mencionadas(\(I, D, C, E, R\))?
Respuesta
Cada variable puede tomar un cierto número de valores:
Por tanto, el número total de combinaciones posibles es:
Son parámetros independientes aquellos cuyo valor no está completamente determinado por el valor de otros parámetros.
En este caso, la distribución \(P(I,D,C,E,R)\) se especifica con 48 parámetros, sin embargo, si hablamos de parámetros independientes:
Si no utilizáramos modelos gráficos probabilísticos, necesitaríamos 47 parámetros independientes para especificar completamente la distribución conjunta sobre las variables \(I, D, C, |, R\).
Red Bayesiana#
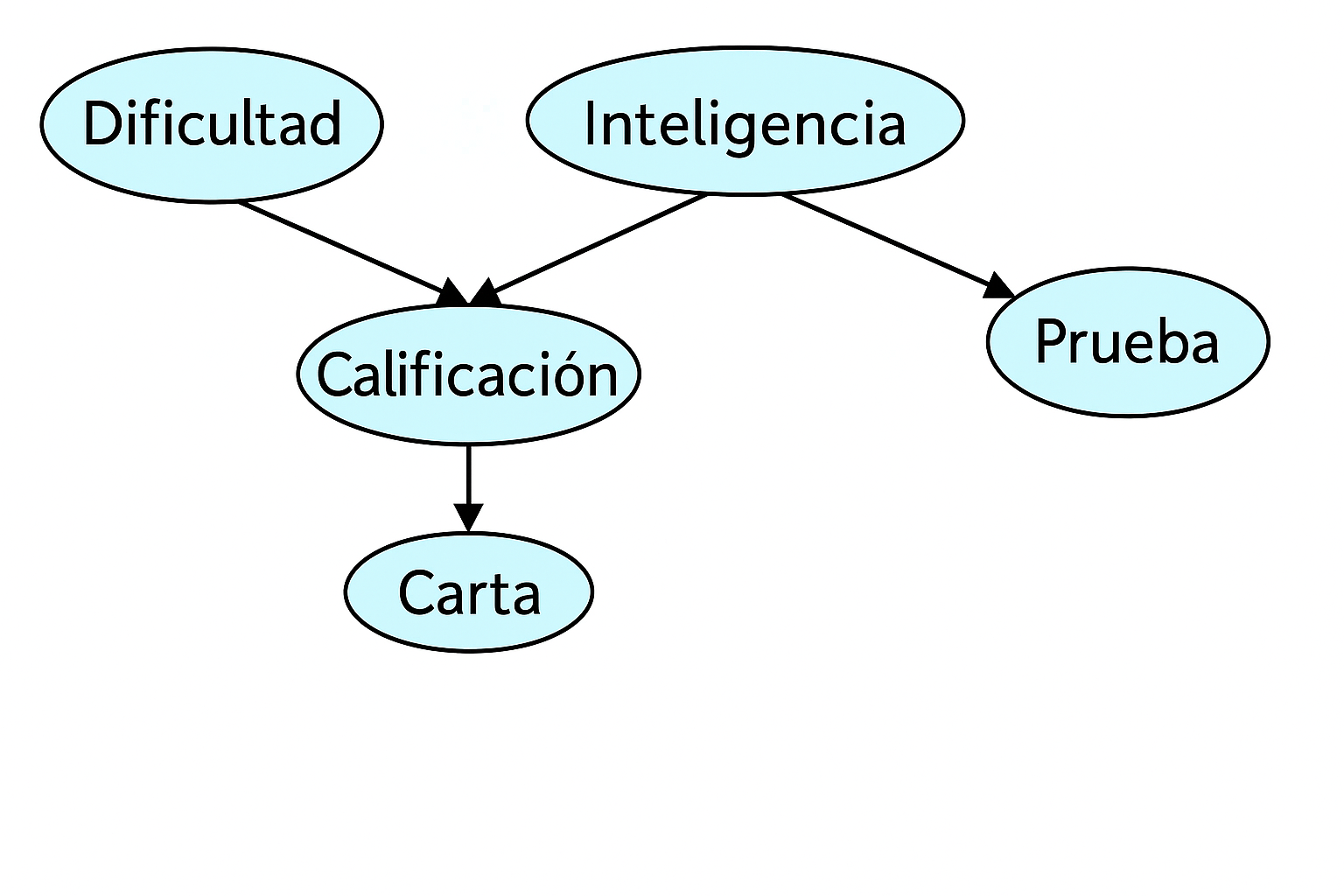
Proponemos la siguiente estructura:
La inteligencia \(I\) y la dificultad \(D\) causan la calificación \(C\).
La inteligencia \(I\) influye en el puntaje \(E\) de pruebas estandarizadas.
La calificación \(C\) influye en la recomendación \(R\).
from IPython.display import Image
Image("../images/sesion9-student-model.png", width=700)
1.2. Distribuciones de probabilidad y sus operaciones#
Consideremos el ejemplo del estudiante, esta vez reducido a las variables \(I\), \(D\) y \(C\).
Una distribución conjunta, \(P(I,D,C)\), sobre estas tres variables es:
\(I\) |
\(D\) |
\(C\) |
\(P\) |
|---|---|---|---|
\(i^0\) |
\(d^0\) |
\(c^0\) |
0.126 |
\(i^0\) |
\(d^0\) |
\(c^1\) |
0.168 |
\(i^0\) |
\(d^0\) |
\(c^2\) |
0.126 |
\(i^0\) |
\(d^1\) |
\(c^0\) |
0.126 |
\(i^0\) |
\(d^1\) |
\(c^1\) |
0.045 |
\(i^0\) |
\(d^1\) |
\(c^2\) |
0.009 |
\(i^1\) |
\(d^0\) |
\(c^0\) |
0.0056 |
\(i^1\) |
\(d^0\) |
\(c^1\) |
0.0224 |
\(i^1\) |
\(d^0\) |
\(c^2\) |
0.252 |
\(i^1\) |
\(d^1\) |
\(c^0\) |
0.024 |
\(i^1\) |
\(d^1\) |
\(c^1\) |
0.036 |
\(i^1\) |
\(d^1\) |
\(c^2\) |
0.06 |
Pregunta. ¿Cuántos parámetros en total?
Respuesta
from pgmpy.factors.discrete import JointProbabilityDistribution
from pgmpy.factors.discrete import DiscreteFactor
JointProbabilityDistribution?
#JointProbabilityDistribution
p_IDC = JointProbabilityDistribution(
variables=['I', 'D', 'C'],
cardinality=[2,2,3],
values=[0.126, 0.168, 0.126, 0.126, 0.045, 0.009, 0.0056, 0.0224, 0.252, 0.024, 0.036, 0.06]
)
#print
print(p_IDC)
+------+------+------+------------+
| I | D | C | P(I,D,C) |
+======+======+======+============+
| I(0) | D(0) | C(0) | 0.1260 |
+------+------+------+------------+
| I(0) | D(0) | C(1) | 0.1680 |
+------+------+------+------------+
| I(0) | D(0) | C(2) | 0.1260 |
+------+------+------+------------+
| I(0) | D(1) | C(0) | 0.1260 |
+------+------+------+------------+
| I(0) | D(1) | C(1) | 0.0450 |
+------+------+------+------------+
| I(0) | D(1) | C(2) | 0.0090 |
+------+------+------+------------+
| I(1) | D(0) | C(0) | 0.0056 |
+------+------+------+------------+
| I(1) | D(0) | C(1) | 0.0224 |
+------+------+------+------------+
| I(1) | D(0) | C(2) | 0.2520 |
+------+------+------+------------+
| I(1) | D(1) | C(0) | 0.0240 |
+------+------+------+------------+
| I(1) | D(1) | C(1) | 0.0360 |
+------+------+------+------------+
| I(1) | D(1) | C(2) | 0.0600 |
+------+------+------+------------+
# Verificar que la distribución es válida
p_IDC.values.sum()
np.float64(1.0)
#isinstance
isinstance(p_IDC, DiscreteFactor), isinstance(p_IDC, JointProbabilityDistribution)
(True, True)
Clase |
Qué representa |
Ejemplo |
|---|---|---|
|
Función genérica sobre variables discretas (no necesariamente normalizada) |
\(\phi(X, Y, Z)\) |
|
Caso especial de |
\(P(X, Y, Z)\) |
Toda
JointProbabilityDistributiones unDiscreteFactor, pero no todoDiscreteFactores unaJointProbabilityDistribution.
Operaciones con distribuciones de probabilidad#
¿Qué operaciones podemos llevar a cabo sobre una distribucción?#
1. Reducción
Supongamos que observamos que la calificación final del estudiante es alta, esto es, \(C=c^2\). La operación de reducción consiste en eliminar todas las filas que no son consistentes con la observación:
#p_IDC.reduce?
# Operación de reducción C=c2
p_IDC_reduce_c2 = p_IDC.reduce(values=[('C', 2)], inplace=False)
#print
print(p_IDC_reduce_c2)
+------+------+----------+
| I | D | P(I,D) |
+======+======+==========+
| I(0) | D(0) | 0.1260 |
+------+------+----------+
| I(0) | D(1) | 0.0090 |
+------+------+----------+
| I(1) | D(0) | 0.2520 |
+------+------+----------+
| I(1) | D(1) | 0.0600 |
+------+------+----------+
# Verificar si es una distribución válida
p_IDC_reduce_c2.values.sum()
np.float64(0.447)
Matemáticamente, esta operación equivale a considerar la distribución evaluada
Pregunta. ¿Es este resultado una distribución de probabilidad sobre las variables \(I,D\)?
2. Condición
A partir de la operación de reducción, si queremos obtener una distribución legítima sobre las variables que no reducimos, debemos dividir sobre la suma:
#p_IDC.conditional_distribution?
# Operación de condición sobre C=c2
p_IDC_cond_c2 = p_IDC.conditional_distribution([('C', 2)], inplace=False)
#print
print(p_IDC_cond_c2)
+------+------+----------+
| I | D | P(I,D) |
+======+======+==========+
| I(0) | D(0) | 0.2819 |
+------+------+----------+
| I(0) | D(1) | 0.0201 |
+------+------+----------+
| I(1) | D(0) | 0.5638 |
+------+------+----------+
| I(1) | D(1) | 0.1342 |
+------+------+----------+
# Verificar si es una distribución válida
p_IDC_cond_c2.values.sum()
np.float64(1.0)
Matemáticamente, esta operación equivale a considerar la distribución condicionada \(P(I, D| C=c^2) = P(I, D| c^2)\).
Pregunta. ¿Es este resultado una distribución de probabilidad sobre las variables \(I,D\)?
3. Marginalización
Cuando tenemos una distribución de probabilidad sobre un conjunto de variables y producimos una sobre un subconjunto de las variables originales. Por ejemplo, queremos la distribución marginal sobre \(I, D\):
# Imprimir distribución inicial
print(p_IDC)
+------+------+------+------------+
| I | D | C | P(I,D,C) |
+======+======+======+============+
| I(0) | D(0) | C(0) | 0.1260 |
+------+------+------+------------+
| I(0) | D(0) | C(1) | 0.1680 |
+------+------+------+------------+
| I(0) | D(0) | C(2) | 0.1260 |
+------+------+------+------------+
| I(0) | D(1) | C(0) | 0.1260 |
+------+------+------+------------+
| I(0) | D(1) | C(1) | 0.0450 |
+------+------+------+------------+
| I(0) | D(1) | C(2) | 0.0090 |
+------+------+------+------------+
| I(1) | D(0) | C(0) | 0.0056 |
+------+------+------+------------+
| I(1) | D(0) | C(1) | 0.0224 |
+------+------+------+------------+
| I(1) | D(0) | C(2) | 0.2520 |
+------+------+------+------------+
| I(1) | D(1) | C(0) | 0.0240 |
+------+------+------+------------+
| I(1) | D(1) | C(1) | 0.0360 |
+------+------+------+------------+
| I(1) | D(1) | C(2) | 0.0600 |
+------+------+------+------------+
# Marginalizar I y D para obtener P(C)
p_IDC_marg_ID = p_IDC.marginalize(variables=['I', 'D'], inplace=False)
#print
print(p_IDC_marg_ID)
+------+--------+
| C | P(C) |
+======+========+
| C(0) | 0.2816 |
+------+--------+
| C(1) | 0.2714 |
+------+--------+
| C(2) | 0.4470 |
+------+--------+
# Marginalizar C y D para obtener P(I)
p_IDC_marg_CD = p_IDC.marginalize(variables=['C', 'D'], inplace=False)
#print
print(p_IDC_marg_CD)
+------+--------+
| I | P(I) |
+======+========+
| I(0) | 0.6000 |
+------+--------+
| I(1) | 0.4000 |
+------+--------+
# Marginalizar C e I para obtener P(D)
p_IDC_marg_CI = p_IDC.marginalize(variables=['C', 'I'], inplace=False)
#print
print(p_IDC_marg_CI)
+------+--------+
| D | P(D) |
+======+========+
| D(0) | 0.7000 |
+------+--------+
| D(1) | 0.3000 |
+------+--------+
Matemáticamente, las anteriores operaciones equivalen a:
En abuso de la notación, para no hacer engorrosa la escritura, las anteriores sumas se expresan comúnmente como:
2. Fundamentos de redes bayesianas#
2.1. Modelando independencias#
¿Qué necesitamos hacer para que estos nodos y aristas representen una distribución de probabilidad?
from IPython.display import Image
Image("../images/sesion9-student-model.png", width=700)
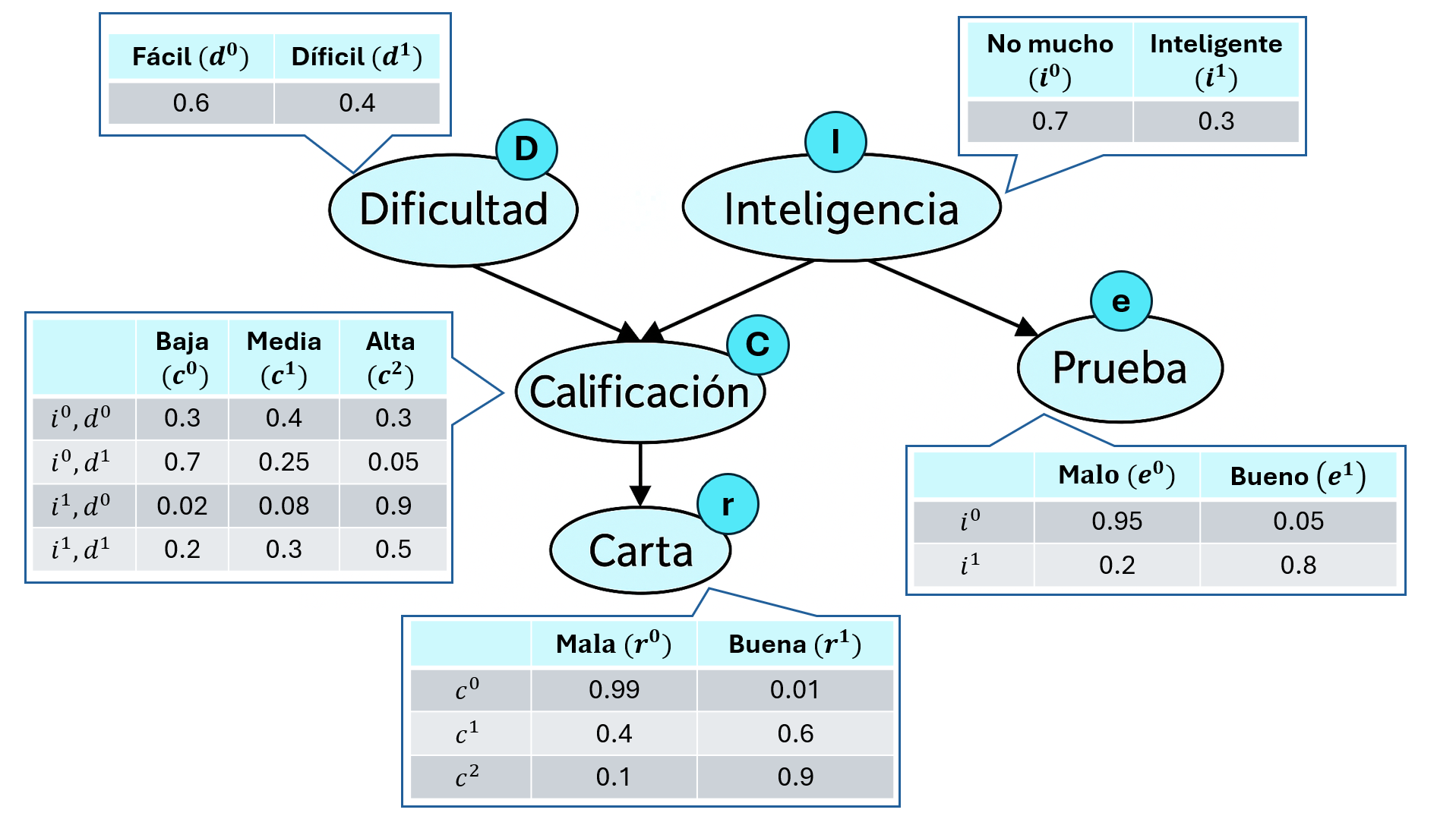
1. Cada nodo tiene su mini tabla de comportamiento (CPD)
Una CPD (Conditional Probability Distribution) describe cómo se comporta una variable dado el estado de sus padres en el grafo.
Por ejemplo:
\(P(D)\) → solo depende de sí misma (no tiene padres).
\(P(I)\) → igual, es independiente.
\(P(C \mid I,D)\) → depende de la inteligencia y la dificultad.
\(P(E \mid I)\) → depende de la inteligencia.
\(P(R \mid C)\) → depende de la calificación.
2. Las CPDs son los ladrillos básicos de la red
Cada nodo de la red tiene su propia CPD -es decir, su propio «bloque de conocimiento local»-.
Si la red tiene \(5\) nodos, entonces hay \(5\) CPDs.
Al unirlas, no tienes una lista infinita de casos posibles, sino pequeñas piezas de información localmente coherentes.
3.¿Cómo se unen todas?
Para obtener la distribución conjunta completa, multiplicamos todas las CPDs entre sí.
💬 Intuitivamente:
Empieza con las causas base (I, D) y ve multiplicando los efectos condicionales según el grafo.
Elemento |
Significado |
Ejemplo |
|---|---|---|
Nodo sin padres |
Distribución simple |
\(P(I)\), \(P(D)\) |
Nodo con padres |
CPD (condicional) |
\(P(C \mid I, D)\) |
Toda la red |
Producto de todas las CPDs |
\(P(I)P(D)P(C \mid I,D)P(E \mid I)P(R \mid C)\) |
Resultado final |
Distribución conjunta completa |
\(P(I,D,C,E,R)\) |
from IPython.display import Image
Image("../images/sesion9-student-model-factors.png", width=700)
💡 Justificación formal: regla de la cadena + independencia
Este producto no es casual: surge directamente de la regla de la cadena de la probabilidad, combinada con las independencias condicionales que nos indica la estructura del grafo.
🔹 1. Aplicamos la regla de la cadena
La regla de la cadena nos dice que cualquier distribución conjunta se puede descomponer como el producto de probabilidades condicionales:
Esto es una identidad matemática, sin asumir ninguna independencia aún.
🔹 2. Aplicamos las independencias locales del grafo
De la estructura del grafo, sabemos que:
\(D\) y \(I\) no tienen padres → \(P(D)\) y \(P(I)\)
\(C\) depende de \(D\) e \(I\) → \(P(C \mid D, I)\)
\(E\) depende solo de \(I\) → \(P(E \mid I)\)
\(R\) depende solo de \(C\) → \(P(R \mid C)\)
Además, \(D\) e \(I\) son independientes entre sí.
🔹 3. Sustituimos las independencias en la regla de la cadena
Comenzamos con la regla general:
Ahora, aplicamos las independencias del grafo:
\(P(I \mid D) = P(I)\) (porque \(I\) y \(D\) son independientes)
\(P(E \mid D, I, C) = P(E \mid I)\) (porque \(E\) solo depende de \(I\))
\(P(R \mid D, I, C, E) = P(R \mid C)\) (porque \(R\) solo depende de \(C\))
🔹 4. Factorización final del modelo
Sustituyendo esas simplificaciones, obtenemos:
🔹 Definición forma de una red bayesiana
Hasta ahora hemos visto las redes bayesianas de forma intuitiva: como grafos donde cada nodo representa una variable y cada flecha una relación de dependencia.
Ahora podemos formalizar esta idea.
Definición
Una red bayesiana es un grafo dirigido acíclico (DAG) \(\mathcal{G}\), donde:
Cada nodo representa una variable aleatoria \(X_i\).
Cada nodo se asocia con una distribución condicional
\(P(X_i \mid Pa_\mathcal{G}(X_i))\), donde \(Pa_\mathcal{G}(X_i)\) son los padres de \(X_i\) en el grafo.Cada arco indica una influencia causal o probabilística directa.
La distribución conjunta sobre todas las variables se obtiene multiplicando todas las distribuciones locales:
De la factorización a las independencias locales#
Independencia local#
Antes de definirla formalmente, dos conceptos del grafo:
Padres de \(X_i\) — los nodos que tienen una arista directa hacia \(X_i\). En el ejemplo, los padres de \(C\) son \(I\) y \(D\).
Descendientes de \(X_i\) — los nodos alcanzables desde \(X_i\) siguiendo las aristas en su dirección. El único descendiente de \(C\) es \(R\).
No descendientes de \(X_i\) — los nodos que no son alcanzables desde \(X_i\) siguiendo las aristas en su dirección. En el ejemplo, los no descendientes de \(C\) son \(I\), \(D\) y \(E\) — todo excepto \(R\), que sí desciende de \(C\).
Con esos conceptos, la independencia local dice:
Es decir: conociendo los padres de \(X_i\), el resto de las variables que no descienden de \(X_i\) no aportan información adicional sobre ella.
Por ejemplo, si ya conocemos \(I\) y \(D\):
\(C\) es independiente de \(E\) — el puntaje del examen no aporta nada sobre la calificación si ya sabemos la inteligencia y la dificultad del curso
\(C\) no es independiente de \(R\) — la carta de recomendación desciende de \(C\), así que sí están relacionadas
Esta propiedad es la que hace posible la factorización: cada CPD \(P(X_i \mid Pa(X_i))\) captura exactamente las dependencias locales de \(X_i\), ignorando el resto del grafo.
Actividad#
Obtener las independencias locales que codifica la red Bayesiana del estudiante.
Comparar el número de parámetros independientes que necesita la red Bayesiana del estudiante contra el número de parámetros que necesitaría la distribución conjunta sin ninguna suposición de independencia.
¿Cómo declarar una red Bayesiana en pgmpy?
from pgmpy.models import BayesianNetwork, DiscreteBayesianNetwork
from pgmpy.factors.discrete import TabularCPD
DiscreteBayesianNetwork?
1. Definimos los arcos del grafo#
#model
student_model = DiscreteBayesianNetwork([('D', 'C'), ('I', 'C'), ('I', 'E'), ('C', 'R')])
2. Definimos las CPDs de cada nodo#
# Definimos distribución condicional de D
cpd_D = TabularCPD(
variable='D',
variable_card=2,
values=[
[0.6],
[0.4]]
)
# Definimos distribución condicional de I
cpd_I = TabularCPD(
variable='I',
variable_card=2,
values=[
[0.7],
[0.3]]
)
#print
print(cpd_I)
+------+-----+
| I(0) | 0.7 |
+------+-----+
| I(1) | 0.3 |
+------+-----+
La representación de las distribuciones condicionales en pgmpy es un poquito distinto a como está en la tabla de arriba. En pgmpy las columnas representan evidencia y las filas los distintos estados de la variable en la distribución condicional:
\(i^0 d^0\) |
\(i^0 d^1\) |
\(i^1 d^0\) |
\(i^1 d^1\) |
|
|---|---|---|---|---|
\(c^0\) |
0.3 |
0.7 |
0.02 |
0.2 |
\(c^1\) |
0.4 |
0.25 |
0.08 |
0.3 |
\(c^2\) |
0.3 |
0.05 |
0.9 |
0.5 |
# Definimos distribución condicional de C
cpd_C = TabularCPD(
variable='C',
variable_card=3,
values=[
[0.30, 0.70, 0.02, 0.20],
[0.40, 0.25, 0.08, 0.30],
[0.30, 0.05, 0.90, 0.50]
],
evidence=['I', 'D'], #<--- ojo aquí: los padres de C son I y D
evidence_card=[2, 2] #<--- ojo aquí: las cardinalidades de I y D son 2 y 2 respectivamente
)
# Definimos distribución condicional de E
cpd_E = TabularCPD(
variable='E',
variable_card=2,
values=[
[0.95, 0.20],
[0.05, 0.80]
],
evidence=['I'],
evidence_card=[2]
)
# Definimos distribución condicional de R
cpd_R = TabularCPD(
variable='R',
variable_card=2,
values=[
[0.99, 0.40, 0.10],
[0.01, 0.60, 0.90]
],
evidence=['C'],
evidence_card=[3]
)
#print
print(cpd_R)
+------+------+------+------+
| C | C(0) | C(1) | C(2) |
+------+------+------+------+
| R(0) | 0.99 | 0.4 | 0.1 |
+------+------+------+------+
| R(1) | 0.01 | 0.6 | 0.9 |
+------+------+------+------+
3. Añadimos las CPDs a la red y verificamos el modelo#
student_model.add_cpds?
# Asociamos las distribuciones condicionales a la red
student_model.add_cpds(cpd_D, cpd_I, cpd_C, cpd_E, cpd_R)
4. Verificar que el modelo es válido#
#check
student_model.check_model()
True
#check
help(student_model.check_model)
Help on method check_model in module pgmpy.models.DiscreteBayesianNetwork:
check_model() -> 'bool' method of pgmpy.models.DiscreteBayesianNetwork.DiscreteBayesianNetwork instance
Check the model for various errors. This method checks for the following
errors.
* Checks if the sum of the probabilities for each state is equal to 1 (tol=0.01).
* Checks if the CPDs associated with nodes are consistent with their parents.
Returns
-------
check: boolean
True if all the checks pass otherwise should throw an error.
Independencias locales#
Una vez tenemos el modelo, podemos hacer varias cosas con él. Entre ellas, podemos verificar las independencias locales que codifica el modelo:
student_model.local_independencies?
Cada nodo es independiente de sus no descendientes, dados sus padres.
Nodo |
Padres (condición) |
Descendientes |
No descendientes |
Independencia local |
Factor que aporta |
Parámetros |
|---|---|---|---|---|---|---|
D (Dificultad) |
— |
C, R |
I, E |
\(D \perp \{I, E\}\) |
\(P(D)\) |
1 |
I (Inteligencia) |
— |
C, R, E |
D |
\(I \perp D\) |
\(P(I)\) |
1 |
C (Calificación) |
D, I |
R |
E |
\(C \perp E \mid D, I\) |
\(P(C \mid D, I)\) |
8 |
E (Prueba) |
I |
— |
D, C, R |
\(E \perp \{D, C, R\} \mid I\) |
\(P(E \mid I)\) |
2 |
R (Carta) |
C |
— |
D, I, E |
\(R \perp \{D, I, E\} \mid C\) |
\(P(R \mid C)\) |
3 |
# La variable D es independiente de I y de E.
student_model.local_independencies('D')
(D ⟂ E, I)
student_model.local_independencies('C')
(C ⟂ E | D, I)
student_model.local_independencies(['D', 'I', 'C', 'E', 'R'])
(C ⟂ E | D, I)
(D ⟂ E, I)
(E ⟂ C, D, R | I)
(I ⟂ D)
(R ⟂ D, E, I | C)