Sesión 4#
Estimadores de máxima verosimilitud#
Conceptos clave de la sesión 4.#
Objetivos de la sesión:
Comprender el principio de máxima verosimilitud a través de ejemplos básicos.
Estimar los parámetros de algunas distribuciones comunes usando el principio de máxima verosimilitud.
Entender las limitaciones básicas de los estimadores de máxima verosimilitud.
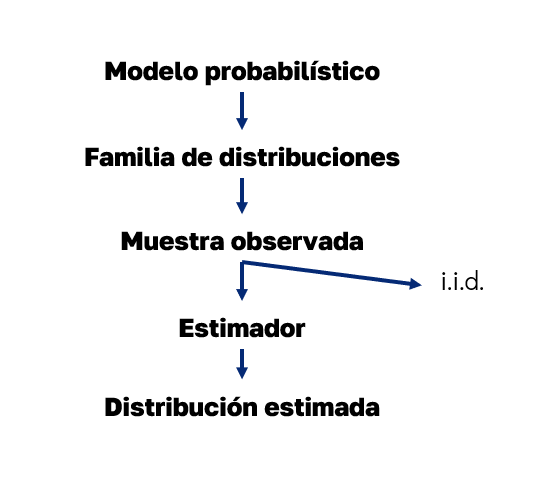
Modelos probabilísticos#
Un modelo probabilístico es una especificación de la distribución conjunta de las variables aleatorias involucradas en el problema, condicionada (o no) por un conjunto de párametros desconocidos.
Donde:
\(X_1, \dots, X_n\) son las variables aleatorias (datos observados).
\(\theta \in \Theta\) es el vector de parámetros desconocidos.
Muy comunmente mi modelo dependerá de parámetros desconocidos.
Veamos brevemente la diferencia entre parámetros e hiperparámetros:
Parámetros |
Hiperparámetros |
|
|---|---|---|
Definición |
Valores internos aprendidos automáticamente por el modelo durante el entrenamiento. |
Valores externos definidos antes del entrenamiento que controlan el proceso de aprendizaje. |
Ejemplos |
Pesos, sesgos, coeficientes de una red neuronal, vectores de embeddings. |
Tasa de aprendizaje, número de épocas, número de capas, tamaño del batch, regularización. |
Características |
Se ajustan iterativamente con el algoritmo de optimización (ej. descenso de gradiente). |
Se eligen manualmente o con técnicas de optimización de hiperparámetros (grid search u otros). |
Ahora que entendemos la diferencia entre parámetros y hiperparámetros, podemos volver al corazón del modelo probabilístico. Para ello, retomaremos algunos conceptos básicos de la teoría de probabilidad y los conectaremos con el principio de máxima verosimilitud.
¿Por qué necesitamos distribuciones de probabilidad?#
Cuando observamos datos del mundo real, rara vez son idénticos: siempre existe variabilidad. Esa variabilidad refleja la incertidumbre inherente al proceso que generó los datos.
Para poder construir un modelo que explique cómo se producen esos datos, necesitamos suponer una estructura probabilística que capture esa incertidumbre.
Aquí es donde entran en juego las distribuciones de probabilidad:
Nos permiten representar matemáticamente la incertidumbre presente en los datos.
Sirven para formalizar nuestras suposiciones sobre cómo se comporta el proceso generador de los datos.
Necesitamos una distribución de probabilidad
Para describir cómo se comportan los datos.
Esa distribución refleja nuestras hipótesis de comportamiento sobre el fenómeno (por ejemplo, normal, binomial, exponencial, etc.).
Elegir la forma de la distribución es un supuesto
La persona quién construye el modelo decide qué distribución usar.
Esto es una hipótesis de modelado y puede ser correcta, aproximada o equivocada.
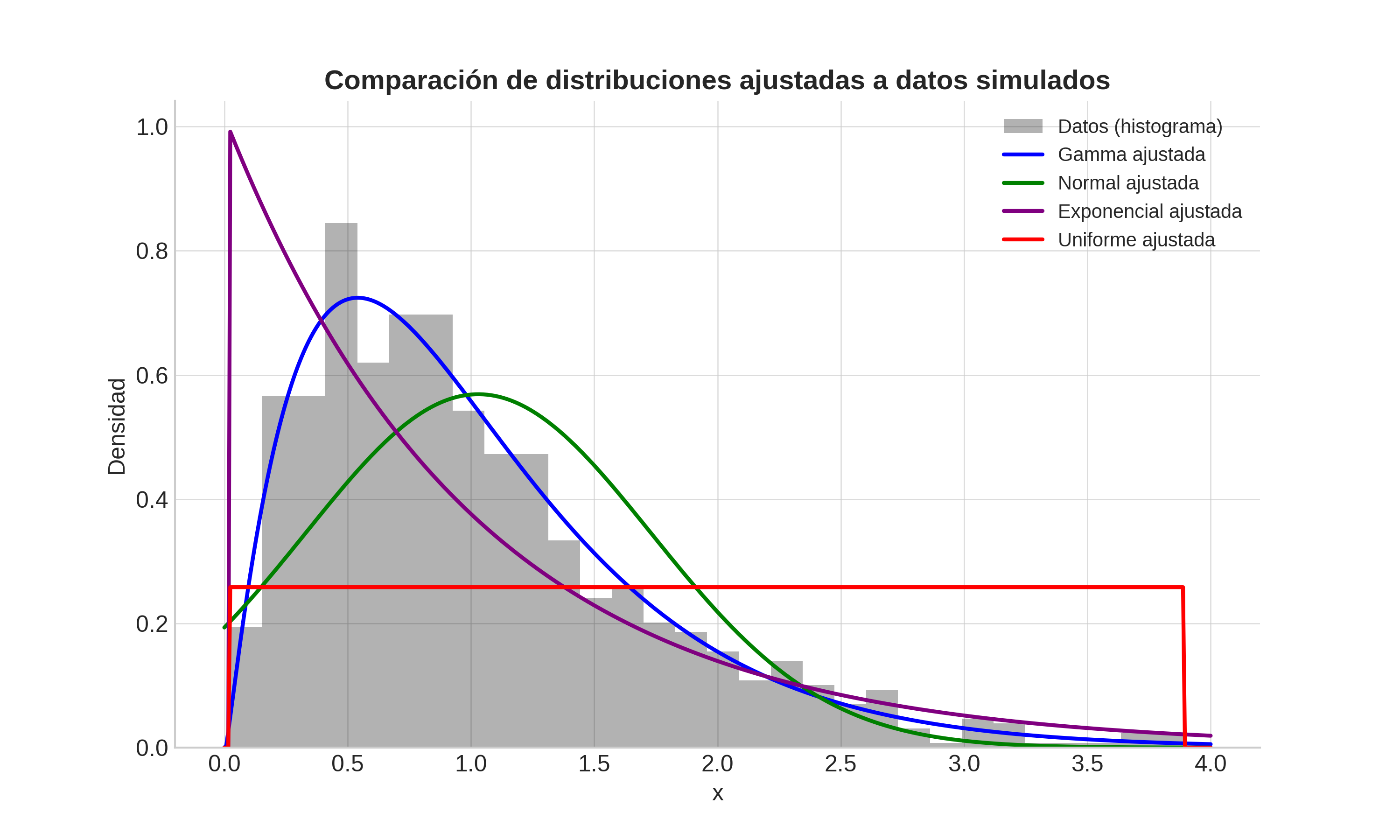
Comparación de distribuciones ajustadas a los datos.#
Distribuciones tienen parámetros
Cada familia de distribuciones está definida por parámetros desconocidos:
Normal → media \(\mu\) y varianza \(\sigma^2\).
Poisson → tasa \(\lambda\).
Bernoulli → probabilidad de éxito \(p\).
Al no conocerlos, tratamos de estimarlos a partir de datos (máxima verosimilitud, métodos bayesianos, etc.).
Parámetros conocidos
Los parámetros son desconocidos en la mayoría de los casos, pero se pueden considerar conocidos cuando:
Los fijamos en un modelo o simulación.
La teoría/experimento nos da su valor exacto.
Los tratamos como supuestos para simplificar.
Familia de distribuciones posibles
Antes de ver los datos, no sabemos qué valores toman los parámetros.
Así, realmente no hablamos de “una sola distribución”, sino de una familia de distribuciones parametrizadas.
El trabajo de la estadística/inferencia es reducir la incertidumbre sobre los parámetros → elegir la distribución concreta que mejor describe el comportamiento de los datos.
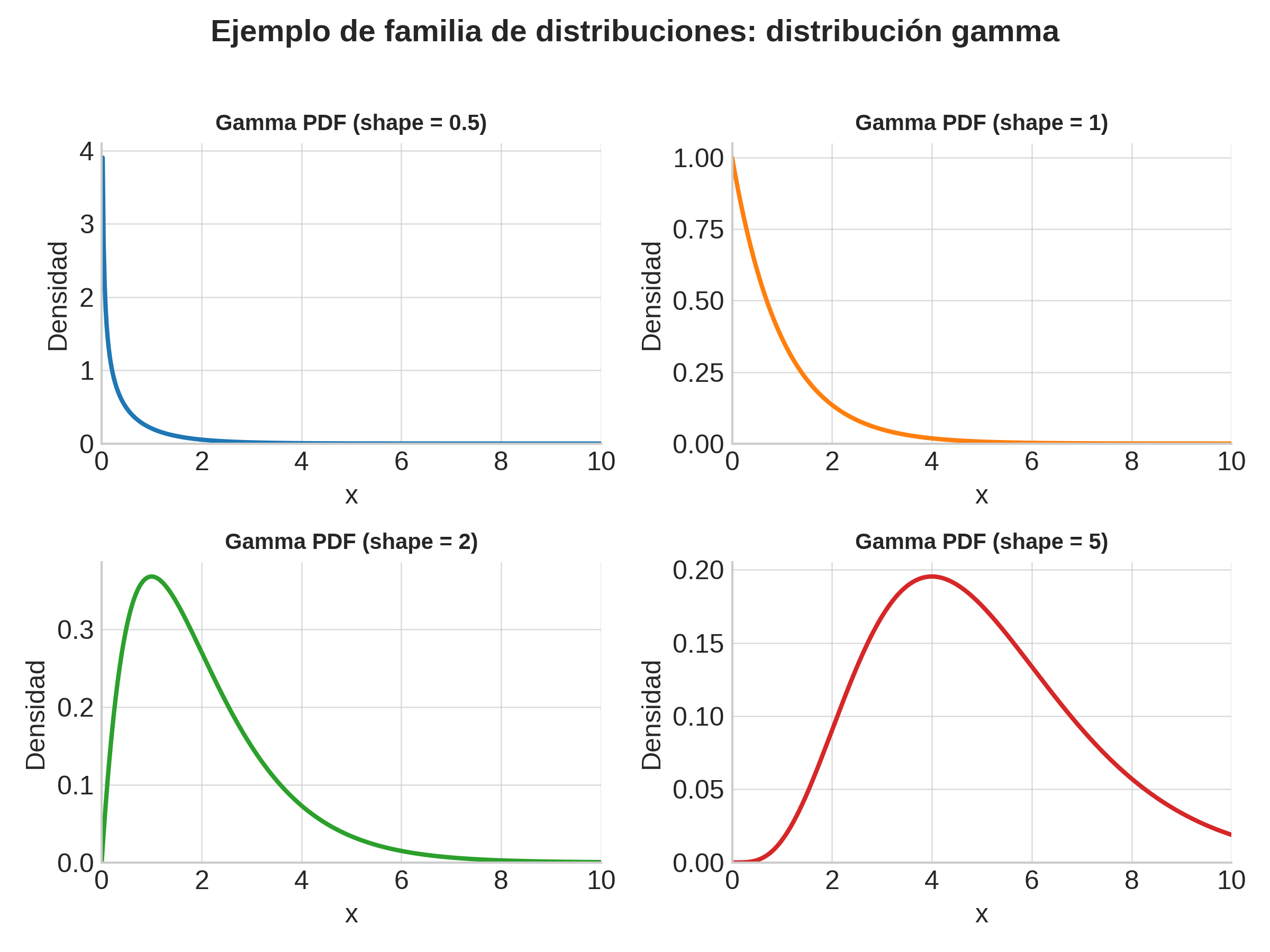
Familia de distribuciones Gamma.#
En suma, tu modelo probabilístico empieza como una familia de distribuciones parametrizadas.
La elección de la familia es un supuesto tuyo.
Los parámetros son desconocidos y deben ser estimados o aprendidos.
Métodos de estimación o inferencia#
(a) La estimación por máxima verosimilitud (Maximum likelihood estimation)#
Estima los parámetros \(\theta\) de un modelo probabilístico.
La idea básica es elegir los parámetros que maximizan la función de verosimilitud.
Intuitivamente, esto corresponde a elegir los parámetros que maximizan la probabilidad de los datos obsevados.
Inevitablemente comenzamos a hablar, entonces, de estadística… específicamente de inferencia estadística: Cuando tenemos datos observados y sacamos conclusiones a partir de los datos.
Ejercicio: Máxima verosimilitud para distribuciones discretas#
De clases pasadas, sabemos que el experimento de tirar la moneda \(n\) veces y contar el número de caras, sigue una distribución \(\text{Binomial}(n,\theta)\), con PMF:
donde \(a\) es el número de caras.
En un ejemplo concreto, supongamos que se tiró la moneda 100 veces y contamos 55 caras. Por tanto, sabemos que
Observamos que la probabilidad de obtener 55 caras depende del valor de \(\theta\), por lo que es usual incluir esto con la notación de probabilidad condicional:
Lo anterior, lo podemos leer como: «la probabilidad de obtener 55 caras dado que la probabilidad de cara en un tiro individual es \(\theta\)».
Algunos términos convencionales que usamos en estadística:
Experimento: Tirar la moneda 100 veces y contar el número de caras.
Datos: Los datos son el resultado del experimento. En este caso son las 55 caras.
Parámetros de interés: Estamos interesados en conocer el valor del parámetro \(\theta\).
Función de verosimilitud: Es la función \(p(datos | parámetros)\). Notemos que es una función tanto de los datos, como de los parámetros. En nuestro caso es $\( p(55 | \theta) = \left(\begin{array}{c}100 \\ 55\end{array}\right) \theta^{55}(1 - \theta)^{45}. \)$
Descubrir
Haciendo uso del cálculo, obtenemos lo siguiente:
Igualando a cero:
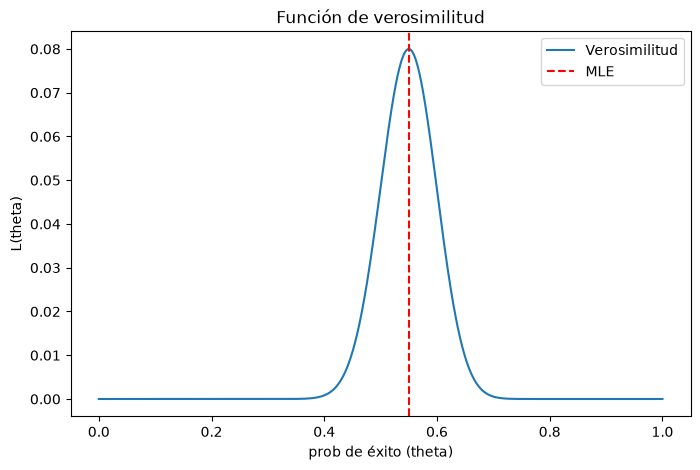
Por lo que el MLE es \(\hat{\theta} = \frac{55}{100}\).
En los extremos (\(\theta=0\) o \(\theta=1\)), la verosimilitud es nula, por lo que \(\hat{\theta}=0.55\) es el único máximo en \([0,1]\).
import numpy as np
from matplotlib import pyplot as plt
import math
import warnings
warnings.filterwarnings('ignore')
# Calculemos la función de verosimilitud con los datos del ejemplo
n = 100
a = 55
theta = np.linspace(0,1, 1001)
# Función de verosimilitud (evaluada)
L = math.comb(n,a) * theta**a * (1-theta)**(n-a)
# L --> es un vector de verosimilitudes para cada posible valor de theta
L
array([0.00000000e+000, 5.87432611e-137, 2.02318316e-120, ...,
1.93660326e-093, 5.81584649e-107, 0.00000000e+000], shape=(1001,))
np.argmax(L)
np.int64(550)
theta[550]
np.float64(0.55)
# Aproximar el valor máximo de la verosimilitud
theta_mle1 = theta[np.argmax(L)]
theta_mle1
np.float64(0.55)
# Grafiquemos la función de verosimilitud
plt.figure(figsize=(8,5))
plt.plot(theta,
L,
label='Verosimilitud')
plt.axvline(x=theta_mle1, color='red', linestyle='--', label='MLE')
plt.title('Función de verosimilitud')
plt.xlabel('prob de éxito (theta)')
plt.ylabel('L(theta)')
plt.legend()
plt.show()
¿qué pasa en el caso en donde se aumente la cantidad de muestras?
# de nuevo, pero con más datos:
n_ = 1000
a_ = 550
theta_ = np.linspace(0,1, 10001)
L_ = math.comb(n_,a_) * theta_**a_ * (1-theta_)**(n_-a_)
# Aproximar el valor máximo de la verosimilitud
theta_mle2 = theta_[np.argmax(L_)]
theta_mle2
np.float64(0.55)
# Graficamos las funcines de verosimilitud
plt.subplot(2,1,1)
plt.plot(theta, L, label='n=100')
plt.axvline(x=theta_mle1, color='red', linestyle='--', label='MLE')
plt.xlabel('theta')
plt.ylabel('L(theta)')
plt.title('Función de verosimilitud (n=100)')
plt.legend()
plt.subplot(2,1,2)
plt.plot(theta_, L_, label='n=1000')
plt.axvline(x=theta_mle2, color='red', linestyle='--', label='MLE')
plt.xlabel('theta')
plt.ylabel('L(theta)')
plt.title('Función de verosimilitud (n=1000)')
plt.legend()
<matplotlib.legend.Legend at 0x72ab0a060190>
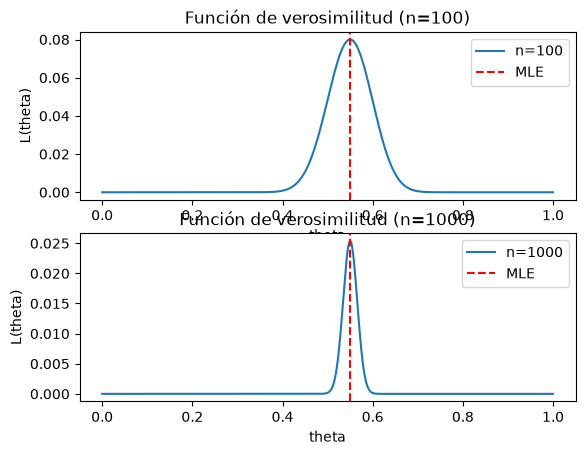
Aunque el MLE en ambos casos es el mismo, porque
observamos que la dispersión de la función de verosimilitud alrededor del máximo en el caso de más tiros es menor.
¿En cuál de los dos valores estimados \(\hat{\theta}\) confías más?
Muestra observada#
Se denota por \(\mathcal{D} = \{x_1, x_2, \dots, x_n\}\) o como \(\mathcal{X}\). Es el conjunto de datos observados.
Supuesto i.i.d.#
Cuando trabajamos con una muestra \(X_1, \dots, X_n\), comúnmente asumimos que los datos son:
Independientes: El conocimiento de un valor no da información sobre otro.
Idénticamente distribuidos: Todos siguen la misma distribución \(f(x; \theta)\)
Esto se denota como:
Estas suposiciones de independencia lo que hacen es que los resultados del experimento se puedan multiplicar y esto, entonces es válido en cualquier contexto donde supongamos independencia de los resultados del experimento. Esto permite factorizarla como:
Donde:
\(L(\theta)\) es la función de verosimilitud
\(x_i\) son las observaciones de la muestra
\(\theta\) es el parámetro del modelo
Con la suposición de que los datos son independientes e idénticamente distribuidos (i.i.d.), trae como consecuencia que la función de verosimilitud sea un producto de las verosimilitudes individuales de los datos. Ahora, dado que estamos interesad@s en maximizar la verosimilitud, hay que tener en cuenta que maximizar productos de funciones puede tornarse bastante complejo.
Log-verosimilitud#
Es en este punto donde nos podemos dar cuenta que la función \(\log\) (logaritmo natural o logaritmo en base \(e\)) puede ser de gran ayuda, dado que convierte productos en sumas.
Usualmente, después de establecer la multiplicatoria de la verosimilitud, se aplica el logaritmo natural para simplificar el cálculo.
Esto transforma productos en sumas y hace más manejable el trabajo analítico:
A esta función se le conoce como log-verosimilitud.
El logaritmo es estrictamente creciente en \((0, \infty)\)
Esto significa que:
Es decir, el logaritmo preserva el orden de los valores positivos.
Ejemplo:
En consecuencia, el valor de \(\theta\) que maximiza la verosimilitud \(L(\theta)\) es el mismo que maximiza la log-verosimilitud \(\ell(\theta)\).
Ejemplo. Retomando el caso de la moneda, tenemos que la log-verosimilitud es:
Ahora, para maximizar la log-verosimilitud:
Descubrir
Igualando a cero:
Por lo que el MLE es \(\hat{\theta} = \frac{55}{100}\)
Veamos como luce la función de log-verosimilitud en este caso y comparémosla con la función de verosimilitud:
# Función de log-verosimilitud
log_likelihood = np.log(float(math.comb(n,a))) + a* np.log(theta) + (n-a) * np.log(1- theta)
# Aproximar el valor máximo de la verosimilitud
theta[np.argmax(log_likelihood)]
np.float64(0.55)
# Graficamos las funciones de log-verosimilitud y verosimilitud
plt.subplot(2,1,1)
plt.plot(theta,
L,
label='Verosimilitud')
plt.axvline(x=theta[np.argmax(L)], color='red', linestyle='--')
plt.xlabel('theta')
plt.ylabel('L(theta)')
plt.legend()
plt.grid()
plt.subplot(2,1,2)
plt.plot(theta,
log_likelihood,
label='Log-Verosimilitud')
plt.axvline(x=theta[np.argmax(log_likelihood)], color='red', linestyle='--')
plt.xlabel('theta')
plt.ylabel('L(theta)')
plt.legend()
plt.grid()
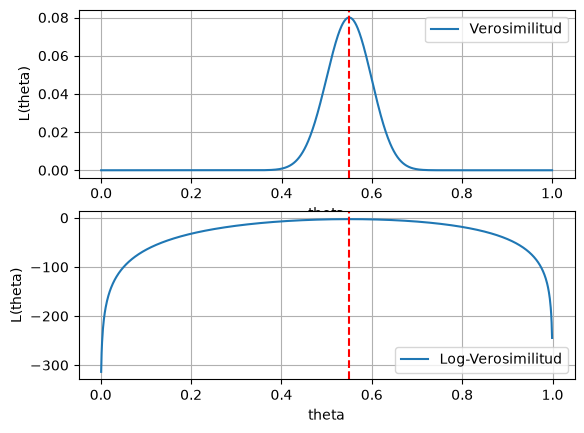
Ejercicio: Máxima verosimilitud para distribuciones continuas#
Todo aplica a distribuciones continuas
En el caso que acabamos de analizar teníamos una distribución discreta \(\text{Binomial}\), y obtuvimos la función de verosimilitud usando la PMF. Para distribuciones continuas, todo lo que vimos es completamente aplicable, solo que usaremos la PDF.
Suponemos que el tiempo de vida de los bombillos es modelado por una distribución exponencial con parámetro desconocido \(\lambda\). Probamos 5 bombillos, y observamos que tienen tiempos de vida de 2, 3, 1, 3, y 4 años, respectivamente. ¿Cuál es el MLE para \(\lambda\)?
Distribución exponencial:
Descubrir
Asumiendo i.i.d., tenemos que la densidad conjunta es:
Ahora, viendo los datos como fijos, con \(x_1=2\), \(x_2=3\), \(x_3=1\), \(x_4=3\), y \(x_5=4\), y \(\lambda\) como variable, obtenemos la función de verosimilitud:
y la log-verosimilitud:
Finalmente, usamos cálculo para encontrar el MLE:
Igualando a cero y despejando, obtenemos que el MLE es \(\hat{\lambda} = \frac{5}{13}\).
Descubrir
Una vez hallado \(\hat{\lambda} = \frac{5}{13}\), podemos construir la distribución estimada:
En términos sencillos
Antes tenías una familia de distribuciones exponenciales, una para cada posible valor de \(\lambda\).
Ahora tienes una única distribución estimada con \(\hat{\lambda} = \frac{5}{13}\).
¿Qué se puede hacer con esta distribución estimada?
Con:
puedes:
Calcular probabilidades, por ejemplo:
\[ P(X < 2) = \int_0^2 f(x; \hat{\lambda})\, dx \]
Veamos ahora un ejemplo práctico que muestra cómo el estimador de máxima verosimilitud (MLE) puede utilizarse para resolver un problema de probabilidad.
Partimos del modelo exponencial ajustado con \(\hat{\lambda} = \tfrac{5}{13}\) y queremos calcular la probabilidad de que un bombillo dure menos de 2 años:
import sympy as sp
x = sp.Symbol('x', positive=True)
lambda_ = 5/13
# PDF
f = lambda_ * sp.exp(-lambda_ * x)
# Integral
P = sp.integrate(f , (x, 0, 2))
P_eval = float(P)
P_eval
0.5366306307688247
Suposición: Los tiempos de vida de los bombillos siguen una Exponencial(\(\lambda\)).
Datos observados: \(2, 3, 1, 3, 4\).
Con MLE obtuvimos que el parámetro es
Entonces, nuestro modelo estimado es:
El cálculo fue:
Según el modelo exponencial estimado, la probabilidad de que un bombillo dure menos de 2 años es aproximadamente 53.7%.
Es decir, más de la mitad de los bombillos producidos bajo este modelo fallarían antes de los 2 años.
Ejercicio: Máxima verosimilitud con más de un parámetro#
En este caso tenemos:
Variable aleatoria \(X \sim \mathcal{N}(\mu, \sigma^2)\)
\(p(x | \mu,\sigma^2)=\frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)\)
Los estimadores de máxima verosimilitud de \(\mu\) y \(\sigma\) son:
# Númericamente:
from scipy import stats
# Parámetros reales de la dist. normal
mu_true = 10
sigma_true = 2
X = stats.norm(loc=mu_true, scale=sigma_true)
# Generamos muestras
n_samples = 100000
samples = X.rvs(size=n_samples)
# Parámetros de máxima versimilitud
import numpy as np
mu_mle = np.mean(samples)
sigma_mle = np.sqrt(np.mean((samples - mu_mle)**2))
# Comparamos los parámetros reales con los de máxima verosimilitud
mu_true, mu_mle
(10, np.float64(10.002159302827712))
sigma_true, sigma_mle
(2, np.float64(1.9945365821247867))
# Forma más sencilla:
#from scipy.stats import norm
Comentarios finales#
El principio de máxima verosimilitud es bastante poderoso, y además una técnica general para estimar los parámetros de un modelo probabilístico.
Overfitting
Sin embargo, tiene un problema: en caso de tener pocos datos de entrenamiento, podemos sobreajustar seriamente el modelo.
Suposición básica
El principio de máxima verosimilitud es bastante intuitivo: estimar los parámetros de manera que se maximice la probabilidad de los datos. Esto trae consigo la suposición subyacente de que los parámetros son fijos, de manera que la incertidumbre proviene de los datos.
Extra#
Refresh de matemáticas detrás del MLE#
Aquí la clave, es la palabara «maximizar». Queremos encontrar el valor de \(\theta\) que maximiza la función de verosimilitud \(L(\theta)\).
Así que vamos a tener distintas partes importantes en el proceso para llegar a ese valor óptimo:
Ya sabemos que si asumimos que los datos son i.i.d.:
Entonces la función de verosimilitud es:
La log-verosimilitud es:
Usualmente se trabaja con el logaritmo de la verosimilitud para facilitar el cálculo:
¿Por qué usar la log-verosimilitud?
Transformar productos \(\prod\) en sumas \(\sum\) simplifica el cálculo.
Hace más manejable la derivación, especialmente con distribuciones exponenciales.
Conserva la ubicación del máximo porque \(\log(\cdot)\) es monótona creciente.
Encontrar el máximo:
a. Derivar la log-verosimilitud respecto del parámetro \(\theta\)
b. Igualar a cero
c. Resolver para \(\theta\)
d. \(\hat{\theta} = \arg\max_{\theta} \ell(\theta)\)
Recuerda
Si el modelo tiene un solo parámetro, se usa cálculo diferencial convencional:
Si el modelo tiene dos o más parámetros:
Se utilizan derivadas parciales, una por cada parámetro:
Verificar que es un máximo:
a. Calcular la segunda derivada (o matriz Hessiana si hay varios parámetros).
b. Dado que tenemos un problema en un dominio cerrado \(0 \leq \theta \leq 1\), podemos evaluar en los extremos:
y en el punto crítico: \(\hat{\theta}\).