Sesión 6 B#
Actualización bayesiana continua#
Objetivos:
Comprender una familia de distributiones parametrizadas que representa un rango continuo de hipótesis para los datos observados.
Aplicar el teorema de Bayes para actualizar la densidad de probabilidad dados los datos y una distribución posterior.
Interpretar y usar probabilidades predictivas posteriores.
1. De hipótesis discretas a parámetros continuos#
En los ejemplos anteriores trabajamos con un modelo discreto:
Teníamos un conjunto finito de hipótesis: la moneda podía ser de tipo A, B o C, cada una con su probabilidad previa.
La distribución \(p(\theta)\) representaba esa creencia inicial sobre cuál hipótesis era verdadera.
En ese escenario, el razonamiento bayesiano consistía en:
Asignar probabilidades a las hipótesis (previas).
Observar datos (por ejemplo, caras al lanzar la moneda).
Actualizar esas probabilidades mediante Bayes, obteniendo una posterior discreta sobre el conjunto de hipótesis.
Ahora pasamos a un escenario distinto: el caso continuo.
Ya no pensamos en un número finito de hipótesis, sino en un parámetro desconocido \(\theta\).
Por ejemplo, \(\theta\) puede ser la probabilidad de obtener cara al lanzar una moneda.
Como no sabemos su valor exacto, suponemos que \(\theta\) puede tomar infinitos valores en el intervalo \([0,1]\).
En este caso:
La verosimilitud sigue siendo discreta (los datos son lanzamientos: cara o cruz, modelados por una Bernoulli).
Pero la distribución previa sobre \(\theta\) es ahora una distribución continua.
Así, el proceso bayesiano cambia de «asignar probabilidades a hipótesis finitas» a «asignar densidades de probabilidad a un espacio continuo de posibles valores para el parámetro».
En resumen:
Caso discreto: \(p(\theta)\) representa probabilidades sobre un conjunto finito de > hipótesis (tipos de monedas).
Caso continuo: \(p(\theta)\) es una densidad sobre todos los valores posibles del > parámetro \(\theta\).
2. Justificación de usar \(\theta\) continua#
El enfoque continuo es más realista en muchos contextos, porque en la práctica no sabemos de antemano cuáles son los valores posibles de la probabilidad de cara.
En lugar de restringirnos a 3 hipótesis, admitimos que la probabilidad de cara \(\theta\) puede ser cualquier número real en \([0,1]\).
Así, el modelo nos permite aprender directamente la probabilidad de éxito en vez de solo elegir entre hipótesis predefinidas.
3. Previas continuas, verosimilitudes discretas#
Dos niveles en el modelo bayesiano
Cuando aplicamos Bayes, siempre jugamos en dos niveles distintos de incertidumbre:
Nivel de los datos (observaciones):
En el ejemplo de la moneda, los datos provienen de una Bernoulli, es decir, \(X \in {0,1}\).
Esto significa que la verosimilitud (la probabilidad de observar los datos dados los parámetros) \(p(x|\theta)\) es discreta.
Nivel del parámetro desconocido \(\theta\):
Aquí, \(\theta\) es la probabilidad de éxito (caer cara).
No conocemos \(\theta\), pero asumimos que puede tomar infinitos valores en [0,1].
Como no sabemos cuál es \(\theta\), lo tratamos como una variable aleatoria continua con su propia distribución: la distribución previa (prior) \(p(\theta)\).
Nota
Recuerda que el parámetro o los parámetros de una distribución siempre son los mismos para cada distribución.
Lo que cambia es cómo estimamos según el enfoque:
Ejemplo#
Supongamos que tenemos una moneda con probabilidad desconocida \(\theta\) de caer en cara. El valor de \(\theta\) es aleatorio y podría ser cualquier valor entre 0 y 1.
Prior#
Para modelar nuestra incertidumbre sobre \(\theta\), asumimos que:
para \(0 \leq \theta \leq 1\)
Nuestra creencia previa (prior) sobre \(\theta\) no es uniforme.
Estamos diciendo que, antes de ver los datos, creemos que valores grandes de \(\theta\) (más cercanos a 1) son más probables que valores pequeños (más cercanos a 0).
Es una pdf válida porque:
\[ \int_0^1 2\theta d\theta = 1\]
Observa lo interesante:
La previa es continua (porque \(\theta\) puede variar en infinitos valores).
La verosimilitud es discreta (porque los datos son 0 o 1).
Verosimilitud#
Tenemos una verosimilitud discreta dado que tirar una moneda solo tiene dos posibles resultados:
Enfoque bayesiano#
Si:
Normalizamos diviendo por la probailidad total
En este caso, la ley de probabilidad total la escribimos como: $\(p(x) = \int_{-\infty}^{\infty} p(x | \theta) p(\theta) \text{d}\theta\)$
Ejemplo 1: una sola observación (cara)#
Supongamos que tiramos la moneda una vez y obtenemos cara (\(x=1\)).
verosimilitud:
previa:
numerador de Bayes:
probabilidad total:
Con esta probabilidad total ya podemos calcular la posterior, normalizando el numerador de Bayes:
posterior:
Cálculo simbólico con sympy#
import sympy as sp
theta = sp.symbols('theta')
prior = 2*theta
likelihood = theta
# evidencia/total
p_evidencia = sp.integrate(likelihood * prior, (theta, 0, 1))
print(f'evidencia p(x=1) = {p_evidencia}')
# posterior
posterior = (likelihood * prior) / p_evidencia
posterior_simpl = sp.simplify(posterior)
print(f'posterior p(theta|x=1) = {posterior_simpl}')
evidencia p(x=1) = 2/3
posterior p(theta|x=1) = 3*theta**2
Cálculo numérico con numpy#
import numpy as np
import matplotlib.pyplot as plt
theta = np.linspace(0, 1, 200)
prior_vals = 2*theta
likelihood_vals = theta
p_x = 2/3
posterior_vals = (likelihood_vals * prior_vals) / p_x
# Graficamos
plt.plot(theta, prior_vals, label=r'Previa $p(\theta)=2\theta$')
plt.plot(theta, posterior_vals, color='red', label=r'Posterior $p(\theta|x=1)=3\theta^2$')
plt.xlabel(r'$\theta$')
plt.ylabel("Densidad")
plt.title("Actualización Bayesiana: previa y posterior")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
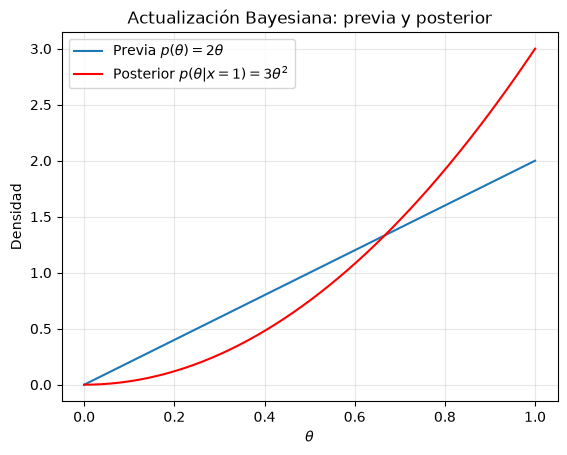
Nota. Precisamente la ley de probabilidad total será, en general, bastante compleja de calcular en la mayoría de los casos, por lo que luego nos decantaremos por métodos numéricos para aproximar la distribución posterior.
Ejemplo 2: (varios datos)#
Supongamos que observamos en tres tiros de la moneda, la secuencia cara-cara-sello.
Calculemos la pdf posterior para \(\theta\):
Cálculo simbólico con sympy#
Previa:
theta = sp.symbols('theta')
prior = 2*theta
prior
Verosimilitud de la secuencia cara-cara-sello (1,1,0):
likelihood = theta*theta*(1-theta)
likelihood
Numerador de Bayes (previa * verosimilitud):
numerador = likelihood * prior
numerador
Probabilidad total (evidencia) - normalización:
p_evidencia = sp.integrate(numerador, (theta, 0, 1))
p_evidencia
Posterior:
posterior_expr = numerador / p_evidencia
posterior_expr_simpl = sp.simplify(posterior_expr)
posterior_expr_simpl
Cálculo numérico con numpy#
import numpy as np
theta = np.linspace(0, 1, 1001)
prior_density = 2* theta
likelihood_vals = theta**2 * (1-theta)
unnormalized_posterior = likelihood_vals * prior_density
evidencia = np.trapezoid(unnormalized_posterior, theta)
posterior_density = unnormalized_posterior / evidencia
area_posterior = np.trapezoid(posterior_density, theta)
evidencia, area_posterior
(np.float64(0.0999998333334), np.float64(1.0))
# Graficar previa y posterior
from matplotlib import pyplot as plt
plt.figure(figsize=(7,5))
plt.plot(theta, prior_density, label=r'Previa $2\theta$')
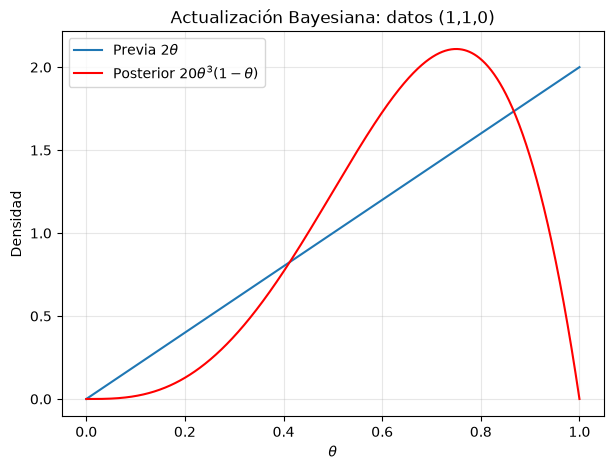
plt.plot(theta, posterior_density, color='red', label=r'Posterior $20\theta^3(1-\theta)$')
plt.xlabel(r'$\theta$'); plt.ylabel('Densidad')
plt.title('Actualización Bayesiana: datos (1,1,0)')
plt.legend(); plt.grid(alpha=0.3)
plt.show()
Ahora que tenemos todos los ingredientes, escribimos nuestra tabla de actualziación Bayesiana, teniendo en mente que:
No podemos enumerar una fila para cada hipótesis. Solo escribimos una.
Hipótesis |
Rango |
Previa |
Verosimilitud |
Numerador de Bayes |
Posterior |
|---|---|---|---|---|---|
\(\theta\) |
rango \(\theta\) |
\(p(\theta)\) |
\(p(x = 1, 1, 0 | \theta)\) |
\(p(x = 1, 1, 0 | \theta)p(\theta)\) |
\(p(\theta | x = 1, 1, 0)\) |
\(\theta\) |
[0, 1] |
\(2 \theta\) |
\(\theta^2(1-\theta)\) |
\(2 \theta^3 (1-\theta)\) |
\(20 \theta^3 (1-\theta)\) |
total |
[0, 1] |
\(\int_{0}^{1} 2 \theta \text{d}\theta = 1\) |
NO SUMA |
\(\int_{0}^{1} 2 \theta^3 (1-\theta) \text{d}\theta = 1/10\) |
\(1\) |
# Graficar numerador y posterior
plt.figure(figsize=(8,6))
plt.subplot(2, 1, 1)
plt.plot(theta, posterior_density, label=r'Posterior $p(\theta|x=1,1,0)$', color='blue')
plt.ylabel("Densidad")
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(theta, unnormalized_posterior, label=r'Numerador de Bayes $p(x=1,1,0|\theta)p(\theta)$', color='red')
plt.xlabel(r'$\theta$')
plt.ylabel("Valor")
plt.legend()
plt.tight_layout()
plt.show()
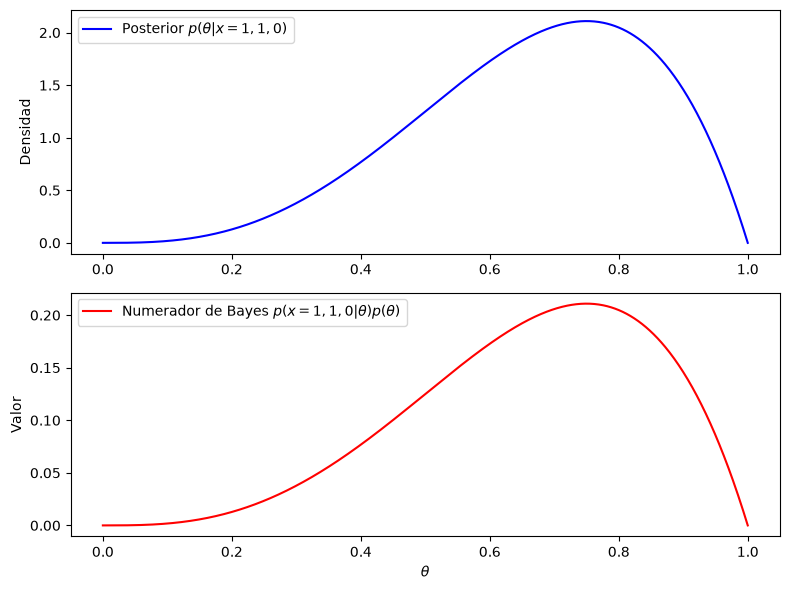
Una vez más, incluso para el caso de previas continuas, tenemos que:
o equivalentemente:
Ejemplo 3: (cambio de previa)#
En el ejemplo anterior supusimos una distribución previa particular para \(\theta\). Esta distribución \(p(\theta)=2 \theta\) implica que hay más probabilidad (previa) de que la moneda caiga cara. ¿Qué pasaría si no tuviéramos conocimiento previo alguno de esta probabilidad?
En este caso, suponemos que la previa es plana (uniforme en (0,1)). Similar al ejemplo anterior:
Hipótesis |
Rango |
Previa |
Verosimilitud |
Numerador de Bayes |
Posterior |
|---|---|---|---|---|---|
\(\theta\) |
[0, 1] |
\(1\) |
\(\theta^2(1-\theta)\) |
\(\theta^2(1-\theta)\) |
\(12 \theta^2 (1-\theta)\) |
total |
[0, 1] |
\(\int_{0}^{1} 1 \text{d}\theta = 1\) |
NO SUMA |
\(\int_{0}^{1} \theta^2(1-\theta) \text{d}\theta = 1/12\) |
\(1\) |
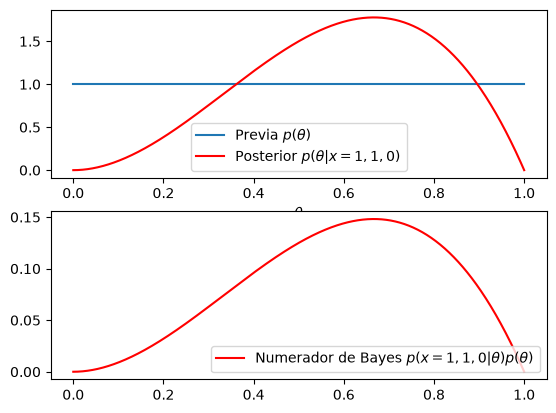
# Graficar previa y posterior
# Theta
theta = np.linspace(0, 1, 1001)
# Previa
prior = np.ones(1001)
# Posterior
posterior = 12 * theta**2 * (1 - theta)
# Graficamos
plt.subplot(2, 1, 1)
plt.plot(theta, prior, label=r'Previa $p(\theta)$')
plt.plot(theta, posterior, color='red', label=r'Posterior $p(\theta|x=1,1,0)$')
plt.legend()
plt.xlabel('$\\theta$')
plt.subplot(2, 1, 2)
num_bayes = theta**2 * (1 - theta)
plt.plot(theta, num_bayes, color='red',label=r'Numerador de Bayes $p(x=1,1,0|\theta)p(\theta)$')
plt.legend()
<matplotlib.legend.Legend at 0x74e0fc806c10>
Respondiendo preguntas con la distribución posterior#
Una vez tenemos la distribución posterior, la podemos utilizar para responder preguntas. Por ejemplo:
Primero defines la posterior \(p(\theta|x)\), es decir, la distribución de probabilidad sobre \(\theta\) despúes de ver los datos.
Con una distribución uniforme como la anterior, podemos ver que la moneda en principio no está sesgada:
#
theta = sp.symbols('theta')
integral = sp.integrate(1, (theta, 0.5, 1))
print("p(theta > 0.5) =", integral)
p(theta > 0.5) = 0.500000000000000
Después usas esa distribución para responder preguntas concretas sobre el parámetro.
Ejemplo: Después de observar la secuencia cara-cara-sello \(x = (1, 1, 0)\), pregunta:
¿qué probabilidad tiene ahora la moneda de estar sesgada a cara (\(\theta > 0.5\))?
Definir la posterior
Sabemos que después de ver \(x=(1,1,0)\) la posterior es:
#
theta = sp.symbols('theta')
posterior = 12*theta**2 * (1 - theta)
posterior
Probabilidad de que la moneda esté cargada a cara (\(\theta > 0.5\))
#
prob_theta_gt_05 = sp.integrate(posterior, (theta, 0.5, 1))
prob_theta_gt_05
#
prob_theta_gt_03 = sp.integrate(posterior, (theta, 0, 0.3))
prob_theta_gt_03
#
prob_theta_btw_02_06 = sp.integrate(posterior, (theta, 0.2, 0.6))
prob_theta_btw_02_06
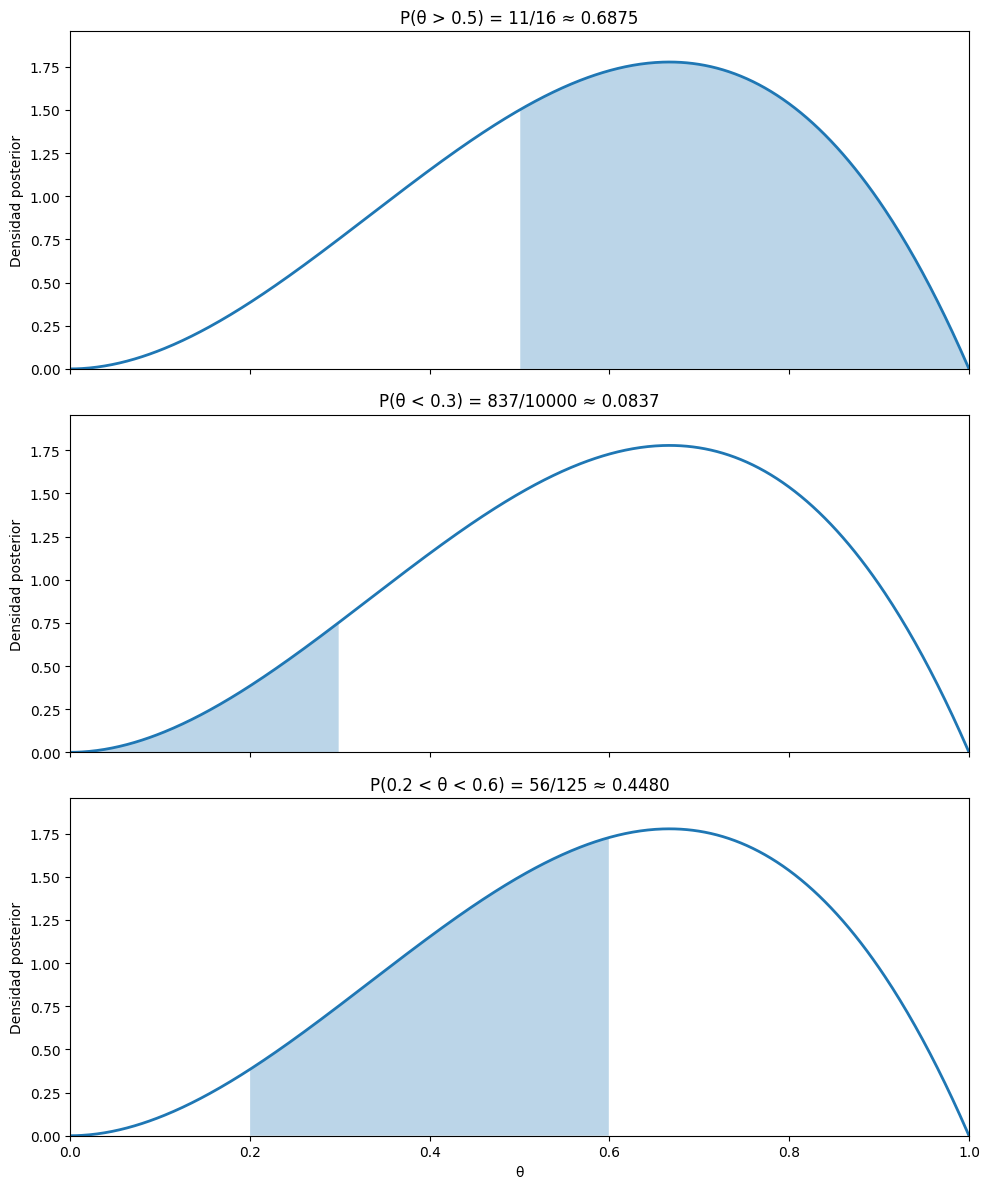
Figura 1. La distribución posterior \(p(\theta | x=1,1,0)\) nos permite responder preguntas sobre el parámetro \(\theta\). Por ejemplo, la probabilidad de que la moneda esté cargada a cara (\(\theta > 0.5\)) es el área bajo la curva desde 0.5 hasta 1 (área sombreada en azul). De la misma forma, podemos calcular la probabilidad de que \(\theta\) esté en cualquier otro intervalo.
Probabilidades predictivas#
Probabilidad predictiva previa#
Ejemplo 4 (predictiva previa)#
Continuando con el ejemplo original, tenemos una moneda con probabilidad desconocida \(\theta\) de caer cara y tenemos una pdf previa \(p(\theta) = 2 \theta\).
Pregunta: ¿Cuál es la probabilidad de que al lanzar la moneda salga cara?
(A) Probabilidad predictiva previa
Antes de observar ningún dato, la probabilidad de que el primer tiro sea cara es::
sabemos que \(p(x_1=1|\theta) =\theta\), por lo que:
Probabilidad predictiva posterior#
Ejemplo 5 (predictiva posterior)#
Continuando con el ejemplo original, tenemos una moneda con probabilidad desconocida \(\theta\) de caer cara y tenemos una pdf previa \(p(\theta) = 2 \theta\).
Pregunta
Suponga que se hace un tiro y cae cara. Encuentra la probabilidad predictiva posterior de que caiga cara.
(B) Probabilidad predictiva posterior
Para la probabilidad predictiva posterior, actualizamos a la posterior:
Hipótesis |
Rango |
Previa |
Verosimilitud |
Numerador de Bayes |
Posterior |
|---|---|---|---|---|---|
\(\theta\) |
[0, 1] |
\(2\theta\) |
\(\theta\) |
\(2\theta^2\) |
\(3 \theta^2\) |
total |
[0, 1] |
\(\int_{0}^{1} 2\theta \text{d}\theta = 1\) |
NO SUMA |
\(\int_{0}^{1} 2\theta^2 \text{d}\theta = 2/3\) |
\(1\) |
Todo continuo: previas continuas, verosimilitudes continuas#
Ejemplo 6: (normal-normal)#
Descripción del problema
Nivel 1: Datos Supongamos que tenemos un dato \(x=5\) que obtuvimos de una distribución normal con media \(\theta\) y varianza \(1\):
Nivel 2: Parámetro desconocido Supongamo que nuestra previa para el parámetro \(\theta\) es también una normal:
Pregunta
¿Cuál es la distribución posterior de \(\theta\) después de observar \(x=5\)?
Normal en general
Si una variable aleatoria \(Z \sim \mathcal{N}(\mu, \sigma^2)\), su densidad es:
Previa
En nuestro caso, la previa para \(\theta\) es:
Media: \(\mu = 2\)
Varianza: \(1 \implies \sigma = 1\)
Por lo tanto:
Verosimilitud
Numerador de Bayes
import sympy as sp
theta = sp.symbols('theta')
# expresiones originales
expr1 = -(theta-2)**2/2
expr2 = -(5-theta)**2/2
print("Expresión 1:", sp.latex(expr1))
print("Expresión 2:", sp.latex(expr2))
Expresión 1: - \frac{\left(\theta - 2\right)^{2}}{2}
Expresión 2: - \frac{\left(5 - \theta\right)^{2}}{2}
Lo anterior lo queremos llevar a una forma igual a la forma funcional de una normal:
# sustituir dentro del exponente
Con lo anterior:
Hipótesis |
Previa |
Verosimilitud |
Numerador de Bayes |
Posterior |
|---|---|---|---|---|
\(\theta\) |
\(\frac{1}{\sqrt{2 \pi}}e^{-(\theta - 2)^2/2}\) |
\(\frac{1}{\sqrt{2 \pi}}e^{-(5 - \theta)^2/2}\) |
\(c_1 e^{-(\theta - 7/2)^2}\) |
\(c_2 e^{-(\theta - 7/2)^2}\) |
total |
\(1\) |
NO SUMA |
\(\int_{-\infty}^{\infty} c_1 e^{-(\theta - 7/2)^2} \text{d}\theta = c1/c2\) |
\(1\) |
A partir de la forma obtenida en la posterior:
podemos compararla con la forma general de una distribución normal:
Para que ambas sean equivalentes, el número que acompaña al cuadrado debe coincidir.
En nuestra expresión es \(1\), mientras que en la forma general es \(\frac{1}{2\sigma^2}\).
Por tanto,
En consecuencia, la distribución posterior sigue una distribución:
Nota
Aunque esta expresión se puede integrar, el proceso se vuelve más complejo y deja de tener una forma elemental sencilla.
Lo importante aquí es notar que esta simplificación proviene de una prior conjugada, lo que nos permite mantener la misma familia de distribución (una Normal) y actualizar fácilmente los parámetros sin resolver integrales difíciles.
# --- Graficar --- #
from scipy import stats
# --- Graficar numerador y posterior --- #
Conclusiones#
Entonces, ¿qué hicimos en este proceso?
Resolviste analíticamente la distribución posterior que surge de una prior conjugada.
Gracias a que la forma funcional se mantiene dentro de la misma familia (en este caso, la Normal),
no fue necesario realizar integrales complejas: bastó con manipulación algebraica.
En este ejemplo particular:
La prior es Normal, centrada en 2.
La verosimilitud es Normal, centrada en 5.
El resultado es otra Normal, la posterior, centrada en \(\tfrac{7}{2}\) con varianza \(\tfrac{1}{2}\)
Por lo tanto: