Sesión 10#
Consultas probabilísticas#
1. Patrones de razonamiento e inferencia#
Teniendo una situación modelada con una red Bayesiana, nos podemos plantear tres tipos básicos de razonamiento de podríamos querer resolver:
Razonamiento causal
Razonamiento evidencial
Razonamiento intercausal
1.1. Razonamiento causal
El razonamiento causal sigue la dirección natural de las flechas del grafo: va de causa → efecto, o de nodo padre → nodo hijo.
Si sé algo sobre las causas, ¿qué puedo inferir sobre sus efectos?
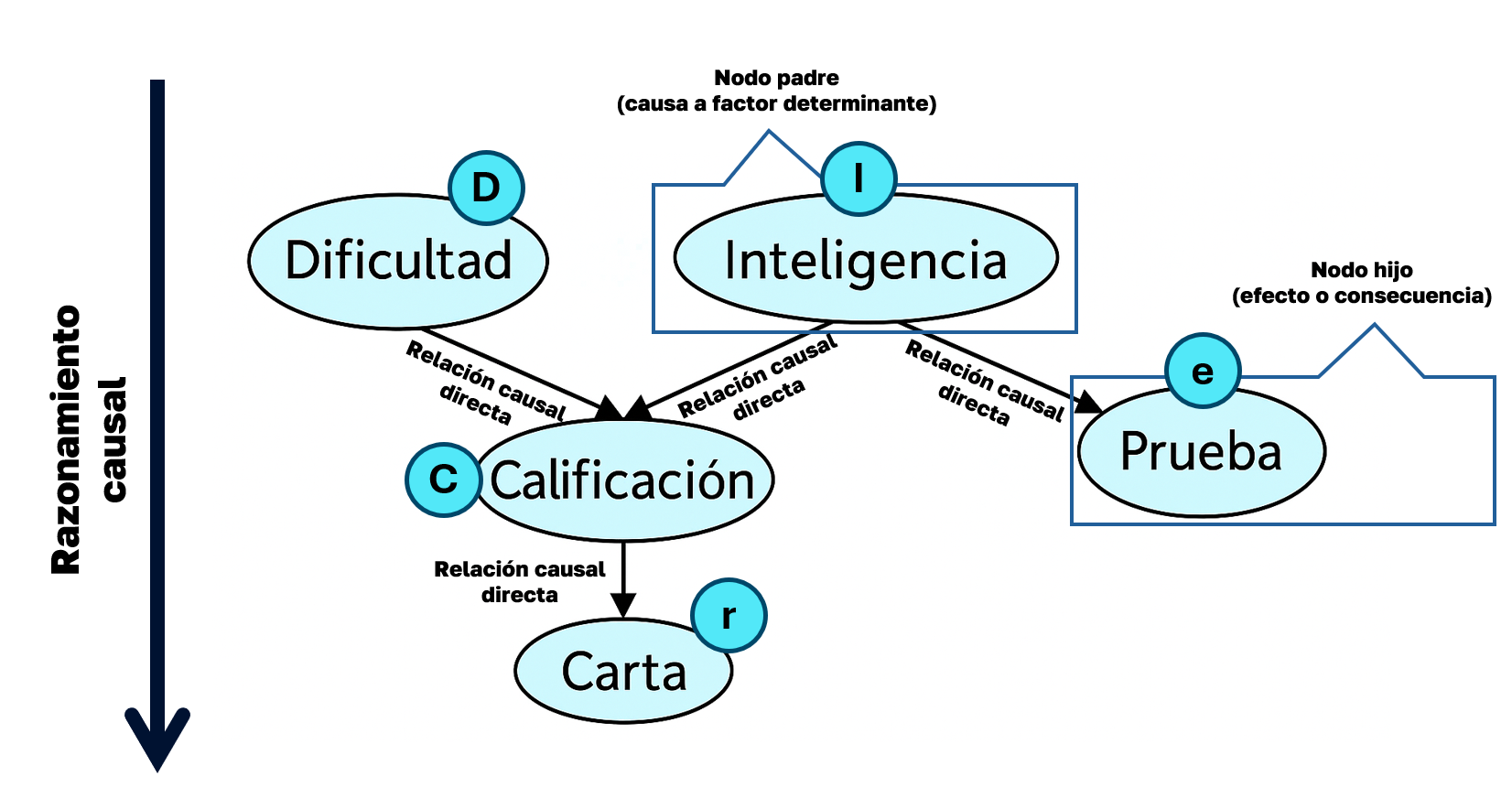
Por ejemplo,
Pregunta: ¿cuál es la probabilidad de obtener una buena carta de recomendación?
from pgmpy.models import BayesianNetwork, DiscreteBayesianNetwork
from pgmpy.factors.discrete import TabularCPD
student_model = DiscreteBayesianNetwork(
[("D", "C"), ("I", "C"), ("I", "E"), ("C", "R")]
)
# CPDs
cpd_D = TabularCPD(
variable='D',
variable_card=2,
values=[
[0.6],
[0.4]
]
)
cpd_I = TabularCPD(
variable='I',
variable_card=2,
values=[
[0.7],
[0.3]
]
)
cpd_C = TabularCPD(
variable='C',
variable_card=3,
values=[
[0.30, 0.70, 0.02, 0.20],
[0.40, 0.25, 0.08, 0.30],
[0.30, 0.05, 0.90, 0.50]
],
evidence=['I', 'D'],
evidence_card=[2, 2]
)
cpd_E = TabularCPD(
variable='E',
variable_card=2,
values=[
[0.95, 0.20],
[0.05, 0.80]
],
evidence=['I'],
evidence_card=[2]
)
cpd_R = TabularCPD(
variable='R',
variable_card=2,
values=[
[0.99, 0.40, 0.10],
[0.01, 0.60, 0.90]
],
evidence=['C'],
evidence_card=[3]
)
student_model.add_cpds(cpd_D, cpd_I, cpd_C, cpd_E, cpd_R)
# Obtenemos la distribución conjunta de la red
p_joint = (
cpd_I.to_factor()
* cpd_D.to_factor()
* cpd_C.to_factor()
* cpd_E.to_factor()
* cpd_R.to_factor()
)
print(p_joint)
+------+------+------+------+------+------------------+
| I | R | E | C | D | phi(I,R,E,C,D) |
+======+======+======+======+======+==================+
| I(0) | R(0) | E(0) | C(0) | D(0) | 0.1185 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(0) | C(0) | D(1) | 0.1843 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(0) | C(1) | D(0) | 0.0638 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(0) | C(1) | D(1) | 0.0266 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(0) | C(2) | D(0) | 0.0120 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(0) | C(2) | D(1) | 0.0013 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(1) | C(0) | D(0) | 0.0062 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(1) | C(0) | D(1) | 0.0097 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(1) | C(1) | D(0) | 0.0034 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(1) | C(1) | D(1) | 0.0014 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(1) | C(2) | D(0) | 0.0006 |
+------+------+------+------+------+------------------+
| I(0) | R(0) | E(1) | C(2) | D(1) | 0.0001 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(0) | C(0) | D(0) | 0.0012 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(0) | C(0) | D(1) | 0.0019 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(0) | C(1) | D(0) | 0.0958 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(0) | C(1) | D(1) | 0.0399 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(0) | C(2) | D(0) | 0.1077 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(0) | C(2) | D(1) | 0.0120 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(1) | C(0) | D(0) | 0.0001 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(1) | C(0) | D(1) | 0.0001 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(1) | C(1) | D(0) | 0.0050 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(1) | C(1) | D(1) | 0.0021 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(1) | C(2) | D(0) | 0.0057 |
+------+------+------+------+------+------------------+
| I(0) | R(1) | E(1) | C(2) | D(1) | 0.0006 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(0) | C(0) | D(0) | 0.0007 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(0) | C(0) | D(1) | 0.0048 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(0) | C(1) | D(0) | 0.0012 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(0) | C(1) | D(1) | 0.0029 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(0) | C(2) | D(0) | 0.0032 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(0) | C(2) | D(1) | 0.0012 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(1) | C(0) | D(0) | 0.0029 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(1) | C(0) | D(1) | 0.0190 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(1) | C(1) | D(0) | 0.0046 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(1) | C(1) | D(1) | 0.0115 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(1) | C(2) | D(0) | 0.0130 |
+------+------+------+------+------+------------------+
| I(1) | R(0) | E(1) | C(2) | D(1) | 0.0048 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(0) | C(0) | D(0) | 0.0000 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(0) | C(0) | D(1) | 0.0000 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(0) | C(1) | D(0) | 0.0017 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(0) | C(1) | D(1) | 0.0043 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(0) | C(2) | D(0) | 0.0292 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(0) | C(2) | D(1) | 0.0108 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(1) | C(0) | D(0) | 0.0000 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(1) | C(0) | D(1) | 0.0002 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(1) | C(1) | D(0) | 0.0069 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(1) | C(1) | D(1) | 0.0173 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(1) | C(2) | D(0) | 0.1166 |
+------+------+------+------+------+------------------+
| I(1) | R(1) | E(1) | C(2) | D(1) | 0.0432 |
+------+------+------+------+------+------------------+
#print
# Marginalizar sobre las variables
p_R = p_joint.marginalize(variables=['D','I', 'C', 'E'], inplace=False)
print(p_R)
+------+----------+
| R | phi(R) |
+======+==========+
| R(0) | 0.4977 |
+------+----------+
| R(1) | 0.5023 |
+------+----------+
# ¿qué operación me permite obtener la probabilidad de r1 en específico?
p_r1 = p_R.reduce(values=[('R', 1)], inplace=False)
print(p_r1)
+---------+
| phi() |
+=========+
| 0.5023 |
+---------+
Sin embargo, podemos evaluar cómo esta probabilidad cambia si la condicionamos sobre la inteligencia. Por ejemplo, si el estudiante no es muy inteligente
# marginalizar sobre las variables D, C, E // numerador
p_RI = p_joint.marginalize(variables=['D', 'C', 'E'], inplace=False)
print(p_RI)
+------+------+------------+
| I | R | phi(I,R) |
+======+======+============+
| I(0) | R(0) | 0.4280 |
+------+------+------------+
| I(0) | R(1) | 0.2720 |
+------+------+------------+
| I(1) | R(0) | 0.0697 |
+------+------+------------+
| I(1) | R(1) | 0.2303 |
+------+------+------------+
# get_value
i_0 = p_RI.get_value(R=1, I=0)
i_0
np.float64(0.27202000000000004)
# marginalizar sobre las variables D, C, E, R // denominador
p_I = p_joint.marginalize(variables=['D', 'C', 'E', 'R'], inplace=False)
print(p_I)
+------+----------+
| I | phi(I) |
+======+==========+
| I(0) | 0.7000 |
+------+----------+
| I(1) | 0.3000 |
+------+----------+
# get_value
r1_i0 = p_I.get_value(I=0)
r1_i0
np.float64(0.6999999999999998)
¿se esperaba esto o no?
# print probabilidad de r1 dado i0
i_0/r1_i0
np.float64(0.38860000000000017)
Por otra parte, si también condicionamos sobre la dificultad
# Marginalizar sobre las variables C, E, R // numerador
p_RID = p_joint.marginalize(variables=['C','E'], inplace=False)
r1_i0_d0 = p_RID.get_value(R=1, I=0, D=0)
r1_i0_d0
np.float64(0.21546)
# Marginalizar sobre las variables C, E, R, I // denominador
p_ID = p_joint.marginalize(variables=['C', 'E', 'R'], inplace=False)
i0_d0 = p_ID.get_value(I=0, D=0)
i0_d0
np.float64(0.41999999999999993)
¿Se esperaba esto o no?
#print probabilidad de r1 dado i0 y d0
r1_i0_d0 / i0_d0
np.float64(0.5130000000000001)
2. Razonamiento evidencial
Va de efecto a causa, en sentido contrario a las flechas.
Si observo un efecto, ¿qué puedo inferir sobre sus causas?
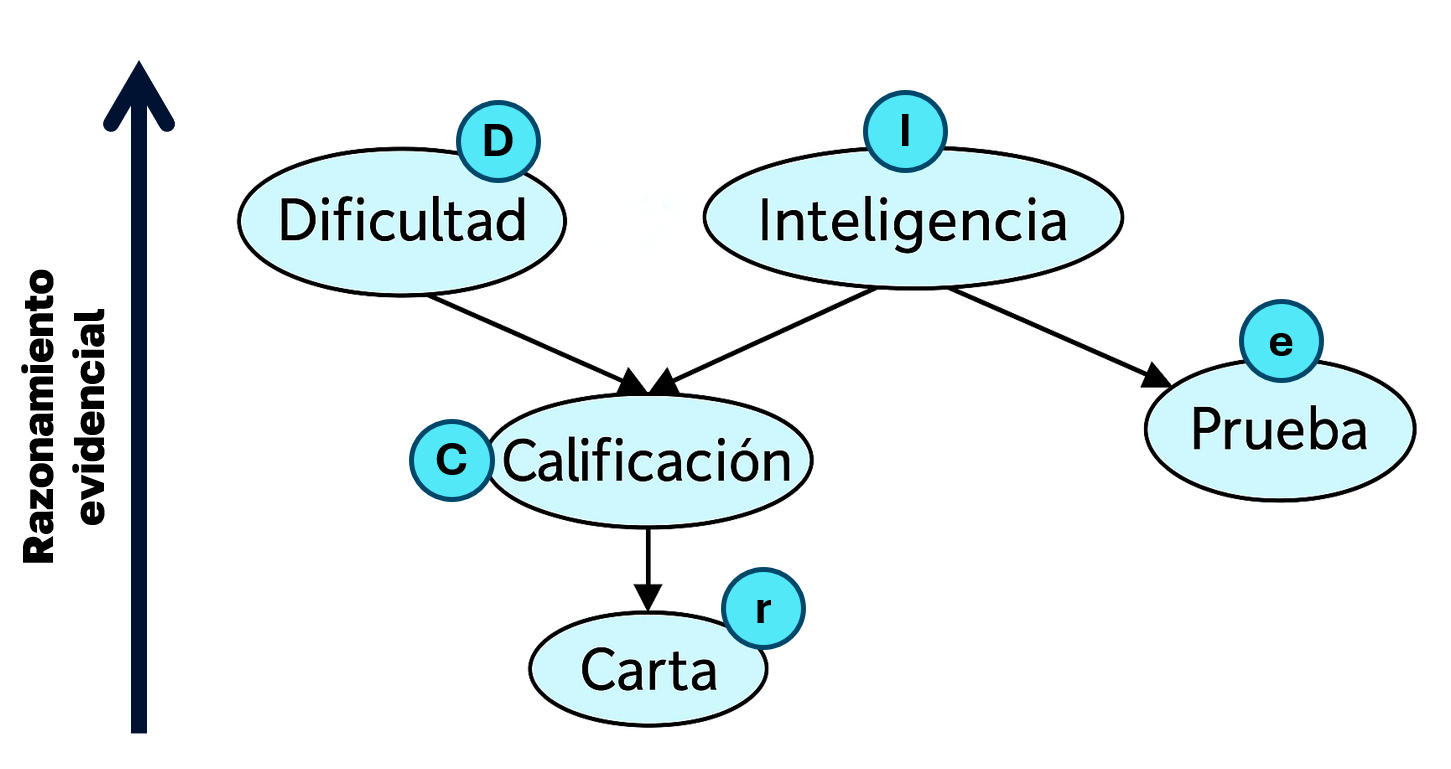
Por ejemplo, la probabilidad de que el curso sea difícil es:
Condicionando sobre la calificación:
# marginalizar sobre las variables I, E, R // numerador
p_DC = p_joint.marginalize(
variables=['I', 'E', 'R'],
inplace=False
)
p_d1_c0 = p_DC.get_value(D=1, C=0)
p_d1_c0
np.float64(0.21999999999999995)
# marginalizar sobre las variables D, I, E, R // denominador
p_C = p_joint.marginalize(
variables=['D', 'I', 'E', 'R'],
inplace=False
)
p_c0 = p_C.get_value(C=0)
p_c0
np.float64(0.34959999999999997)
# print probabilidad de d1 dado c0
p_d1_c0/p_c0
np.float64(0.6292906178489701)
#Otra forma de calcular P(D1 | C0) usando inferencia en la red bayesiana
from pgmpy.inference import VariableElimination
infer = VariableElimination(student_model)
phi = infer.query(
variables=['D'],
evidence={'C': 0}
)
phi.values[1]
/home/docs/checkouts/readthedocs.org/user_builds/modelos-graficos-probabilisticos/envs/v2026/lib/python3.13/site-packages/pgmpy/estimators/__init__.py:4: FutureWarning: `pgmpy.estimators.StructureScore` is deprecated and will be removed in v1.3.0. Use `pgmpy.structure_score` instead.
from .StructureScore import (
np.float64(0.6292906178489702)
phi.values[0]
np.float64(0.3707093821510298)
Intuición: observar una calificación baja hace más probable que el curso haya sido difícil (sube de \(0.4\) a \(\approx 0.63\)).
Similarmente, la probabilidad de que el estudiante sea inteligente es:
Condicionando sobre la calificación:
# marginalizar sobre las variables D, E, R // numerador
p_IC = p_joint.marginalize(
variables=['D', 'E', 'R'],
inplace=False
)
p_i1_c0 = p_IC.get_value(I=1, C=0)
# marginalizar sobre las variables D, I, E, R // denominador
p_C = p_joint.marginalize(
variables=['D', 'I', 'E', 'R'],
inplace=False
)
p_c0 = p_C.get_value(C=0)
# print probabilidad de i1 dado c0
p_i1_c0/p_c0
np.float64(0.07894736842105264)
# o con VariableElimination
infer = VariableElimination(student_model)
phi = infer.query(
variables=['I'],
evidence={'C': 0}
)
phi.values[1]
np.float64(0.07894736842105264)
Intuición: observar una calificación baja hace menos probable que el estudiante sea inteligente (baja del \(0.3\) a \(\approx 0.11\)).
3. Razonamiento intercausal
Ocurre cuando dos causas comparten un mismo efecto y una de ellas se observa.
Si conozco una causa, ¿cómo cambia mi creencia sobre la otra, dado que comparten el mismo efecto?
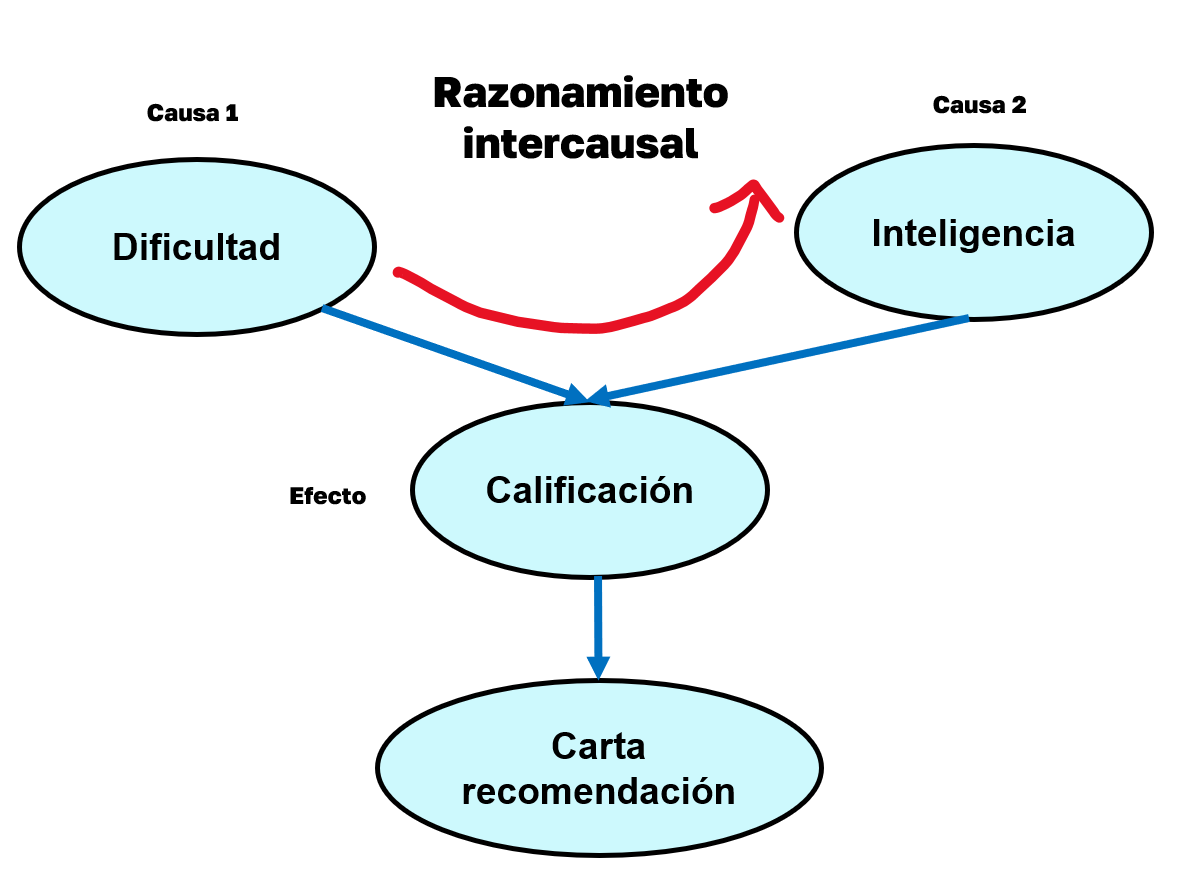
\(\text{Dificultad} \longrightarrow \text{Calificación} \longleftarrow \text{Inteligencia}\)
Normalmente, \(D\) e \(I\) son independientes. Pero, una vez que conocemos el efecto común -por ejemplo, la calificación \(C\)-, dejan de serlo.
Si sabemos que la calificación fue alta y que el curso era difícil, es más probable que el estudiante haya sido inteligente.
Antes de observar \(C\):
Después de observar \(C\): $\( D \not\perp I \mid C \)$
De nuevo, la probabilidad de que el estudiante sea inteligente es:
Condicionando sobre la calificación:
Aún más, si condicionamos sobre la dificultad:
# VariableElimination
infer = VariableElimination(student_model)
phi = infer.query(
variables=['I'],
evidence={'C':0, 'D':1}
)
phi.values[1]
np.float64(0.1090909090909091)
Inicialmente, el estudiante tiene una probabilidad moderada de ser inteligente (\(P(i^1)=0.3\)). Al observar que obtuvo una mala calificación, esa creencia disminuye drásticamente (\(P(i^1 \mid c^0) \approx 0.07\)). Sin embargo, si además sabemos que el curso era difícil, parte de la mala nota se explica por la dificultad, por lo que la probabilidad de que sea inteligente vuelve a subir ligeramente \(P(i^1 \mid c^0, d^1) \approx 0.11\).
#guardar el modelo
#import pickle
#with open('student-model.pkl', 'wb') as f:
# pickle.dump(student_model, f)
Consultas MAP#
from pgmpy.inference import VariableElimination
infer = VariableElimination(student_model)
import numpy as np
# traducimos los códigos a etiquetas
etq = {"D":{0:"fácil",1:"difícil"},
"I":{0:"no inteligente",1:"inteligente"},
"C":{0:"nota baja",1:"nota media",2:"nota alta"},
"E":{0:"examen bajo",1:"examen alto"},
"R":{0:"carta débil",1:"carta fuerte"}}
# Marginal de cada variable (query)
print("\nGanador suelto de cada variable (marginal):")
for v in ["D","I","C","E","R"]:
p = infer.query([v], show_progress=False).values
print(f" P({v})={np.round(p,3)} -> {etq[v][int(np.argmax(p))]}")
Ganador suelto de cada variable (marginal):
P(D)=[0.6 0.4] -> fácil
P(I)=[0.7 0.3] -> no inteligente
P(C)=[0.35 0.288 0.362] -> nota alta
P(E)=[0.725 0.275] -> examen bajo
P(R)=[0.498 0.502] -> carta fuerte
# MAP: el escenario completo más probable (map_query)
escenario = infer.map_query(["D","I","C","E","R"], show_progress=False)
print("Escenario más probable (MAP):")
for v in ["D","I","C","E","R"]:
print(f"{v}={escenario[v]} -> {etq[v][escenario[v]]}")
Escenario más probable (MAP):
D=1 -> difícil
I=0 -> no inteligente
C=0 -> nota baja
E=0 -> examen bajo
R=0 -> carta débil
Marginal vs MAP:#
El código hace dos preguntas distintas:
infer.query([v])por variable → «lo más común de cada cosa por separado» (marginal).infer.map_query([...])→ «el alumno completo más probable» (MAP).
Las dos respuestas:#
Cada cosa por separado |
El alumno completo (MAP) |
|
|---|---|---|
Dificultad |
fácil |
difícil ⬅ |
Inteligencia |
no inteligente |
no inteligente |
Calificación |
alta |
baja ⬅ |
Examen |
bajo |
bajo |
Carta |
fuerte |
débil ⬅ |
Tres casillas cambian.
MAP con evidencia: el alumno completo más probable#
Pregunta: si el alumno salió mal en la prueba (\(E=0\)) y recibió una carta mala (\(R=0\)), ¿cuál es la combinación más probable de Dificultad (Fácil/Difícil), Inteligencia (No mucho/Inteligente) y Calificación (Baja/Media/Alta)?
# MAP: la tripleta (D, I, C) más probable JUNTA, dada la evidencia
infer.map_query(["D","I","C"], evidence={"E":0, "R":0}, show_progress=False)
print("Dado: prueba mala (E=0) + carta mala (R=0)\n")
print("Escenario más probable (MAP):")
for v in ["D","I","C"]:
print(f" {v} -> {etq[v][escenario[v]]}")
Dado: prueba mala (E=0) + carta mala (R=0)
Escenario más probable (MAP):
D -> difícil
I -> no inteligente
C -> nota baja
Cómo lo leemos: MAP busca la tripleta \((D,I,C)\) más probable junta, no el valor más probable de cada variable por separado.
Resultado: la explicación conjunta más probable es curso difícil, alumno no muy inteligente, calificación baja.
Es una historia coherente: un alumno no brillante en un curso difícil lo más seguro saca nota baja -> y una nota baja produce una carta mala.
¿Qué hace MAP, matemáticamente?#
Con la intuición ya clara (la historia más probable, los eslabones), esto es lo mismo pero formal. Tres pasos.
Paso 1#
Queremos la tripleta que maximiza la posterior:
Pero \(P(d,i,c\mid e)=\dfrac{P(d,i,c,\,E{=}0,R{=}0)}{P(E{=}0,R{=}0)}\), y el denominador no depende de \((d,i,c)\): es la misma constante para todos, así que no cambia quién gana.
Para MAP no hay que normalizar: se trabaja con la conjunta directa.
Paso 2: Factorizar con la red#
La estructura del grafo dice que cada nodo aporta \(P(\text{nodo}\mid\text{padres})\) (regla de la cadena + independencias locales):
Metemos la evidencia \(E{=}0,\,R{=}0\) y dejamos libres \(d,i,c\):
La evidencia entra como dos factores fijos que reponderan a los candidatos.
Paso 3: Cómo se resuelve: todo junto, no factor por factor#
⚠️ MAP no maximiza cada factor por separado (eso es el error marginal). Maximiza el producto completo, de una sola vez.
1. La evidencia mete dos «presiones»:
Al fijar \(E{=}0\) y \(R{=}0\), cada factor se reduce a una sola columna de su CPD (la del valor observado): un número por candidato, que lo multiplica.
De la CPD de Prueba, columna Malo (\(e^0\)) → \(P(E{=}0\mid i)\):
\(i\) |
\(P(E{=}0\mid i)\) |
|---|---|
\(i^0\) (no inteligente) |
0.95 |
\(i^1\) (inteligente) |
0.20 |
Como \(0.95 \gg 0.20\), multiplica mucho más a los candidatos con \(i^0\) → empuja hacia «no inteligente» (una prueba mala casi solo sale de un alumno no inteligente).
De la CPD de Carta, columna Mala (\(r^0\)) → \(P(R{=}0\mid c)\):
\(c\) |
\(P(R{=}0\mid c)\) |
|---|---|
\(c^0\) (baja) |
0.99 |
\(c^1\) (media) |
0.40 |
\(c^2\) (alta) |
0.10 |
Como \(0.99 \gg 0.40 > 0.10\), multiplica mucho más a los \(c^0\) → empuja hacia «nota baja» (una carta mala casi solo sale de una nota baja).
2. Pero \(P(c\mid i,d)\) acopla todo. Este factor depende de tres variables a la vez, así que no podemos leer la «contribución de \(C\)» sin fijar también \(I\) y \(D\). Mira la CPD de Calificación, columna Baja (\(c^0\)), fila \(i^0\):
\(i, d\) |
\(P(c^0=\text{baja}\mid i,d)\) |
|---|---|
\(i^0, d^0\) (fácil) |
0.30 |
\(i^0, d^1\) (difícil) |
0.70 |
3. La prueba de que es conjunto: miremos \(D\). Ya fijados \(i^0\) y \(c^0\) (lo que la evidencia pide), comparamos fácil vs difícil. Los únicos factores que cambian son \(P(D)\) y \(P(c^0\mid i^0,D)\):
\(D\) |
\(P(D)\) |
\(P(c^0\mid i^0,D)\) |
|---|---|---|
fácil (\(d^0\)) |
0.6 |
0.30 |
difícil (\(d^1\)) |
0.4 |
0.70 |
Aunque el prior de fácil es mayor (\(0.6 > 0.4\)), gana difícil.
La nota baja es tan compatible con un curso difícil que compensa su prior más bajo. Por eso ningún factor manda solo: gana la combinación.
El ganador (de las \(2\times2\times3=12\) combinaciones):
Ese producto es la probabilidad del mundo completo; maximizarlo = la cadena de factores con el producto más grande.