Sesión 5 A#
El error (ε) en regresión lineal: de la geometría a la estadística#
Objetivos de la clase:
Recordar el ajuste de curvas polinomiales.
Entender el fenómeno de overfitting en casos prácticos.
Explicar los mínimos cuadrados ordinaros mediante el principio de máxima verosimilitud.
1. Introducción#
Supongamos que tenemos un conjunto de entrenamiento con \(N\) observaciones de \(x\),
en conjunto con las observaciones correspondientes de la variable objetivo \(y\),
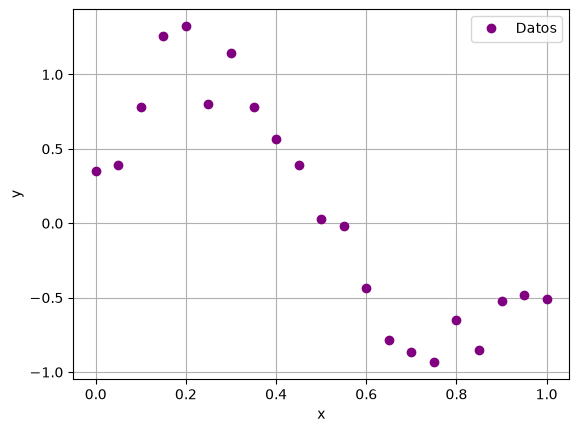
En la siguiente gráfica se muestran datos de entrenamiento, con \(N=21\). Estos datos se generaron eligiendo \(x\) uniformemente espaciados en el intervalo \([0, 1]\), y la variable objetivo \(y\) como el resultado de la función \(\sin (2 \pi x)\) más un pequeño ruido distribuido normal:
# Importar bibliotecas
import numpy as np
import matplotlib.pyplot as plt
# Siembra una semilla
np.random.seed(0)
# Genera los datos (ficticios) del problema anterior
N = 21
x = np.linspace(0, 1, N)
y = np.sin(2 * np.pi * x) + np.random.normal(0, 0.2, N)
# Gráfica de los datos
plt.plot(x, y, 'o', label='Datos', color='purple')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid()
plt.show()
Objetivo:
Explorar estos datos de entrenamiento para hacer predicciones \(\hat{y}\) de la variable objetivo para algún nuevo valor de la variable de entrada.
Matemáticamente:
Antes de formular el problema de forma probabilística, procedamos de forma más intuitiva. Lo que queremos hacer es ajustar a los datos una función polinomial de la forma:
Notemos que aunque \(f\) es una función no lineal de \(x\), es una función lineal respecto a los coeficientes \(w\).
Linealidad del modelo (respecto a los parámetros)
¿Qué significa que una función sea lineal respecto a sus parámetros?
Una función es lineal en los parámetros cuando los coeficientes aparecen sin ser multiplicados entre sí, elevados a potencias ni dentro de funciones no lineales.
En otras palabras, la expresión puede escribirse como:
donde \(g_i(x)\) son funciones conocidas de las variables \(x\).
Ejemplo lineal en los parámetros:
(lineal en \(\beta_0, \beta_1, \beta_2\), aunque no en \(x\)).
Ejemplo no lineal en los parámetros:
porque \(\beta_1\) aparece dentro de una función exponencial.
Esta distinción es crucial: si un modelo es lineal en los parámetros, se pueden usar métodos como (OLS) para estimarlos de forma directa.
Los valores de los coeficientes (parámetros, pesos) serán determinados ajustando el polinomio a los datos de entrenamiento. Esto se puede lograr minimizando una función de error (de costo o de pérdida) que mide la falta de ajuste entre la función \(f(x, w)\) y los datos de entrenamiento.
Una elección comúnmente usada para esta función de error está dada por la suma de cuadrados de los errores entre las predicciones sobre los datos de entrenamiento \(f(x_n,w)\) y los valores correspondientes del objetivo \(y_n\), de forma que minimizaremos:
De forma que podemos resolver el problema de ajuste de curvas mediante la elección de \(w\) para la cual \(E(w)\) sea lo más pequeña posible.
Nota. Dado que \(E(w)\) es una función cuadrática de los coeficientes \(w\), sus derivadas respecto a los coeficientes serán lineales respecto a \(w\), y el problema de minimización tendrá solución única.
Expresión matricial de la función objetivo#
Antes de continuar, conviene obtener una representación más compacta del problema anterior. Comencemos por trabajar con el polinomio, dándonos cuenta de que este es un producto punto entre los coeficientes \(w\) y las potencias de \(x\):
donde:
\(x\) es la variable explicativa (escalar),
\(w_0, w_1, \dots, w_M\) son los parámetros que queremos estimar.
I. Vector de parámetros
II. Vector de características (o variables independientes)
III. Producto escalar o producto punto
IV. Matriz de diseño
V. Predicciones para todos los datos
y, luego, ¿qué necesitamos hacer a continuación?
Norma euclidiana#
1. La norma euclidiana: la idea general#
Primero recordemos la definición de la norma euclidiana, que simplemente mide la «longitud» de un vector en el espacio.
Si tenemos un vector:
la norma euclidiana de \(v\) es:
o equivalentemente \(||v||^2 = v_1^2 + v_2^2 + \dots + v_s^2 = \sum_{i=1}^{s} v_i^2\).
Con lo anterior, notemos que la función de error la podemos reescribir en términos de la norma de un vector:
donde el vector \(Z\) es:
De este modo, queremos encontrar
Ejercicio numérico#
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
x
array([0. , 0.05, 0.1 , 0.15, 0.2 , 0.25, 0.3 , 0.35, 0.4 , 0.45, 0.5 ,
0.55, 0.6 , 0.65, 0.7 , 0.75, 0.8 , 0.85, 0.9 , 0.95, 1. ])
# PolynomialFeatures y Phi (matriz de diseño)
Phi = PolynomialFeatures(degree=2).fit_transform(x[:, None])
Phi
array([[1. , 0. , 0. ],
[1. , 0.05 , 0.0025],
[1. , 0.1 , 0.01 ],
[1. , 0.15 , 0.0225],
[1. , 0.2 , 0.04 ],
[1. , 0.25 , 0.0625],
[1. , 0.3 , 0.09 ],
[1. , 0.35 , 0.1225],
[1. , 0.4 , 0.16 ],
[1. , 0.45 , 0.2025],
[1. , 0.5 , 0.25 ],
[1. , 0.55 , 0.3025],
[1. , 0.6 , 0.36 ],
[1. , 0.65 , 0.4225],
[1. , 0.7 , 0.49 ],
[1. , 0.75 , 0.5625],
[1. , 0.8 , 0.64 ],
[1. , 0.85 , 0.7225],
[1. , 0.9 , 0.81 ],
[1. , 0.95 , 0.9025],
[1. , 1. , 1. ]])
# Define un modelo usando Pipeline
model_3 = Pipeline([
('features', PolynomialFeatures(degree=3)),
('scaler', StandardScaler()),
('model', LinearRegression())
])
# Modelo
model_3
Pipeline(steps=[('features', PolynomialFeatures(degree=3)),
('scaler', StandardScaler()), ('model', LinearRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Parameters
Parameters
# qué contiene x
x
array([0. , 0.05, 0.1 , 0.15, 0.2 , 0.25, 0.3 , 0.35, 0.4 , 0.45, 0.5 ,
0.55, 0.6 , 0.65, 0.7 , 0.75, 0.8 , 0.85, 0.9 , 0.95, 1. ])
# Genera una partición entre train/test
x_train, x_test, y_train, y_test = train_test_split(x[:, None], y, test_size=0.2, random_state=0)
# Ajusta el modelo
model_3.fit(x_train, y_train)
Pipeline(steps=[('features', PolynomialFeatures(degree=3)),
('scaler', StandardScaler()), ('model', LinearRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Fitted attributes
4 features
| 1 |
| x0 |
| x0^2 |
| x0^3 |
Parameters
Fitted attributes
4 features
| x0 |
| x1 |
| x2 |
| x3 |
Parameters
Fitted attributes
# Genera los coeficientes de la regresión lineal
model_3.named_steps['model'].coef_
array([ 0. , 2.68944506, -8.69362895, 5.46899018])
# ¿cuál es el score sobre los datos de entrenamiento?
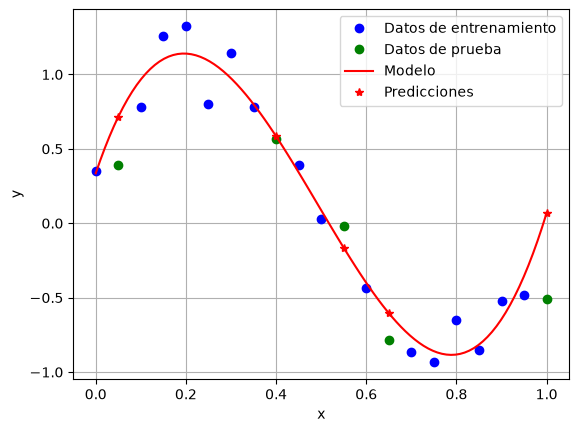
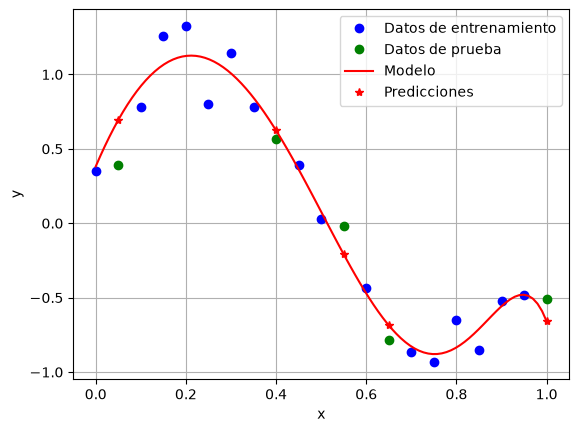
model_3.score(x_train, y_train)
0.9689517224841414
# ¿cuál es el score sobre los datos de test?
model_3.score(x_test, y_test)
0.624938368842177
# Grafica los resultados de train y test, así como el polinomio
plt.plot(x_train[:, 0], y_train, 'ob', label='Datos de entrenamiento')
plt.plot(x_test[:, 0], y_test, 'og', label='Datos de prueba')
x_model = np.linspace(0, 1, 100)
y_model = model_3.predict(x_model[:, None])
plt.plot(x_model, y_model, '-r', label='Modelo')
plt.plot(x_test[:, 0], model_3.predict(x_test), '*r', label='Predicciones')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid()
plt.show()
# Define un nuevo modelo con grado 10
model_10 = Pipeline([
('features', PolynomialFeatures(degree=10)),
('scaler', StandardScaler()),
('model', LinearRegression())
])
# Ajusta el modelo anterior
model_10.fit(x_train, y_train)
Pipeline(steps=[('features', PolynomialFeatures(degree=10)),
('scaler', StandardScaler()), ('model', LinearRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Fitted attributes
11 features
| 1 |
| x0 |
| x0^2 |
| x0^3 |
| x0^4 |
| x0^5 |
| x0^6 |
| x0^7 |
| x0^8 |
| x0^9 |
| x0^10 |
Parameters
Fitted attributes
11 features
| x0 |
| x1 |
| x2 |
| x3 |
| x4 |
| x5 |
| x6 |
| x7 |
| x8 |
| x9 |
| x10 |
Parameters
Fitted attributes
| Name | Type | Value |
|---|---|---|
|
coef_
coef_: array of shape (n_features, ) or (n_targets, n_features) Estimated coefficients for the linear regression problem. If multiple targets are passed during the fit (y 2D), this is a 2D array of shape (n_targets, n_features), while if only one target is passed, this is a 1D array of length n_features. |
ndarray[float64](11,) | [ 0. , -0.23, 39.43,..., 207.67,-592.22, 235.49] |
|
intercept_
intercept_: float or array of shape (n_targets,) Independent term in the linear model. Set to 0.0 if `fit_intercept = False`. |
float64 | 0.1327 |
|
n_features_in_
n_features_in_: int Number of features seen during :term:`fit`. .. versionadded:: 0.24 |
int | 11 |
|
rank_
rank_: int Rank of matrix `X`. Only available when `X` is dense. |
int | 8 |
|
singular_
singular_: array of shape (min(X, y),) Singular values of `X`. Only available when `X` is dense. |
ndarray[float64](11,) | [12.23, 3.1 , 0.82,..., 0. , 0. , 0. ] |
# ¿cuál es el score sobre los datos de entrenamiento?
model_10.score(x_train, y_train)
0.975489947964474
# ¿cuál es el score sobre los datos de test?
model_10.score(x_test, y_test)
0.2709806393273839
model_3.named_steps['model'].coef_
array([ 0. , 2.68944506, -8.69362895, 5.46899018])
model_10.named_steps['model'].coef_
array([ 0.00000000e+00, -2.33114139e-01, 3.94319098e+01, -2.54326370e+02,
6.12383498e+02, -5.38141998e+02, -2.15129994e+02, 5.04521036e+02,
2.07668725e+02, -5.92221950e+02, 2.35487640e+02])
# Grafica los resultados de train y test, así como el polinomio
plt.plot(x_train[:, 0], y_train, 'ob', label='Datos de entrenamiento')
plt.plot(x_test[:, 0], y_test, 'og', label='Datos de prueba')
x_model = np.linspace(0, 1, 100)
y_model = model_10.predict(x_model[:, None])
plt.plot(x_model, y_model, '-r', label='Modelo')
plt.plot(x_test[:, 0], model_10.predict(x_test), '*r', label='Predicciones')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid()
plt.show()
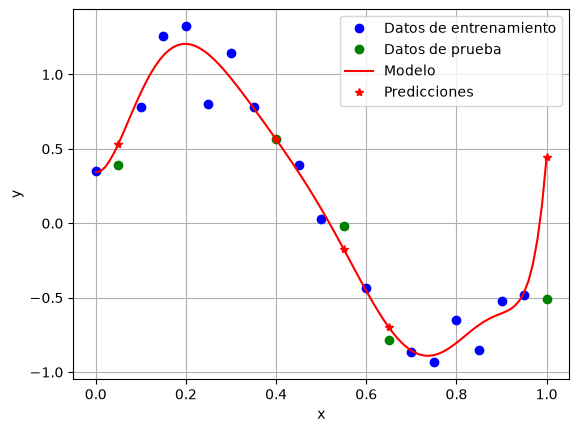
Overfitting#
Hasta ahora, hemos definido la función de error como
donde la norma euclidiana mide el tamaño del vector de errores \(\mathbf{e} = \Phi \mathbf{w} - \mathbf{y}\).
👉 Sin embargo, aún no hemos puesto ninguna restricción sobre los parámetros
\(\mathbf{w}\).
Si los pesos crecen demasiado (por ejemplo, al intentar ajustar exactamente todos los puntos de entrenamiento), podemos caer en overfitting: el modelo memoriza el ruido en lugar de generalizar.
Para evitarlo, añadimos un nuevo término a la función objetivo que ahora también mida la magnitud de los parámetros. Así obtenemos la regresión Ridge:
donde el hiperparámetro \(\lambda \geq 0\) controla el equilibrio entre:
Buen ajuste a los datos (primer término).
Mantener los parámetros pequeños (segundo término).
Si \(\lambda = 0\), recuperamos la regresión normal.
Si \(\lambda\) es grande, los pesos se reducen mucho y el modelo se vuelve más simple.
¿qué solución óptima nos ofrece la regresión Ridge?
from sklearn.linear_model import Ridge, Lasso
# Define un pipeline, incluyendo ahora Ridge
model_10_ridge = Pipeline([
('features', PolynomialFeatures(degree=10)),
('scaler', StandardScaler()),
('model', Ridge(alpha=1e-3))
])
# Ajusta el modelo
model_10_ridge.fit(x_train, y_train)
Pipeline(steps=[('features', PolynomialFeatures(degree=10)),
('scaler', StandardScaler()), ('model', Ridge(alpha=0.001))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Fitted attributes
11 features
| 1 |
| x0 |
| x0^2 |
| x0^3 |
| x0^4 |
| x0^5 |
| x0^6 |
| x0^7 |
| x0^8 |
| x0^9 |
| x0^10 |
Parameters
Fitted attributes
11 features
| x0 |
| x1 |
| x2 |
| x3 |
| x4 |
| x5 |
| x6 |
| x7 |
| x8 |
| x9 |
| x10 |
Parameters
Fitted attributes
# ¿cuál es el score sobre los datos de entrenamiento?
model_10_ridge.score(x_train, y_train)
0.9728003574124893
# ¿cuál es el score sobre los datos de test?
model_10_ridge.score(x_test, y_test)
0.8762430489487874
model_10.named_steps['model'].coef_
array([ 0.00000000e+00, -2.33114139e-01, 3.94319098e+01, -2.54326370e+02,
6.12383498e+02, -5.38141998e+02, -2.15129994e+02, 5.04521036e+02,
2.07668725e+02, -5.92221950e+02, 2.35487640e+02])
# Observa los coeficientes
model_10_ridge.named_steps['model'].coef_
array([ 0. , 2.12074277, -5.03426724, -0.72828463, 1.42179304,
1.60445406, 1.00996397, 0.30152153, -0.23913149, -0.51434418,
-0.50884092])
# Grafica los resultados de train y test, así como el polinomio
plt.plot(x_train[:, 0], y_train, 'ob', label='Datos de entrenamiento')
plt.plot(x_test[:, 0], y_test, 'og', label='Datos de prueba')
x_model = np.linspace(0, 1, 100)
y_model = model_10_ridge.predict(x_model[:, None])
plt.plot(x_model, y_model, '-r', label='Modelo')
plt.plot(x_test[:, 0], model_10_ridge.predict(x_test), '*r', label='Predicciones')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid()
plt.show()
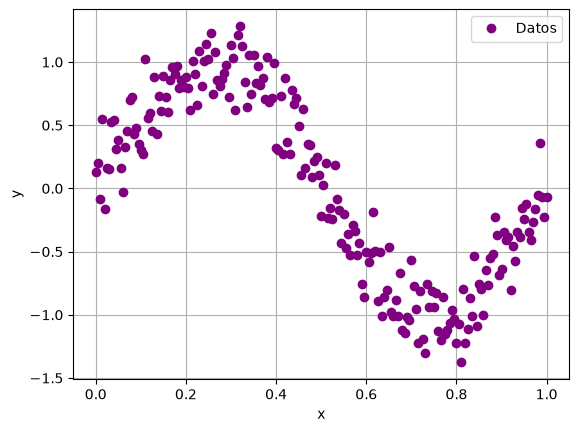
¿qué pasa si incrementamos la cantidad de datos de entrenamiento?
# Genera N=201
N = 201
x = np.linspace(0, 1, N)
y = np.sin(2 * np.pi * x) + np.random.normal(0, 0.2, N)
# Grafica la nube de puntos
plt.plot(x, y, 'o', label='Datos', color='purple')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid()
plt.show()
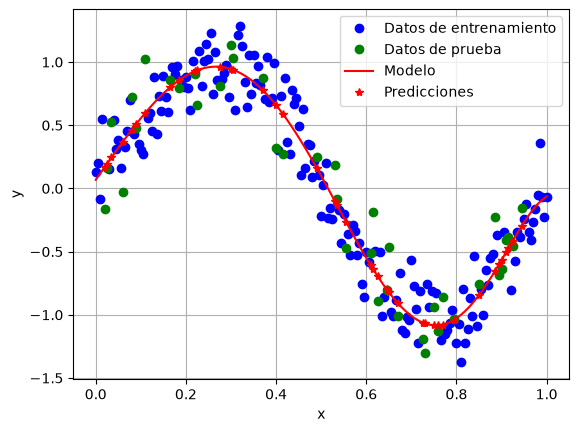
# Separa en train/test
x_train, x_test, y_train, y_test = train_test_split(x[:, None], y, test_size=0.2, random_state=0)
#
model_10_ridge.fit(x_train, y_train)
Pipeline(steps=[('features', PolynomialFeatures(degree=10)),
('scaler', StandardScaler()), ('model', Ridge(alpha=0.001))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Fitted attributes
11 features
| 1 |
| x0 |
| x0^2 |
| x0^3 |
| x0^4 |
| x0^5 |
| x0^6 |
| x0^7 |
| x0^8 |
| x0^9 |
| x0^10 |
Parameters
Fitted attributes
11 features
| x0 |
| x1 |
| x2 |
| x3 |
| x4 |
| x5 |
| x6 |
| x7 |
| x8 |
| x9 |
| x10 |
Parameters
Fitted attributes
# Compara los scores de train y test
train_score = model_10_ridge.score(x_train, y_train)
test_score = model_10_ridge.score(x_test, y_test)
print(f"Train score: {train_score:.3f}, Test score: {test_score:.3f}")
Train score: 0.938, Test score: 0.909
# Grafica los resultados de train y test, así como el polinomio
plt.plot(x_train[:, 0], y_train, 'ob', label='Datos de entrenamiento')
plt.plot(x_test[:, 0], y_test, 'og', label='Datos de prueba')
x_model = np.linspace(0, 1, 100)
y_model = model_10_ridge.predict(x_model[:, None])
plt.plot(x_model, y_model, '-r', label='Modelo')
plt.plot(x_test[:, 0], model_10_ridge.predict(x_test), '*r', label='Predicciones')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid()
plt.show()
Sobre overfitting
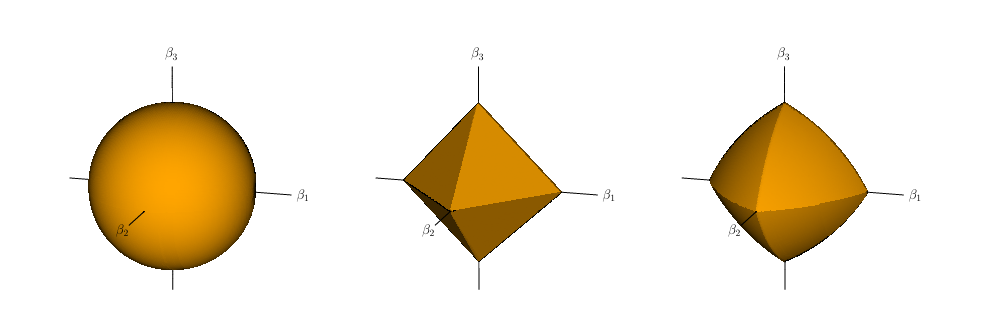
Figura 1: Lo que muestra es cómo se ven las “bolas de restricción” (constraint balls) en 3D para distintos tipos de regularización: Ridge “encoge” los coeficientes pero difícilmente los lleva exactamente a cero; En Lasso, algunos coeficientes se vuelven exactamente cero; Elastic Net combina ambas propiedades. Hastie, et al., 2020; Disponible en: https://arxiv.org/html/2006.00371v2.
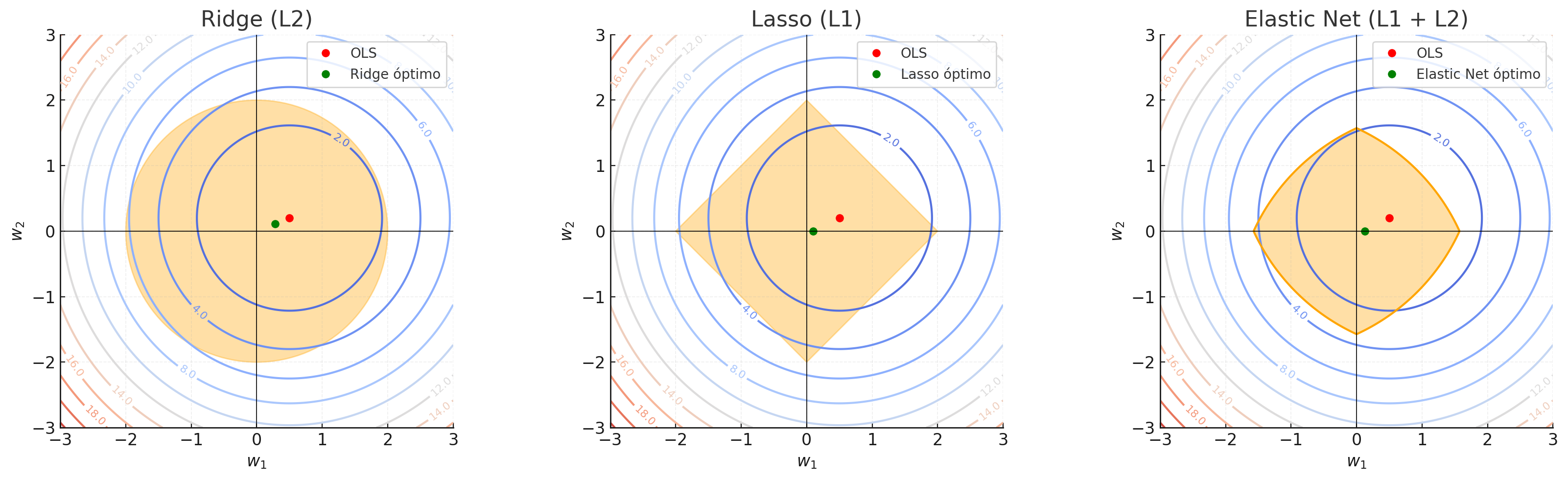
Punto rojo (OLS): mínimo sin regularización (en el centro de los contornos).
Punto verde (óptimo): solución con regularización:
Ridge (L2):
\(w^* \;=\; \frac{\mu}{1 + \lambda_2}\) → los coeficientes se encogen hacia el origen (shrinkage).Lasso (L1):
\(w^* \;=\; \text{soft}(\mu, \tfrac{\lambda_1}{2})\) → algunos coeficientes se reducen a 0 (sparsity).Elastic Net (L1+L2):
\(w^* \;=\; \frac{1}{1 + \lambda_2}\,\text{soft}(\mu, \tfrac{\lambda_1}{2})\) → combinación: shrinkage (L2) + sparsity (L1).
Para más información acerca de regularización y overfitting:
Hastie, T. (2020). Ridge Regularization: an Essential Concept in Data Science. Stanford University. arXiv.
Perspectiva probabilística#
En OLS definimos el error de ajuste de manera puramente geométrica, como la suma de cuadrados de los residuos.
En cambio, en el enfoque probabilístico de Máxima Verosimilitud (MLE), partimos de un modelo:
Esto implica que, dado \(x\), la variable de salida \(y\) sigue una distribución normal:
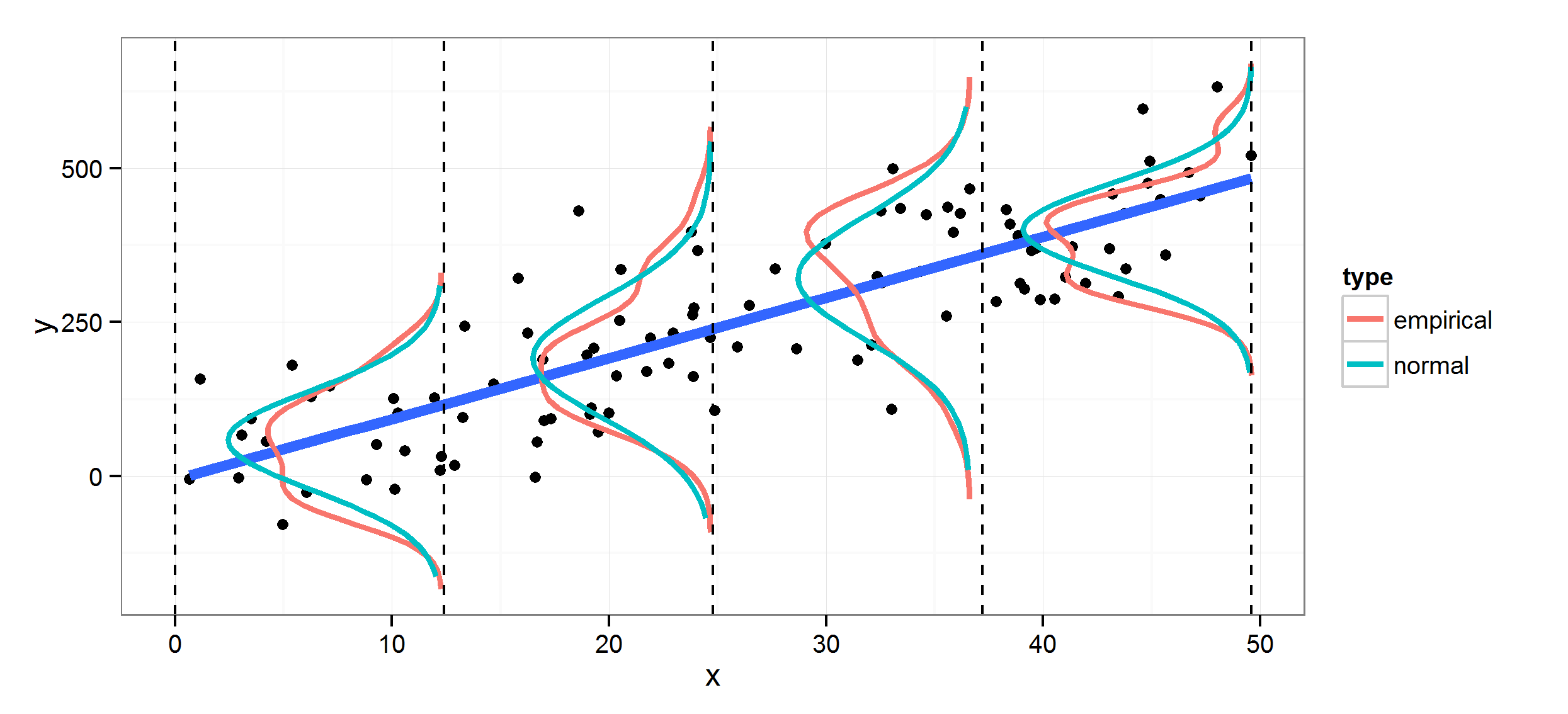
Figura 1: Los puntos negros representan las observaciones \((x_i, y_i)\).
La línea azul es el valor esperado del modelo \(\phi(x)^\top w\).
Las curvas rojas muestran la distribución empírica de los residuos, mientras que las curvas turquesa representan la distribución normal teórica asumida \(\mathcal{N}(0, \beta^{-1})\).
La figura ilustra que \(p(y \mid x,w) \sim \mathcal{N}(\phi(x)^\top w, \beta^{-1})\), es decir, los datos se distribuyen alrededor de la recta con ruido gaussiano.
Asumiendo independencia entre las observaciones, la función de verosimilitud es:
y su logaritmo:
Finalmente, maximizar \(\ell(w)\) respecto a \(w\) es equivalente a minimizar:
que es exactamente el mismo criterio de OLS.
Así, OLS surge como un caso particular de MLE bajo el supuesto de ruido gaussiano.
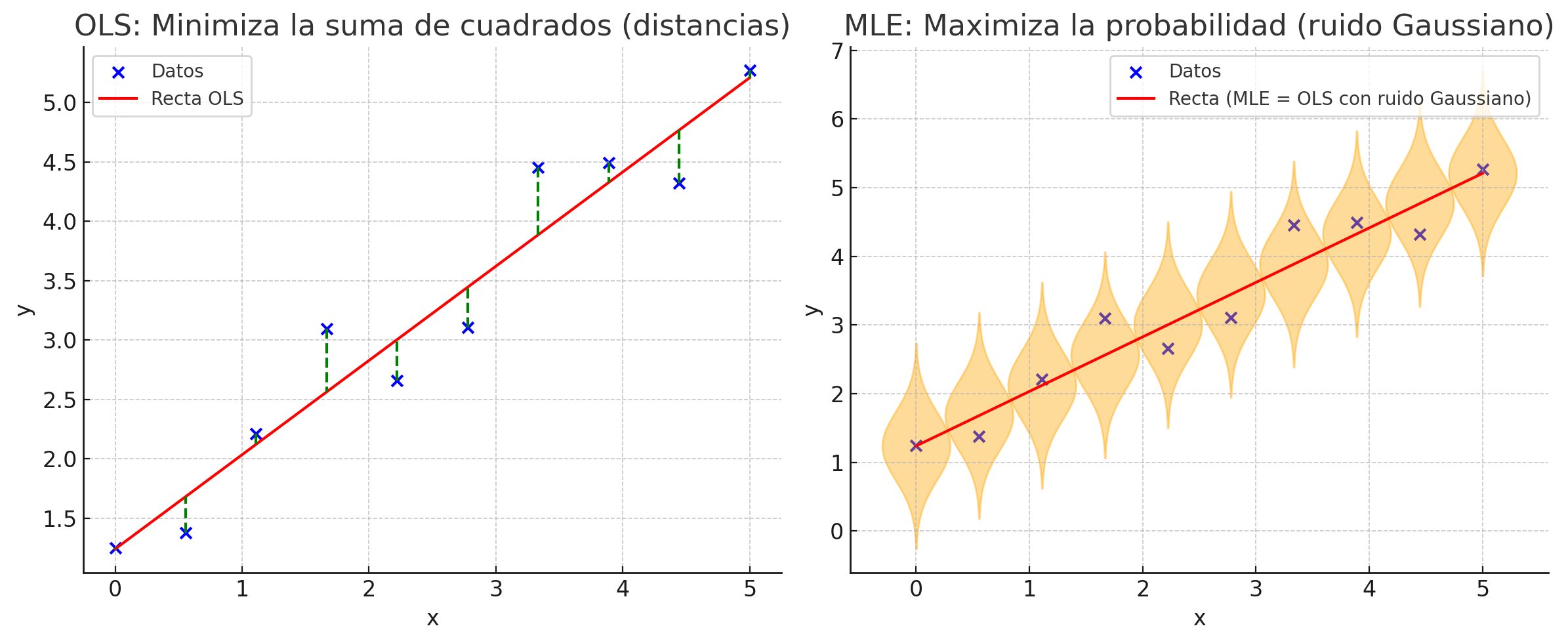
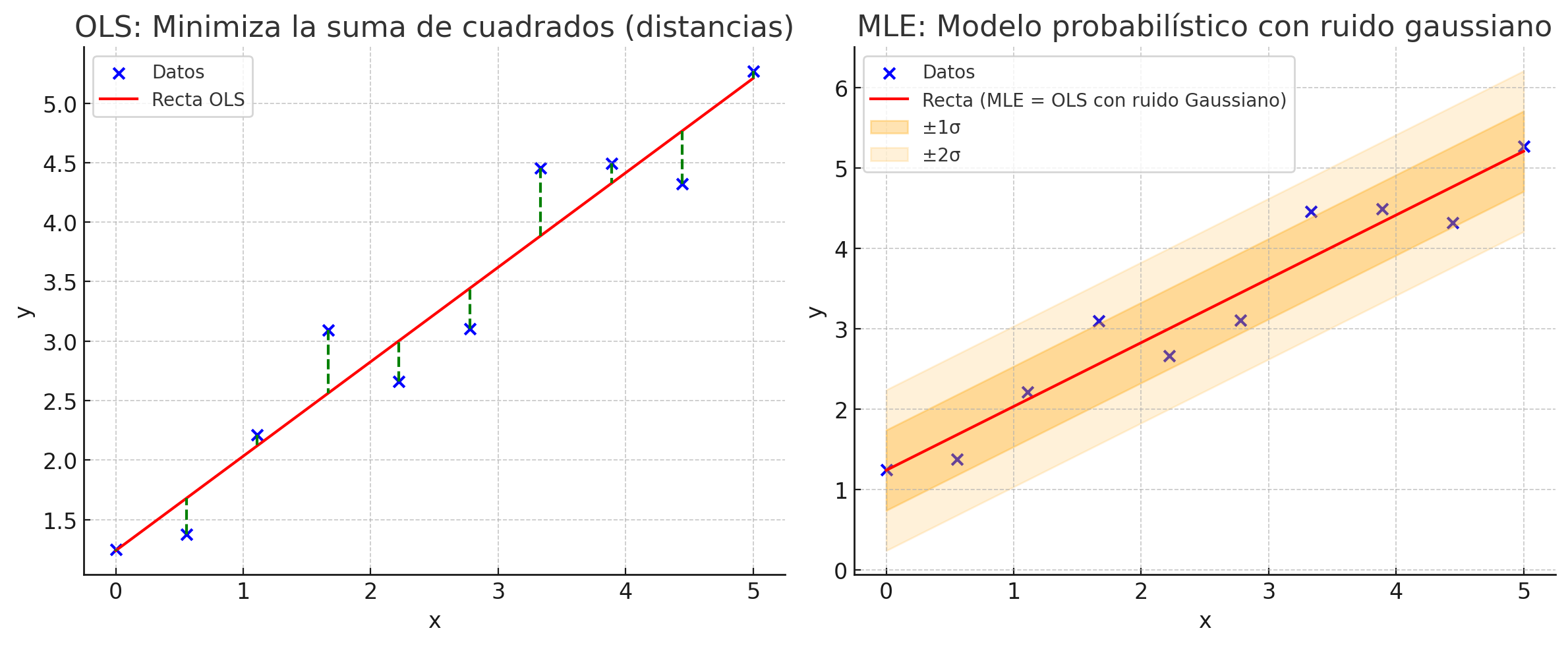
Observamos que la estimación de parámetros por máxima verosimilitud, explica nuestra intuición detrás de mínimos cuadrados.
Además, una vez más concluimos que el enfoque de máxima verosimilitud nos puede traer problemas de overfitting.