Sesión 8#
Modelos de regresión lineal#
Objetivos:
Revisitar modelos de predicción lineal desde una perspectiva de Montecarlo.
1. Predicción lineal#
Hasta ahora hemos trabajado con un modelo gaussiano para describir la altura en una población de adultos. Sin embargo, este modelo no incorpora aún un componente predictivo, es decir, una relación explícita entre la altura y otras variables que puedan explicarla.
Para ello introducimos el concepto de regresión, donde modelamos la media de la distribución (\(\mu_i\)) como una función de uno o más predictores, como el peso, la edad o el sexo de cada individuo.
En esta sección aprenderemos cómo incorporar predictores en el modelo de manera lineal.
Continuaremos con los datos de la población adulta, pero ahora analizaremos cómo la altura se relaciona con el peso.
import pandas as pd
import os
from scipy import stats
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings('ignore')
ruta = os.path.join('..', '..', '..', 'docs', 'source', 'data')
ruta_data = os.path.join(ruta, 'Howell1.csv')
df = pd.read_csv(ruta_data, sep=';')
df.head()
| height | weight | age | male | |
|---|---|---|---|---|
| 0 | 151.765 | 47.825606 | 63.0 | 1 |
| 1 | 139.700 | 36.485807 | 63.0 | 0 |
| 2 | 136.525 | 31.864838 | 65.0 | 0 |
| 3 | 156.845 | 53.041914 | 41.0 | 1 |
| 4 | 145.415 | 41.276872 | 51.0 | 0 |
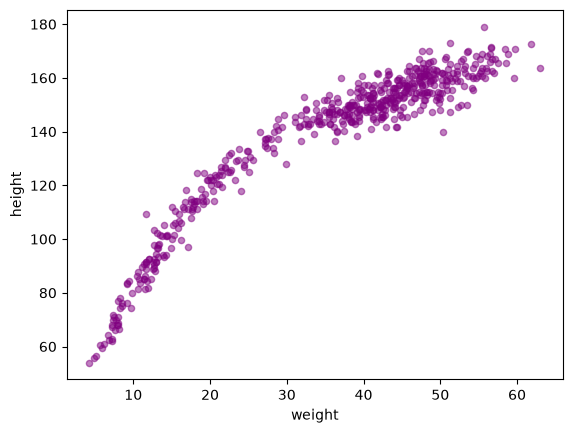
df.plot.scatter(x='weight',
y='height',
color='purple',
alpha=0.5)
<Axes: xlabel='weight', ylabel='height'>
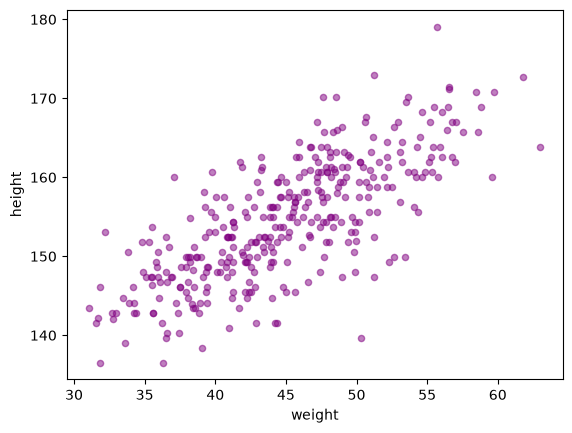
adultos = df[df.age >= 18].copy()
adultos.plot.scatter(x='weight',
y='height',
color='purple',
alpha=0.5)
<Axes: xlabel='weight', ylabel='height'>
Peso → es la variable predictora (o variable independiente).
Altura → es la variable respuesta (o dependiente).
adultos.describe()
| height | weight | age | male | |
|---|---|---|---|---|
| count | 352.000000 | 352.000000 | 352.000000 | 352.000000 |
| mean | 154.597093 | 44.990486 | 41.138494 | 0.468750 |
| std | 7.742332 | 6.456708 | 15.967855 | 0.499733 |
| min | 136.525000 | 31.071052 | 18.000000 | 0.000000 |
| 25% | 148.590000 | 40.256290 | 28.000000 | 0.000000 |
| 50% | 154.305000 | 44.792210 | 39.000000 | 0.000000 |
| 75% | 160.655000 | 49.292693 | 51.000000 | 1.000000 |
| max | 179.070000 | 62.992589 | 88.000000 | 1.000000 |
Del gráfico anterior observamos que existe una relación clara entre la altura y el peso. En otras palabras, conocer el peso de una persona nos puede ayudar a predecir su altura.
¿Cómo incorporamos el peso como predictor en el modelo de altura?#
En el modelo gaussiano original, la altura de todas las personas se describe con la misma media \(\mu\). Pero si creemos que la altura cambia con el peso, entonces esa media no debería ser fija.
Por eso, hacemos que \(\mu\) dependa linealmente del peso:
Finalmente, debemos asignar distribuciones previas a estos nuevos parámetros \((\alpha, \beta, \sigma)\) para reflejar nuestra incertidumbre antes de observar los datos.
(a) Modelo inicial#
Planteamiento del modelo sin predictores
En el modelo inicial, asumíamos que todas las personas tienen la misma media \(\mu\) para la altura:
donde \(\mu\) es la altura promedio de toda la población.
El nuevo planteamiento
Sabemos que la altura depende del peso.
Entonces, ya no queremos que \(\mu\) sea constante, sino que cambie según el peso de cada persona \(w_i\).
Para eso, hacemos que \(\mu_i\) (la media para cada persona \(i\)) depende linealmente del peso:
Esa relación \(\alpha + \beta\) es la forma típica de un modelo lineal, una recta con:
intercepto \(\alpha\)
pendiente \(\beta\)
predictor \(w_i - \bar{w}\) (peso centrado)
(b) modelo con peso como predictor#
Sea \(w_i\) el peso de la persona \(i\) y \(\bar{w}\) el promedio de todos los pesos. Definimos:
En este nuevo modelo,
\(\alpha\) representa la altura promedio cuando el peso está en su media.
\(\beta\) indica cuánto cambia la altura en promedio por cada unidad de cambio en el peso.
¿Qué significa lo anterior?
Como antes, representa la verosimilitud, es decir, la probabilidad de los datos observados. La diferencia es que ahora sustituimos la media general \(\mu\) por una media específica \(\mu_i\) para cada observación.
En otras palabras, la media ya no es constante, sino que depende del valor del predictor de cada individuo.
Aquí, \(\mu_i\) ya no es una parámetro aleatorio, sino una relación determinista entre los nuevos parámetros \(\alpha\) y \(\beta\) y la variable observada \(w_i\) (peso). Por eso usamos el símbolo «=» en lugar de «\(\sim\)».
El parámetro \(\beta\) representa el cambio esperado en la altura cuando el peso aumenta en una unidad (por ejemplo, 1 kg).
Demás expresiones
Corresponden a las previas de los parámetros. Como en los modelos anteriores, pueden ajustarse con ayuda de simulaciones predictivas previas, para asegurar que los valores iniciales sean razonables.
Curiosidades 💡
En el modelo bayesiano, el error no desaparece: está “dentro” de la distribución normal.
\(\sigma\) mide cuánta incertidumbre o ruido hay alrededor de la línea promedio.
Enfoque |
Expresión |
Cómo representa el error |
|---|---|---|
Mínimos cuadrados |
\(h_i = \alpha + \beta x_i + \varepsilon_i\) |
\(\varepsilon_i\) es el error explícito |
Bayesiano / Probabilístico |
\(h_i \sim \text{Normal}(\mu_i, \sigma)\) |
\(\sigma\) controla la variabilidad (error implícito) |
(c) Simulación previa predictiva#
N = 100
w = adultos.weight.values
w_bar = np.mean(w)
print(w[:10])
print(w.shape)
[47.8256065 36.4858065 31.864838 53.0419145 41.276872 62.992589
38.2434755 55.4799715 34.869885 54.487739 ]
(352,)
w_bar
np.float64(44.99048551988636)
# Muestrar las distribuciones previas
# alpha ~ Normal(170, 20)
alpha_samples = stats.norm.rvs(loc=170,
scale=20,
size=N)
# beta ~ Normal(0, 10)
beta_samples = stats.norm.rvs(loc=0,
scale=10,
size=N)
# sigma ~ Uniform(0, 50)
sigma_samples = stats.uniform.rvs(loc=0,
scale=50,
size=N)
# print samples
print(alpha_samples.shape)
print(beta_samples.shape)
print(sigma_samples.shape)
(100,)
(100,)
(100,)
# Relación lineal de la altura promedio con el peso
mu = alpha_samples + beta_samples * (w - w_bar).reshape(-1, 1)
# print mu shape
print(mu.shape)
(352, 100)
mu
array([[158.35278242, 166.23374814, 139.6284435 , ..., 106.64882367,
208.42926684, 151.24214104],
[171.87054968, 189.40781461, 226.51105626, ..., 343.79094303,
118.6832795 , 239.21567152],
[177.37903984, 198.85124669, 261.91572096, ..., 440.42635666,
82.11178965, 275.0648852 ],
...,
[153.18223644, 157.36966771, 106.39584412, ..., 15.94196301,
242.757107 , 117.59226563],
[150.91801043, 153.48801158, 91.84300648, ..., -23.77934198,
257.78955988, 102.85669927],
[152.74290901, 156.61651055, 103.5721592 , ..., 8.23484413,
245.67385158, 114.73312589]], shape=(352, 100))
# Muestrar la distribución de la altura
# height ~ Normal(mu, sigma)
height_samples = stats.norm.rvs(loc=mu,
scale=sigma_samples)
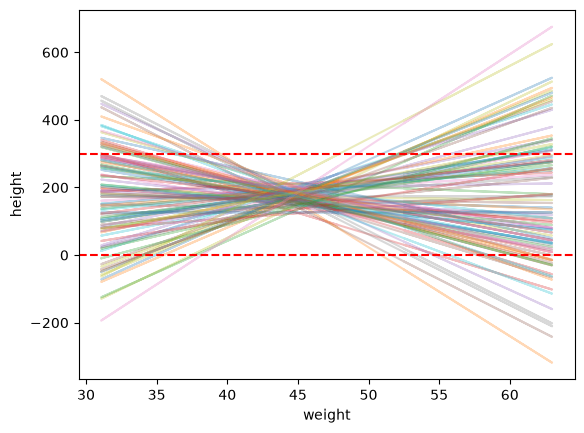
# Graficamos la altura promedio vs el peso
plt.plot(w, mu, alpha=0.3)
plt.axhline(y=0, color='r', linestyle='--')
plt.axhline(y=300, color='r', linestyle='--')
plt.xlabel('weight')
plt.ylabel('height')
plt.show()
Mejorando las distribuciones previas#
Con las distribuciones previas que usamos antes, la altura promedio podía tomar valores poco realistas, incluso para pesos dentro del rango normal. Podemos mejorar esto ajustando nuestras suposiciones iniciales.
Al observar el gráfico de dispersión, notamos que la relación entre altura y peso es positiva: las personas con mayor peso tienden a ser más altas.
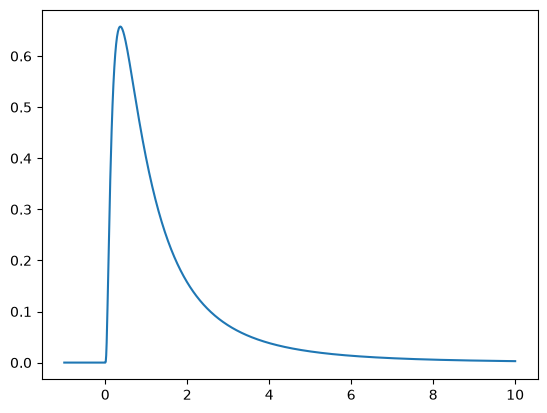
Para reflejar este conocimiento previo, podemos asegurar que el parámetro \(\beta\) (la pendiente) sea siempre positivo usando una distribución Log-Normal en lugar de una normal.
Esta distribución solo toma valores mayores que cero:
Esto significa que el logaritmo de \(\beta\) sigue una distribución normal con media 0 y desviación estándar 1.
En otras palabras, garantizamos que \(\beta > 0\), lo que representa de forma natural la relación positiva entre peso y altura.
# Densidad lognormal
beta = stats.lognorm(s=1)
x = np.linspace(-1, 10, 1001)
plt.plot(x, beta.pdf(x))
[<matplotlib.lines.Line2D at 0x7fab6f7ea5d0>]
# Simulación previa predictiva ahora con lognormal para beta
N=100
w = adultos.weight.values
w_bar = np.mean(w)
#---
alpha_samples = stats.norm.rvs(loc=170, scale=20, size=N)
beta_samples = beta.rvs(size=N) ## solo esto cambió
sigma_samples = stats.uniform.rvs(loc=0, scale=50, size=N)
#---
mu = alpha_samples + beta_samples * (w - w_bar).reshape(-1, 1)
#---
height_samples = stats.norm.rvs(loc=mu,
scale=sigma_samples)
# Graficamos la altura promedio vs el peso
plt.plot(w, mu, alpha=0.3)
plt.axhline(y=0, color='r', linestyle='--')
plt.axhline(y=300, color='r', linestyle='--')
plt.xlabel('weight')
plt.ylabel('height')
plt.show()
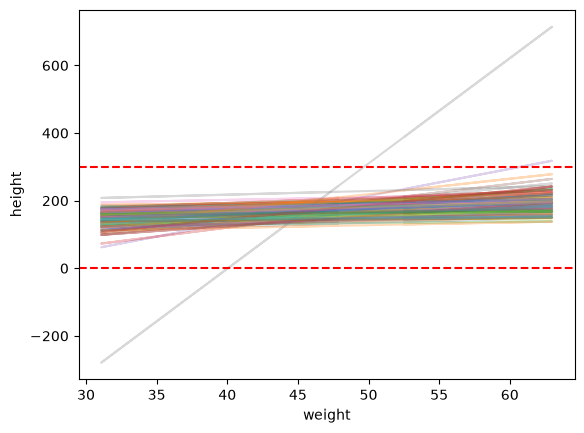
Simulación previa con la nueva distribución#
¡Esto se ve mucho mejor!
Después de cambiar la distribución previa de \(\beta\) a una Log-Normal, todas las pendientes son ahora positivas, reflejando correctamente que la altura aumenta con el peso.
En el gráfico, cada línea representa una posible relación entre peso y altura generada desde las distribuciones previas.
A diferencia del caso anterior, ahora todas las líneas tienen pendiente positiva y las alturas simuladas se concentran en un rango más razonable (entre 0 y 300 cm).
De forma que nuestro modelo completo es:
(d) Estimemos la distribución posterior usando MCMC#
import arviz as az
import pymc as pm
w = adultos.weight.values
w_bar = np.mean(w)
h = adultos.height.values
w.shape
(352,)
w_bar
np.float64(44.99048551988636)
h.shape
(352,)
# Modelo
with pm.Model() as modelo_lineal_altura:
# Sigma
sigma = pm.Uniform('sigma',
lower=0,
upper=50)
# Alpha
alpha = pm.Normal('alpha',
mu=170,
sigma=20)
# Beta
beta = pm.Lognormal('beta',
mu=0,
sigma=1)
# Mu
mu = pm.Deterministic('mu',
alpha + beta * (w - w_bar))
# altura
altura = pm.Normal('altura',
mu=mu,
sigma=sigma,
observed=h) # alturas de mis datos
# Muestreo
idata = pm.sample()
Initializing NUTS using jitter+adapt_diag...
Sequential sampling (2 chains in 1 job)
NUTS: [sigma, alpha, beta]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 2 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
idata
<xarray.DataTree>
Group: /
├── Group: /posterior
│ Dimensions: (chain: 2, draw: 1000, mu_dim_0: 352)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999
│ * mu_dim_0 (mu_dim_0) int64 3kB 0 1 2 3 4 5 6 ... 345 346 347 348 349 350 351
│ Data variables:
│ alpha (chain, draw) float64 16kB 154.2 154.0 154.6 ... 154.6 154.7 154.5
│ sigma (chain, draw) float64 16kB 5.364 5.306 5.157 ... 4.991 4.983 4.927
│ beta (chain, draw) float64 16kB 0.9109 0.9014 0.8961 ... 0.8972 0.918
│ mu (chain, draw, mu_dim_0) float64 6MB 156.8 146.5 ... 162.8 161.4
│ Attributes:
│ created_at: 2026-06-18T14:23:49.736375+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.0.1
│ sample_dims: ['chain', 'draw']
│ sampling_time: 1.525205135345459
│ tuning_steps: 1000
├── Group: /sample_stats
│ Dimensions: (chain: 2, draw: 1000)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999
│ Data variables: (12/18)
│ divergences (chain, draw) int64 16kB 0 0 0 0 0 0 ... 0 0 0 0 0 0
│ index_in_trajectory (chain, draw) int64 16kB -3 1 -1 -2 0 ... 1 3 -2 -1 1
│ tree_depth (chain, draw) int64 16kB 2 1 2 2 2 2 ... 2 1 2 2 2 2
│ lp (chain, draw) float64 16kB -1.08e+03 ... -1.079e+03
│ step_size (chain, draw) float64 16kB 0.8943 0.8943 ... 1.343
│ acceptance_rate (chain, draw) float64 16kB 0.9666 0.688 ... 0.9475
│ ... ...
│ energy (chain, draw) float64 16kB 1.081e+03 ... 1.079e+03
│ n_steps (chain, draw) float64 16kB 3.0 1.0 3.0 ... 3.0 3.0
│ max_energy_error (chain, draw) float64 16kB -0.2125 0.3739 ... 0.06322
│ diverging (chain, draw) bool 2kB False False ... False False
│ reached_max_treedepth (chain, draw) bool 2kB False False ... False False
│ perf_counter_diff (chain, draw) float64 16kB 0.0002031 ... 0.0002262
│ Attributes:
│ created_at: 2026-06-18T14:23:49.748159+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.0.1
│ sample_dims: ['chain', 'draw']
│ sampling_time: 1.525205135345459
│ tuning_steps: 1000
└── Group: /observed_data
Dimensions: (altura_dim_0: 352)
Coordinates:
* altura_dim_0 (altura_dim_0) int64 3kB 0 1 2 3 4 5 ... 347 348 349 350 351
Data variables:
altura (altura_dim_0) float64 3kB 151.8 139.7 136.5 ... 156.2 158.8
Attributes:
created_at: 2026-06-18T14:23:49.752504+00:00
creation_library: ArviZ
creation_library_version: 1.2.0
creation_library_language: Python
inference_library: pymc
inference_library_version: 6.0.1
sample_dims: []# Distribución posterior de los parámetros
az.plot_trace(idata, var_names=["alpha", "beta", "sigma"])
plt.tight_layout()

az.summary(idata, var_names=["alpha", "beta", "sigma"])
| mean | sd | eti89_lb | eti89_ub | ess_bulk | ess_tail | r_hat | mcse_mean | mcse_sd | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 154.606 | 0.27 | 150 | 160 | 3138 | 1732 | 1.00 | 0.0048 | 0.0035 |
| beta | 0.904 | 0.042 | 0.84 | 0.97 | 2882 | 1370 | 1.00 | 0.00079 | 0.00053 |
| sigma | 5.108 | 0.185 | 4.8 | 5.4 | 3152 | 1662 | 1.00 | 0.0033 | 0.0023 |
¿qué podríamos concluir?
La altura promedio es de 155 cm.
Por cada 1 kg adicional de peso, se espera que la altura aumente en alrededor de 0.9 cm.
La dispersión natural de las alturas es alrededor de 5.1 cm (simga)
Predicciones con la distribución posterior#
El objetivo principal de este modelo es realizar predicciones a partir de la distribución posterior de los parámetros.
Lo primero que podríamos hacer es tomar el promedio de las muestras de \(\alpha\) y \(\beta\) y graficar la relación promedio entre peso y altura:
# objeto de muestreo
idata
<xarray.DataTree>
Group: /
├── Group: /posterior
│ Dimensions: (chain: 2, draw: 1000, mu_dim_0: 352)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999
│ * mu_dim_0 (mu_dim_0) int64 3kB 0 1 2 3 4 5 6 ... 345 346 347 348 349 350 351
│ Data variables:
│ alpha (chain, draw) float64 16kB 154.2 154.0 154.6 ... 154.6 154.7 154.5
│ sigma (chain, draw) float64 16kB 5.364 5.306 5.157 ... 4.991 4.983 4.927
│ beta (chain, draw) float64 16kB 0.9109 0.9014 0.8961 ... 0.8972 0.918
│ mu (chain, draw, mu_dim_0) float64 6MB 156.8 146.5 ... 162.8 161.4
│ Attributes:
│ created_at: 2026-06-18T14:23:49.736375+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.0.1
│ sample_dims: ['chain', 'draw']
│ sampling_time: 1.525205135345459
│ tuning_steps: 1000
├── Group: /sample_stats
│ Dimensions: (chain: 2, draw: 1000)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999
│ Data variables: (12/18)
│ divergences (chain, draw) int64 16kB 0 0 0 0 0 0 ... 0 0 0 0 0 0
│ index_in_trajectory (chain, draw) int64 16kB -3 1 -1 -2 0 ... 1 3 -2 -1 1
│ tree_depth (chain, draw) int64 16kB 2 1 2 2 2 2 ... 2 1 2 2 2 2
│ lp (chain, draw) float64 16kB -1.08e+03 ... -1.079e+03
│ step_size (chain, draw) float64 16kB 0.8943 0.8943 ... 1.343
│ acceptance_rate (chain, draw) float64 16kB 0.9666 0.688 ... 0.9475
│ ... ...
│ energy (chain, draw) float64 16kB 1.081e+03 ... 1.079e+03
│ n_steps (chain, draw) float64 16kB 3.0 1.0 3.0 ... 3.0 3.0
│ max_energy_error (chain, draw) float64 16kB -0.2125 0.3739 ... 0.06322
│ diverging (chain, draw) bool 2kB False False ... False False
│ reached_max_treedepth (chain, draw) bool 2kB False False ... False False
│ perf_counter_diff (chain, draw) float64 16kB 0.0002031 ... 0.0002262
│ Attributes:
│ created_at: 2026-06-18T14:23:49.748159+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.0.1
│ sample_dims: ['chain', 'draw']
│ sampling_time: 1.525205135345459
│ tuning_steps: 1000
└── Group: /observed_data
Dimensions: (altura_dim_0: 352)
Coordinates:
* altura_dim_0 (altura_dim_0) int64 3kB 0 1 2 3 4 5 ... 347 348 349 350 351
Data variables:
altura (altura_dim_0) float64 3kB 151.8 139.7 136.5 ... 156.2 158.8
Attributes:
created_at: 2026-06-18T14:23:49.752504+00:00
creation_library: ArviZ
creation_library_version: 1.2.0
creation_library_language: Python
inference_library: pymc
inference_library_version: 6.0.1
sample_dims: []post_samples = idata.posterior.to_dataframe()
post_samples
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[32], line 1
----> 1 post_samples = idata.posterior.to_dataframe()
2 post_samples
File ~/checkouts/readthedocs.org/user_builds/modelos-graficos-probabilisticos/envs/v2026/lib/python3.13/site-packages/xarray/core/common.py:306, in AttrAccessMixin.__getattr__(self, name)
304 with suppress(KeyError):
305 return source[name]
--> 306 raise AttributeError(
307 f"{type(self).__name__!r} object has no attribute {name!r}"
308 )
AttributeError: 'DataTree' object has no attribute 'to_dataframe'
Después de ajustar el modelo, tenemos muchas muestras posteriores de los parámetros \(\alpha\), \(\beta\) y \(\sigma\), obtenidas del muestreador NUTS.
Cada muestra representa una posible versión del modelo compatible con los datos observados.
Entonces, cuando calculamos lo siguiente, lo que hacemos es usar los valores promedio de los parámetros para construir una sola línea representativa, la “relación promedio” entre peso y altura.
En términos estadísticos:
# relación promedio
alpha_avg = post_samples.alpha.mean()
beta_avg = post_samples.beta.mean()
mu_avg = alpha_avg + beta_avg * (w - w_bar)
print(alpha_avg)
154.59930547332058
print(beta_avg)
0.9029966249936888
print(mu_avg.shape)
(352,)
# -- scatter
plt.scatter(adultos.weight,
adultos.height,
alpha=0.5,
label='Datos observados')
# -- línea
plt.plot(w, mu_avg, color='red', label='Relación promedio')
plt.xlabel('weight (kg)')
plt.ylabel('height (cm)')
plt.legend()
<matplotlib.legend.Legend at 0x118f8a900>
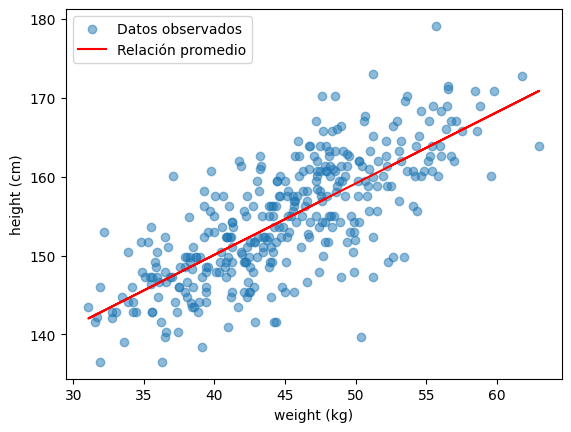
Línea roja:
Técnicamente es la línea que corresponde al promedio de \(\alpha\) y \(\Beta\) o, la línea que representa la relación promedio entre peso y altura según la posterior.
Franja de incertidumbre
Sin embargo, el modelo no solo nos da una única línea, sino también una incertidumbre sobre esa relación.
Podemos visualizarla muestreando varias combinaciones de \(\alpha\) y \(\beta\) desde la distribución posterior y graficando las líneas resultantes.
Estas líneas representan distintas relaciones posibles entre el peso y la altura, según la información contenida en los datos y la variabilidad del modelo.
posterior_samples = post_samples.sample(500)
post_mu = posterior_samples.alpha.values + posterior_samples.beta.values * (w - w_bar).reshape(-1, 1)
# -- scatter
plt.scatter(adultos.weight,
adultos.height,
alpha=0.5,
label='Datos observados')
# -- líneas
plt.plot(w, post_mu, color='black', alpha=0.1)
plt.plot(w, mu_avg, color='red', label='Relación promedio')
plt.xlabel('weight (kg)')
plt.ylabel('height (cm)')
plt.legend()
<matplotlib.legend.Legend at 0x12894b9d0>
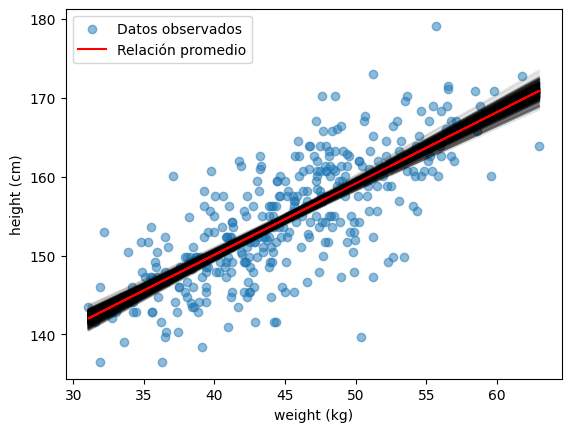
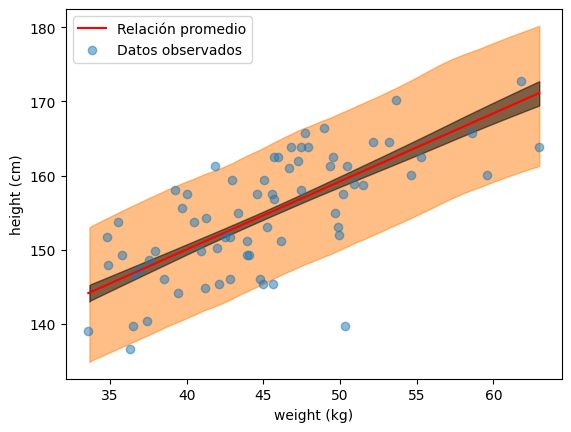
Interpretación del gráfico#
En la figura se muestran los datos observados (puntos azules) junto con las predicciones del modelo:
Línea roja: la relación promedio representa la tendencia central del modelo, calculada usando el valor medio de los parámetros posteriores (\(E[\alpha]\) y \(E[\beta]\)).
Esta línea indica cuánto se espera que aumente la altura por cada kilogramo adicional de peso, según lo que el modelo aprednió de los datos.Líneas negras semitransparentes: (la incertidumbre sobre esa relación) Cada línea negra es una versión posible de la relación entre peso y altura, obtenida muestreando distintas combinaciones de \(\alpha\) y \(\beta\) desde la distribución posterior.
Que estén tan juntas significa que los datos fueron suficientes para que elmodelo tenga mucha certeza sobre cómo se relaciona peso y altura.
Preguntas que nos podríamos hacer#
¿Cuánto es la altura promedio de una persona de 60 kg?
Usaremos las muestras de la posterior para responder esta pregunta.
post_samples.shape
(1408000, 4)
post_samples.head()
| alpha | sigma | beta | mu | |||
|---|---|---|---|---|---|---|
| chain | draw | mu_dim_0 | ||||
| 0 | 0 | 0 | 154.583738 | 4.958618 | 0.869354 | 157.048461 |
| 1 | 154.583738 | 4.958618 | 0.869354 | 147.190165 | ||
| 2 | 154.583738 | 4.958618 | 0.869354 | 143.172909 | ||
| 3 | 154.583738 | 4.958618 | 0.869354 | 161.583278 | ||
| 4 | 154.583738 | 4.958618 | 0.869354 | 151.355295 |
# Promediar sobre mu_dim_0
posterior_reduced = post_samples.groupby(["chain", "draw"])[["alpha", "beta", "sigma"]].mean().reset_index()
posterior_reduced
| chain | draw | alpha | beta | sigma | |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 154.583738 | 0.869354 | 4.958618 |
| 1 | 0 | 1 | 154.509082 | 0.950118 | 5.448984 |
| 2 | 0 | 2 | 154.333630 | 0.886316 | 5.002482 |
| 3 | 0 | 3 | 154.923305 | 0.926352 | 5.162237 |
| 4 | 0 | 4 | 154.335521 | 0.871423 | 5.107468 |
| ... | ... | ... | ... | ... | ... |
| 3995 | 3 | 995 | 154.430511 | 0.949348 | 5.148892 |
| 3996 | 3 | 996 | 154.792452 | 0.904513 | 4.931123 |
| 3997 | 3 | 997 | 154.507527 | 0.896187 | 5.305716 |
| 3998 | 3 | 998 | 154.455009 | 0.945847 | 4.801142 |
| 3999 | 3 | 999 | 154.602111 | 0.890257 | 5.389640 |
4000 rows × 5 columns
# calcular mu a 60 kg
mu_60 = posterior_reduced["alpha"].values + posterior_reduced["beta"].values * (60 - w_bar)
mu_60.shape
(4000,)
az.plot_kde(mu_60)
<Axes: >
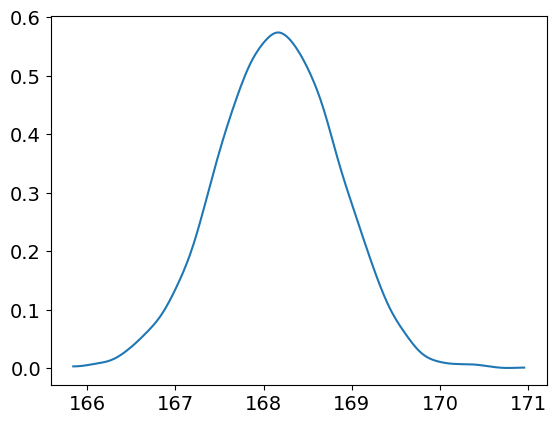
az.summary(mu_60, hdi_prob=0.89)
arviz - WARNING - Shape validation failed: input_shape: (1, 4000), minimum_shape: (chains=2, draws=4)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| x | 168.153 | 0.679 | 167.074 | 169.219 | 0.009 | 0.011 | 5562.0 | 3337.0 | NaN |
Diferencia entre la posterior y la posterior predictiva#
Más a fondo... 💡
Posterior#
En la posterior, el modelo estima la distribución de los parámetros
\(\alpha, \beta, \sigma\) dados los datos observados:
Con esas muestras podemos calcular la altura media esperada para cada persona:
Esto describe la incertidumbre sobre la recta promedio,
pero no incluye todavía la variabilidad natural de las alturas individuales.
Posterior predictiva#
La posterior predictiva usa esas mismas muestras de la posterior para simular cómo se verían nuevos datos reales si repitiéramos el experimento:
Aquí el modelo agrega la variabilidad individual ((\(\sigma\))), lo que genera la banda naranja: una franja más ancha que refleja la dispersión esperada de las alturas reales.
Concepto |
Qué muestra |
Fórmula principal |
Banda en el gráfico |
|---|---|---|---|
Posterior |
Incertidumbre sobre los parámetros y la recta promedio |
\( \mu_i = \alpha + \beta (w_i - \bar{w}) \) |
Banda angosta |
Posterior predictiva |
Incertidumbre sobre los datos reales (media + ruido) |
\( h_i \sim \text{Normal}(\mu_i, \sigma) \) |
Banda ancha (naranja) |
(e) ¿y, \(\sigma\)?#
Recordemos que el modelo completo para la altura es:
Hasta ahora nos hemos enfocado en \(\mu_i\), que representa la altura promedio esperada para una persona con cierto peso.
Sin embargo, el modelo también incluye la variabilidad de las alturas alrededor de ese promedio y esa variabilidad está controlada por el parámetro \(\sigma\).
with modelo_lineal_altura:
idata.extend(pm.sample_posterior_predictive(idata))
Sampling: [altura]
idata
-
<xarray.Dataset> Size: 11MB Dimensions: (chain: 4, draw: 1000, mu_dim_0: 352) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 * mu_dim_0 (mu_dim_0) int64 3kB 0 1 2 3 4 5 6 ... 345 346 347 348 349 350 351 Data variables: alpha (chain, draw) float64 32kB 154.6 154.5 154.3 ... 154.5 154.5 154.6 sigma (chain, draw) float64 32kB 4.959 5.449 5.002 ... 5.306 4.801 5.39 beta (chain, draw) float64 32kB 0.8694 0.9501 0.8863 ... 0.9458 0.8903 mu (chain, draw, mu_dim_0) float64 11MB 157.0 147.2 ... 162.7 161.3 Attributes: created_at: 2026-03-24T01:43:37.932342+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.43680691719055176 tuning_steps: 1000 -
<xarray.Dataset> Size: 11MB Dimensions: (chain: 4, draw: 1000, altura_dim_0: 352) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 993 994 995 996 997 998 999 * altura_dim_0 (altura_dim_0) int64 3kB 0 1 2 3 4 5 ... 347 348 349 350 351 Data variables: altura (chain, draw, altura_dim_0) float64 11MB 155.5 149.2 ... 169.5 Attributes: created_at: 2026-03-24T02:30:52.059447+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 -
<xarray.Dataset> Size: 528kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: (12/18) divergences (chain, draw) int64 32kB 0 0 0 0 0 0 ... 0 0 0 0 0 0 acceptance_rate (chain, draw) float64 32kB 0.9569 0.7774 ... 0.7136 n_steps (chain, draw) float64 32kB 3.0 3.0 3.0 ... 3.0 3.0 index_in_trajectory (chain, draw) int64 32kB -3 2 -1 -3 2 ... -1 1 1 1 -2 reached_max_treedepth (chain, draw) bool 4kB False False ... False False max_energy_error (chain, draw) float64 32kB 0.1385 0.4396 ... 0.4812 ... ... process_time_diff (chain, draw) float64 32kB 7.7e-05 ... 6.9e-05 diverging (chain, draw) bool 4kB False False ... False False energy (chain, draw) float64 32kB 1.08e+03 ... 1.082e+03 lp (chain, draw) float64 32kB -1.079e+03 ... -1.08e+03 tree_depth (chain, draw) int64 32kB 2 2 2 2 2 2 ... 2 2 2 2 2 2 largest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan Attributes: created_at: 2026-03-24T01:43:37.939608+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.43680691719055176 tuning_steps: 1000 -
<xarray.Dataset> Size: 6kB Dimensions: (altura_dim_0: 352) Coordinates: * altura_dim_0 (altura_dim_0) int64 3kB 0 1 2 3 4 5 ... 347 348 349 350 351 Data variables: altura (altura_dim_0) float64 3kB 151.8 139.7 136.5 ... 156.2 158.8 Attributes: created_at: 2026-03-24T01:43:37.941573+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1
Cómo se genera la posterior predictiva
PyMC genera la posterior predictiva usando las muestras de la distribución posterior del modelo. Este proceso consiste en simular nuevos datos basados en los parámetros muestreados previamente.
(A) Toma todos los parámetros muestreados de la posterior
Cada conjunto de parámetros \((\alpha^{(s)}, \beta^{(s)}, \sigma^{(s)})\) representa un posible “mundo” que explica los datos observados.
(B) Para cada observación \(i = 1 \dots 352\)
Calcula el valor medio predicho:
Donde:
\(w_i\): peso de la persona \(i\)
\(\bar{w}\): promedio de los pesos
\(\mu_i^{(s)}\): altura media esperada bajo ese conjunto de parámetros
(C) Luego simula un nuevo dato (una “altura nueva”)
Esto significa que se genera una altura simulada tomando como media \(\mu_i^{(s)}\) y usando el mismo nivel de ruido \(\sigma^{(s)}\) del modelo.
Resultado
De esta forma se obtiene una matriz tridimensional de simulaciones:
En este caso: (4, 1000, 352)
from IPython.display import SVG, display
import os
r = os.path.join('..', 'images', 'tensor_posterior_predictiva.svg')
display(SVG(filename=r))

Eje 1 (chains = 4): las 4 cademas del sampler
Eje 2 (draws = 1000): las 1000 muestras por cadena
Eje 3 (obs = 352)_ las 352 personas de nuestro conjunto de datos
Cada celda contiene una altura simulada no solo \(\mu\), sino un valor de \(y\) sacado de \(N(\mu, \sigma\)). Es decir, 4 x 1000 = 4000 «mundos posibles», y en cada mundo tienes una altura predicha para cada persona.
En conjunto: para cada cadena y cada draw, el modelo genera una predicción de altura para las 352 observaciones.
y_pred1 = idata.posterior_predictive["altura"]
y_pred1
<xarray.DataArray 'altura' (chain: 4, draw: 1000, altura_dim_0: 352)> Size: 11MB
array([[[155.54188145, 149.1999761 , 142.28644988, ..., 160.47841347,
161.87339538, 162.8992885 ],
[157.52956317, 145.02851955, 144.42664485, ..., 158.17823704,
161.33630064, 159.90675144],
[160.55918473, 140.26010029, 143.82518863, ..., 161.30539888,
155.93715291, 157.72936699],
...,
[157.03604918, 146.90291618, 150.17610802, ..., 159.01195642,
167.61400594, 165.59044814],
[164.40365601, 150.549754 , 143.89506901, ..., 153.36488511,
158.57181929, 165.40538385],
[161.29329051, 152.37097902, 145.12138646, ..., 155.64044552,
158.14091316, 166.10591367]],
[[168.13174515, 149.66030182, 142.50195737, ..., 163.47695671,
159.7167626 , 163.58621542],
[153.23848356, 145.6560458 , 143.67827789, ..., 172.34629672,
160.15887709, 156.97951496],
[159.79967877, 156.38211617, 139.72383744, ..., 163.89449251,
160.30827133, 163.29899833],
...
[168.19158383, 147.54320144, 139.91202874, ..., 158.66084564,
166.89281276, 158.82649118],
[148.50438755, 144.81099412, 146.77138081, ..., 160.55136172,
167.82663344, 165.65143475],
[154.19188052, 148.34283201, 141.10913614, ..., 164.51247654,
161.55389014, 155.70460027]],
[[156.69141367, 145.75185986, 137.15217567, ..., 159.2421364 ,
159.16149982, 151.09460898],
[153.36644798, 152.32316138, 146.40001253, ..., 165.37512596,
161.00824032, 171.93703154],
[156.75216449, 144.72280914, 147.36750434, ..., 165.67578005,
168.98787636, 162.59130962],
...,
[158.43119301, 153.21425611, 141.58891208, ..., 164.47586882,
160.90773016, 158.46212098],
[160.99549232, 156.96759062, 145.62754201, ..., 152.28787045,
155.55114376, 169.98230489],
[150.40926851, 143.0599431 , 144.08502764, ..., 160.16157558,
157.03217247, 169.53871612]]], shape=(4, 1000, 352))
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 993 994 995 996 997 998 999
* altura_dim_0 (altura_dim_0) int64 3kB 0 1 2 3 4 5 ... 347 348 349 350 351draw0 = y_pred1.sel(chain=0, draw=0)
draw0
<xarray.DataArray 'altura' (altura_dim_0: 352)> Size: 3kB
array([155.54188145, 149.1999761 , 142.28644988, 170.72083391,
151.66167905, 171.75734513, 146.97146631, 174.38421272,
145.97439907, 156.71477264, 151.82573435, 152.81284556,
148.3718482 , 150.04651904, 139.51832233, 154.39106493,
150.10332883, 160.07781266, 159.72604425, 148.02421912,
138.51320249, 145.33737158, 146.75860368, 158.29736668,
166.01864656, 148.71585223, 144.38659886, 156.96194961,
147.29065028, 144.30576945, 160.90332086, 160.76562733,
153.27101212, 162.73680004, 170.45794345, 159.06634172,
161.67906519, 144.37157568, 154.60672007, 154.10625601,
149.6658362 , 169.81852755, 154.08851141, 155.73214071,
160.92672257, 162.039318 , 142.48808456, 161.30689316,
164.93021588, 153.88636286, 151.0389744 , 154.06513952,
150.03532738, 162.928374 , 146.77157945, 155.15515606,
141.51680218, 158.07257186, 153.06686322, 163.65168186,
143.19057866, 147.00417615, 156.94685014, 159.50039146,
151.10921097, 159.83086281, 151.42256649, 145.63889698,
156.24561409, 156.13682065, 162.17317293, 167.15066085,
150.41567685, 154.43574051, 151.09279185, 161.03512135,
161.8799461 , 151.73152858, 151.13957602, 146.5063729 ,
...
161.21827896, 150.31432458, 146.28112847, 153.46667361,
155.66306991, 145.99338314, 163.9737241 , 147.88621835,
147.17830682, 151.10111531, 152.01348094, 149.99647878,
143.14783863, 150.92545315, 152.83719505, 165.1627013 ,
142.1186611 , 165.08906601, 153.42118684, 159.18071331,
159.82840008, 162.942043 , 154.51097822, 143.58365127,
145.41991338, 148.27528162, 161.24609141, 157.84049371,
144.04663852, 156.12807402, 148.70888769, 151.1808927 ,
166.5424364 , 161.73915301, 155.35016374, 157.76805343,
149.18203015, 166.98277176, 153.49435718, 147.0790104 ,
163.4625194 , 153.13567494, 159.43609279, 141.13435533,
155.48406563, 157.39608801, 155.76743211, 153.30735057,
161.03224363, 160.95391868, 155.37477073, 159.24133765,
153.57254363, 147.76400994, 148.48906477, 162.76237878,
151.73341064, 149.31036338, 160.59626048, 156.9601477 ,
155.31006755, 145.14050738, 145.54608602, 158.34832395,
141.6107559 , 154.62601804, 144.70827978, 157.61873074,
152.94575431, 153.58361804, 149.11182297, 146.28322484,
151.38366388, 143.40808304, 149.16541403, 153.4521348 ,
147.59611395, 160.47841347, 161.87339538, 162.8992885 ])
Coordinates:
* altura_dim_0 (altura_dim_0) int64 3kB 0 1 2 3 4 5 ... 347 348 349 350 351
chain int64 8B 0
draw int64 8B 0draw0.shape
(352,)
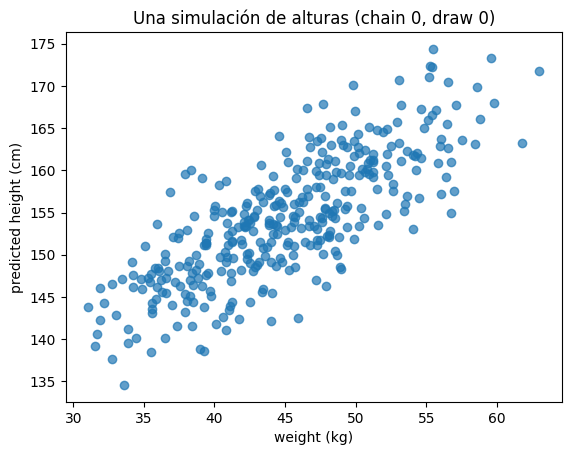
352 → número de observaciones en el dataset (una predicción de altura por persona).
Este vector representa una simulación completa de las alturas predichas para todos los individuos, utilizando los parámetros del modelo en el draw 0 de la cadena 0.
plt.scatter(adultos.weight, draw0, alpha=0.7)
plt.xlabel("weight (kg)")
plt.ylabel("predicted height (cm)")
plt.title("Una simulación de alturas (chain 0, draw 0)")
Text(0.5, 1.0, 'Una simulación de alturas (chain 0, draw 0)')
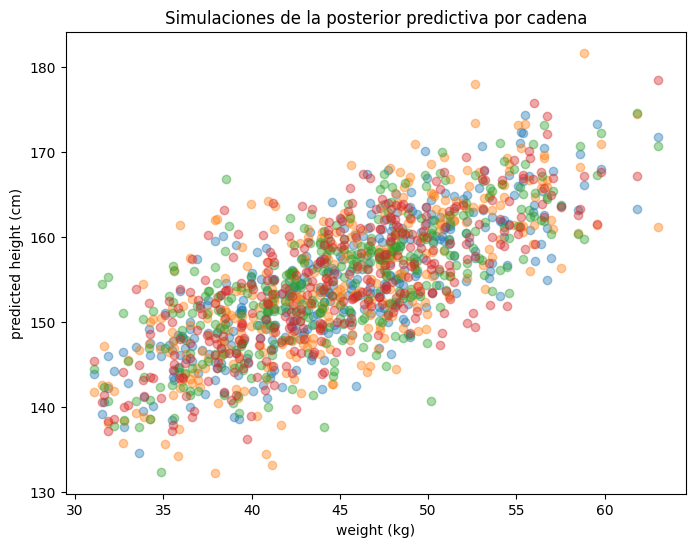
x = adultos.weight.values
order = np.argsort(x)
plt.figure(figsize=(8,6))
colors = ["C0", "C1", "C2", "C3"]
for c, color in enumerate(colors):
for d in range(1):
y = y_pred1.isel(chain=c, draw=d, altura_dim_0=order).values
plt.scatter(x[order], y, color=color, alpha=0.4)
plt.xlabel("weight (kg)")
plt.ylabel("predicted height (cm)")
plt.title("Simulaciones de la posterior predictiva por cadena")
plt.show()
# Eje x
x = adultos.weight.values
order = x.argsort()
# HDI de la posterior predictiva (incertidumbre total: params + σ)
az.plot_hdi(x, idata.posterior_predictive["altura"])
# HDI de la media condicional (incertidumbre de parámetros, sin σ)
az.plot_hdi(x, idata.posterior["mu"], color="black")
# Línea de relación promedio (media posterior de μ)
mean_mu = idata.posterior["mu"].mean(dim=["chain","draw"])
plt.plot(x[order], mean_mu.isel(mu_dim_0=order), color="red", label="Relación promedio")
# Datos observados
plt.scatter(adultos.weight, adultos.height, alpha=0.5, label="Datos observados")
plt.xlabel("weight (kg)")
plt.ylabel("height (cm)")
plt.legend()
plt.show()
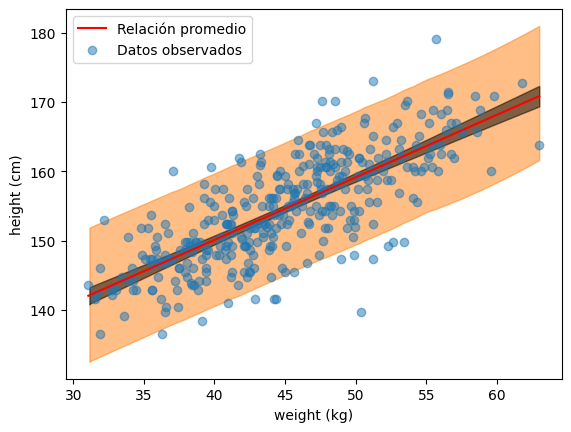
La función az.plot_hdi() resume todas las simulaciones de la posterior predictiva.
Entrada:
idata.posterior_predictive["altura"]contiene miles de simulaciones \(\tilde{y}_i^{(s)}\) generadas con los parámetros muestreados.Cálculo: para cada valor de peso \(w_i\),
plot_hdi()toma todas las alturas simuladas y calcula un intervalo de credibilidad (HDI) — por defecto, el \(94\%\).Visualización: une los límites inferiores y superiores del HDI a lo largo del eje \(X\) y rellena el área → esa es la franja naranja.
2. Evaluación del modelo#
Hasta ahora, hemos utilizado los mismos datos que sirvieron para ajustar el modelo al momento de visualizar sus predicciones.
Si queremos comprobar qué tan bien generaliza a casos nuevos, necesitamos probarlo en datos que no haya visto antes.
¿cómo evaluar su desempeño predictivo en datos nuevos?
# Primero dividimos el conjunto de datos original en dos partes:
train = adultos.sample(frac=0.8)
test = adultos.drop(train.index)
adultos.shape, train.shape, test.shape
((352, 4), (282, 4), (70, 4))
#Definimos las variables para el modelo
w=train.weight.values #datos de peso para train
w_bar = np.mean(w) #promedio de peso
h=train.height.values #datos de altura para train
#Construcción del modelo bayesiano
with pm.Model() as modelo_lineal_altura:
w = pm.Data("w", w, dims="obs_id") # datos mutables; contenedor
h = pm.Data("h", h, dims="obs_id")
# Sigma
sigma = pm.Uniform('sigma',
lower=0,
upper=50)
# Alpha
alpha = pm.Normal('alpha',
mu=170,
sigma=20)
# Beta
beta = pm.Lognormal('beta',
mu=0,
sigma=1)
# Mu
mu = pm.Deterministic('mu',
alpha + beta * (w - w_bar), dims="obs_id")
# altura
altura = pm.Normal('altura',
mu=mu,
sigma=sigma,
observed=h, dims="obs_id")
# Muestreo
idata = pm.sample()
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, alpha, beta]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 0 seconds.
Flujo de pm.Data, pm.set_data y pm.sample_posterior_predictive#
pm.Data— el contenedor mutable. Cuando defines dentro del modelo:
w = pm.Data("w", w_train)
# Con el modelo entrenado, predecimos sobre datos de prueba
w_test = test.weight.values
w_test[:5]
array([36.4858065, 62.992589 , 34.869885 , 38.498621 , 41.2485225])
pm.set_data— cambiar los datos sin reentrenar
Después de entrenar, podemos reemplazar los datos en ese contenedor:
pm.set_data({"w": w_test})
Esto actualiza internamente el valor de \(w\) dentro del modelo, pero no toca los parámetros del modelo (los mantiene fijos en los valores muestreados durante el entrenamiento).
Reusamos el modelo entrenado para hacer predicciones sobre nuevos pesos (w_test).
with modelo_lineal_altura:
pm.set_data({"w": w_test})
#muestreo posterior predictivo
altura_pred = pm.sample_posterior_predictive(
idata,
var_names=["altura", "mu"],
return_inferencedata=True,
predictions=True,
extend_inferencedata=True
)
Sampling: [altura]
Argumento |
Qué hace |
|---|---|
|
Usa las muestras del modelo entrenado (α, β, σ) para generar predicciones. |
|
Especifica qué variables del modelo queremos predecir. En este caso, pedimos tanto las alturas simuladas ( |
|
Devuelve los resultados en formato ArviZ InferenceData, lo que facilita el análisis posterior. |
|
Guarda las predicciones bajo la sección |
|
Agrega estas nuevas predicciones al mismo objeto |
altura_pred
-
<xarray.Dataset> Size: 9MB Dimensions: (chain: 4, draw: 1000, obs_id: 282) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 * obs_id (obs_id) int64 2kB 0 1 2 3 4 5 6 7 ... 275 276 277 278 279 280 281 Data variables: alpha (chain, draw) float64 32kB 154.1 154.7 154.8 ... 155.2 154.0 154.7 sigma (chain, draw) float64 32kB 4.607 5.156 5.064 ... 4.79 4.872 4.821 beta (chain, draw) float64 32kB 0.9548 0.8844 0.834 ... 0.9861 0.9698 mu (chain, draw, obs_id) float64 9MB 150.9 156.7 153.5 ... 149.4 149.6 Attributes: created_at: 2026-03-24T03:01:16.185942+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.4377589225769043 tuning_steps: 1000 -
<xarray.Dataset> Size: 4MB Dimensions: (chain: 4, draw: 1000, obs_id: 70) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 * obs_id (obs_id) int64 560B 0 1 2 3 4 5 6 7 8 ... 62 63 64 65 66 67 68 69 Data variables: altura (chain, draw, obs_id) float64 2MB 146.5 166.1 147.7 ... 148.8 153.9 mu (chain, draw, obs_id) float64 2MB 146.0 171.3 144.5 ... 153.1 152.6 Attributes: created_at: 2026-03-24T03:04:48.677910+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 -
<xarray.Dataset> Size: 528kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: (12/18) divergences (chain, draw) int64 32kB 0 0 0 0 0 0 ... 0 0 0 0 0 0 acceptance_rate (chain, draw) float64 32kB 0.8383 0.9666 ... 1.0 1.0 n_steps (chain, draw) float64 32kB 3.0 3.0 3.0 ... 3.0 3.0 index_in_trajectory (chain, draw) int64 32kB -1 -3 1 1 -2 ... -1 -1 3 -1 reached_max_treedepth (chain, draw) bool 4kB False False ... False False max_energy_error (chain, draw) float64 32kB 0.4485 -0.5512 ... -0.7452 ... ... process_time_diff (chain, draw) float64 32kB 7.3e-05 ... 6.7e-05 diverging (chain, draw) bool 4kB False False ... False False energy (chain, draw) float64 32kB 859.7 856.6 ... 857.2 lp (chain, draw) float64 32kB -856.3 -854.8 ... -854.3 tree_depth (chain, draw) int64 32kB 2 2 2 1 2 2 ... 2 2 1 2 2 2 largest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan Attributes: created_at: 2026-03-24T03:01:16.194853+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.4377589225769043 tuning_steps: 1000 -
<xarray.Dataset> Size: 5kB Dimensions: (obs_id: 282) Coordinates: * obs_id (obs_id) int64 2kB 0 1 2 3 4 5 6 7 ... 275 276 277 278 279 280 281 Data variables: altura (obs_id) float64 2kB 143.5 156.8 141.6 157.5 ... 151.1 148.6 160.7 Attributes: created_at: 2026-03-24T03:01:16.199070+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 -
<xarray.Dataset> Size: 5kB Dimensions: (obs_id: 282) Coordinates: * obs_id (obs_id) int64 2kB 0 1 2 3 4 5 6 7 ... 275 276 277 278 279 280 281 Data variables: w (obs_id) float64 2kB 41.65 47.63 44.34 45.13 ... 38.5 39.52 39.77 Attributes: created_at: 2026-03-24T03:01:16.204653+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 -
<xarray.Dataset> Size: 1kB Dimensions: (obs_id: 70) Coordinates: * obs_id (obs_id) int64 560B 0 1 2 3 4 5 6 7 8 ... 62 63 64 65 66 67 68 69 Data variables: w (obs_id) float64 560B 36.49 62.99 34.87 38.5 ... 53.64 43.35 42.81 Attributes: created_at: 2026-03-24T03:04:48.682333+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1
altura_pred.predictions["altura"]
<xarray.DataArray 'altura' (chain: 4, draw: 1000, obs_id: 70)> Size: 2MB
array([[[146.45428021, 166.06292118, 147.66600412, ..., 167.18835387,
156.55698952, 147.6875392 ],
[150.44915349, 167.36397268, 148.50136927, ..., 162.69057405,
154.29400845, 151.67019959],
[158.41091877, 169.13529975, 138.1406341 , ..., 166.23747099,
150.79214188, 154.65601816],
...,
[141.35060538, 167.88498857, 152.2058923 , ..., 164.76349966,
153.62120229, 149.36786152],
[146.20812417, 167.99656144, 137.51741753, ..., 162.81587642,
161.10054255, 148.37305663],
[148.20092172, 177.76171418, 148.2308011 , ..., 149.23142568,
151.74572344, 154.79441018]],
[[146.49626996, 169.49877016, 150.68862953, ..., 163.65855587,
151.32141755, 150.96095292],
[143.86119907, 166.87181751, 137.34260741, ..., 163.97552949,
145.3674969 , 153.07756625],
[143.38468051, 167.85944767, 144.88693245, ..., 170.41043448,
156.4960212 , 145.31272843],
...
[152.92389684, 174.9715979 , 148.38663593, ..., 162.83434349,
154.50627364, 147.23677544],
[147.88212529, 174.99305421, 146.98422342, ..., 168.31832684,
153.87377307, 152.03910468],
[150.12746458, 164.13095387, 149.02549838, ..., 171.61278174,
153.04439355, 154.13022924]],
[[145.67959598, 178.08740254, 136.41496911, ..., 161.78310873,
154.53128322, 149.56473199],
[146.65394052, 174.9441745 , 142.41191868, ..., 169.79253708,
149.74270234, 151.3599233 ],
[148.01971152, 159.58320859, 147.79810121, ..., 163.13748902,
159.08663581, 151.92596524],
...,
[157.92705006, 172.9217674 , 146.72330491, ..., 166.60218089,
150.32427738, 148.44398723],
[146.63819805, 178.31295104, 136.99532745, ..., 167.66276252,
154.37304497, 157.44171233],
[150.66499347, 174.96192462, 153.92550311, ..., 165.50931933,
148.76311447, 153.93574189]]], shape=(4, 1000, 70))
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999
* obs_id (obs_id) int64 560B 0 1 2 3 4 5 6 7 8 ... 62 63 64 65 66 67 68 69altura_pred.predictions["mu"]
<xarray.DataArray 'mu' (chain: 4, draw: 1000, obs_id: 70)> Size: 2MB
array([[[146.01457823, 171.32416802, 144.47164067, ..., 162.39137162,
152.56529559, 152.05098307],
[147.18765494, 170.62939812, 145.7585861 , ..., 162.35584171,
153.25492965, 152.77857337],
[147.75868017, 169.86604688, 146.41095835, ..., 162.06344686,
153.48058685, 153.03134624],
...,
[146.46189504, 171.77849505, 144.91853012, ..., 162.84322446,
153.01442681, 152.49997183],
[146.24544225, 171.72850383, 144.69192941, ..., 162.7344821 ,
152.84105819, 152.32322057],
[146.49830224, 170.94346125, 145.0080626 , ..., 162.31575807,
152.82528457, 152.32853803]],
[[147.67521898, 171.21315815, 146.24028579, ..., 162.90565021,
153.76739147, 153.28908041],
[145.96645465, 171.11627156, 144.43325726, ..., 162.23986559,
152.47581903, 151.96475323],
[146.28451854, 171.0678961 , 144.77366023, ..., 162.32082167,
152.69903979, 152.19542036],
...
[147.25783178, 170.38625447, 145.84786376, ..., 162.22328176,
153.24401177, 152.77402243],
[145.8648506 , 172.13145953, 144.2635707 , ..., 162.86089167,
152.66326703, 152.12950706],
[147.03865829, 169.97049026, 145.64067495, ..., 161.87690251,
152.97395598, 152.50796153]],
[[146.46130371, 170.78665061, 144.97836813, ..., 162.20123406,
152.75727585, 152.26296399],
[147.41338655, 170.86289484, 145.98384433, ..., 162.5865978 ,
153.48267105, 153.00615698],
[146.74569021, 171.19484417, 145.25520702, ..., 162.56573101,
153.07370653, 152.5768788 ],
...,
[148.00593783, 170.558293 , 146.63108837, ..., 162.59863823,
153.84301799, 153.38473484],
[145.60206005, 171.74146052, 144.0085351 , ..., 162.51578977,
152.36755193, 151.83637695],
[146.44631909, 172.15307252, 144.87916942, ..., 163.08010072,
153.09983174, 152.57744852]]], shape=(4, 1000, 70))
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999
* obs_id (obs_id) int64 560B 0 1 2 3 4 5 6 7 8 ... 62 63 64 65 66 67 68 69altura_pred es un objeto de tipo InferenceData con secciones como:
predictive["altura"]→ las alturas simuladas (ruido incluido). Forma: (chain, draw, len(w_test))predictive["mu"]→ las medias condicionales (sin ruido \(\sigma\)).
Cada valor dentro de predictive["altura"] es una simulación de altura predicha para un individuo del conjunto de prueba, bajo un conjunto de parámetros posterior.
# Eje X
x = test.weight.values
order = x.argsort()
# HDI de la posterior predictiva (incertidumbre total: params + sigma)
az.plot_hdi(x, altura_pred.predictions["altura"]) #antes usábamos idata.posterior_predictive (con 352 puntos con todos los datos conocidos)
# HDI de la media condicional (incertidumbre de parámetros, sin sigma)
az.plot_hdi(x, altura_pred.predictions["mu"], color="black") #aquí también lo mismo que en el comentario anterior
# Línea de relación promedio (media posterior de mu)
mean_mu = altura_pred.predictions["mu"].mean(dim=["chain","draw"])
plt.plot(x[order], mean_mu.isel(obs_id=order), color="red", label="Relación promedio")
# Datos observados
plt.scatter(test.weight, test.height, alpha=0.5, label="Datos observados")
plt.xlabel("weight (kg)")
plt.ylabel("height (cm)")
plt.legend()
plt.show()
Métricas de evaluación#
from sklearn.metrics import r2_score, mean_squared_error
altura_real = test['height']
altura_pred = altura_pred.predictions["mu"].mean(("chain", "draw"))
r2_score(altura_real, altura_pred)
0.4653108582313362
mean_squared_error(altura_real, altura_pred)
34.21921516494074
# Predicción media por observación
y_pred_mean = idata.predictions["mu"].mean(("chain", "draw")).values
# Intervalo de credibilidad del 90%
hdi_90 = az.hdi(idata.predictions["altura"], hdi_prob=0.9)
lower = hdi_90["altura"].sel(hdi="lower").values
upper = hdi_90["altura"].sel(hdi="higher").values
# Combinar todo en un df para inspeccionar
pred_df = pd.DataFrame({
"peso_test": test["weight"].values,
"altura_real": test["height"].values,
"altura_pred_media": y_pred_mean,
"pred_lo_90": lower,
"pred_hi_90": upper
})
# si la observación cae dentro del intervalo
pred_df["en_intervalo"] = (
(pred_df["altura_real"] >= pred_df["pred_lo_90"]) &
(pred_df["altura_real"] <= pred_df["pred_hi_90"])
)
pred_df.head(10)
| peso_test | altura_real | altura_pred_media | pred_lo_90 | pred_hi_90 | en_intervalo | |
|---|---|---|---|---|---|---|
| 0 | 36.485807 | 139.700 | 146.786528 | 138.857740 | 155.194015 | True |
| 1 | 62.992589 | 163.830 | 171.146526 | 163.238678 | 179.519387 | True |
| 2 | 34.869885 | 147.955 | 145.301480 | 137.194543 | 153.403768 | True |
| 3 | 38.498621 | 146.050 | 148.636325 | 140.332520 | 156.570079 | True |
| 4 | 41.248522 | 154.305 | 151.163512 | 143.651400 | 159.739515 | True |
| 5 | 58.598416 | 165.735 | 167.108238 | 158.703516 | 175.077310 | True |
| 6 | 50.900000 | 158.800 | 160.033316 | 151.413366 | 167.444930 | True |
| 7 | 45.642695 | 145.415 | 155.201800 | 146.714473 | 162.752182 | False |
| 8 | 37.931631 | 149.860 | 148.115256 | 139.888228 | 155.850266 | True |
| 9 | 36.287360 | 136.525 | 146.604154 | 138.878277 | 154.930457 | False |
Creamos una tabla que permite inspeccionar, observación por observación, qué tan bien las alturas reales coinciden con los intervalos de incertidumbre del modelo.
pred_df.en_intervalo.value_counts()
en_intervalo
True 61
False 9
Name: count, dtype: int64
Comentarios finales#
La función lineal utilizada en este modelo no es la única posible. Así como vimos en la clase de ajuste de polinomios, podríamos emplear funciones no lineales (cuadráticas, cúbicas, exponenciales, etc.) para capturar relaciones más complejas entre las variables. Aquí usamos una forma lineal por simplicidad y claridad conceptual.
Todas las consideraciones de ingeniería de características que aplican en modelos de regresión clásica (escalamiento, centrado, transformación, creación de variables, etc.) también aplican en modelos bayesianos. Estas decisiones influyen directamente en la estabilidad numérica, la interpretación de los parámetros y la velocidad de muestreo.
La parte más ingenieril/artesanal del modelado bayesiano radica en definir adecuadamente las distribuciones previas y probar distintas formulaciones del modelo. Es decir, el trabajo no solo consiste en ajustar el modelo, sino en reflexionar sobre qué suposiciones probabilísticas representan mejor el fenómeno que queremos describir.
Extra: Modelo lineal multivariable#
Incorporamos ahora tres predictores:
el peso (\(w_i\)),
la edad (\(a_i\)),
y el sexo (\(s_i\)), codificado como \(s_i = 0\) para mujeres y \(s_i = 1\) para hombres.
El modelo jerárquico queda definido así:
Interpretación de los parámetros#
\(\alpha\): altura promedio cuando el peso y la edad están en su media y el sexo es femenino (\(s_i=0\)).
\(\beta_w\): cambio promedio en altura por cada unidad adicional de peso, manteniendo edad y sexo constantes.
\(\beta_a\): cambio promedio en altura por cada unidad adicional de edad, manteniendo peso y sexo constantes.
\(\beta_s\): diferencia promedio en altura entre hombres y mujeres, controlando por peso y edad.
\(\sigma\): desviación estándar del error, representa la variabilidad no explicada por el modelo.