Sesión 7#
Introducción a PyMC#

Hasta ahora hemos trabajado con modelos bayesianos básicos utilizando un enfoque de inferencia exacta. Sin embargo, vimos que este enfoque presenta limitaciones importantes y no es aplicable en algunnos de los casos reales.
Por ello, introdujimos los métodos de muestreo, que nos permiten realizar inferencia aproximada sobre la distribución posterior.
En este módulo aprenderemos a utilizar la la librería PyMC, una herramienta que facilita la construcción y el ajuste de modelos bayesianos. Gracias a PyMC, podremos centrarnos en el modelado estadístico sin preocuparnos tanto por los detalles técnicos de los métodos de inferencia subyacentes.
Objetivos:
Estudiar
PyMC, en particular las funciones para crear modelos, definir variables aleatorias previas y verosimilitudes, hacer inferencia y el muestreo de la distribución posterior predictiva.
Referencias:
https://www.pymc.io/welcome.html#get-started
1. De la Posterior a MCMC y programación probabilística#
El denominar es el gran problema#
El denominador \(p(X)\) parece inocente, pero es:
Esta integral hay que evaluarla sobre todo el espacio de \(\theta\). En modelos simples con una o dos dimensiones, a veces se puede resolver analíticamente. Pero en cuanto el modelo crece, esta integral se vuelve completamente intratable.
¿para que necesitamos la posterior exacta?#
Aquí entra un insight fundamental:
No necesitamos conocer \(p(\theta|X)\) explícitamente. Solo necesitamos poder muestrear de ella.
Si tienes una colección de muestras \(\theta^{(1)}, \theta^{(2)}, \dots, \theta^{(N)}\) que provienen de \(p(\theta|X)\), puedes aproximar cualquier integral como un promedio:
Esto es Monte Carlo: reemplazar una integral difícil por un promedio sobre muestras. La pregunta que queda es la más importante: ¿cómo obtenemos esas muestras si no conocemos la posterior?
Métodos de Monte Carlo#
El nombre viene del Casino de Montecarlo, y la analogía es perfecta. Si quisieramos estimar la probabilidad de ganar en ruleta, podrías:
Opción A: calcular analíticamente todas las combinaciones posibles
Opción B: jugar miles de veces y contar
Monte Carlo es la opción B. En vez de resolver la integral, simulas el proceso muchas veces y promediamos los resultados. La ley de los grandes números garantiza que el promedio converge al valor real cuando \(N \to \infty\).
Cadenas de Markov#
Una cadena de Markov es una secuencia de estados donde el futuro solo depende del presente, no del pasado:
Esto se llama la propiedad de Markov: el sistema no tiene memoria más allá del estado actual.
Lo fascinante de las cadenas de Markov es su comportamiento a largo plazo. Bajo ciertas condiciones, sin importar dónde empieces, la cadena converge a una distribución estacionaria \(\pi(\theta)\): la proporción de tiempo que la cadena pasa en cada región del espacio converge a un valor fijo.
Entonces, ¿podmos diseñar una cadena de Markov cuya distribución estacionaria sea exactamente la posterior \(p(\theta|X)\)?
sí, y eso es precisamente MCMC.
MCMC: la unón que lo resuelve todo#
Markov Chain Monte Carlo combina ambas ideas:
Usa una cadena de Markov para recorrer el espacio de parámetros
Las muestras generadas sirven para hacer Monte Carlo
La cadena se diseña para que su distribución estacionaria sea \(p(\theta|X)\)
El mecanismo central está en la regla de transición. El algoritmo más clásico, Metropolis-Hastings, funciona así:
Estás en \(\theta^{(t)}\)
Propones un candidato \(\theta^*\) desde alguna distribución fácil de muestrear, como una normal centrada en \(\theta^{(t)}\)
Calculas la razón de aceptación:
Aceptas \(\theta^*\) con probabilidad \(\alpha\); si no, te quedas en \(\theta^{(t)}\)
Observa algo crucial en el paso 3: el cociente es de posteriors. Y como \(p(\theta|X) \propto p(X|\theta) \cdot p(\theta)\), cuando divides una por la otra, el denominador \(p(X)\) se cancela:
Eso es el truco. Nunca necesitas calcular la integral intratable. Solo necesitas evaluar la verosimilitud y el prior en dos puntos, lo cual siempre es posible.
La lógica de aceptación es intuitiva: si el candidato \(\theta^*\) tiene mayor probabilidad posterior que donde estás, siempre te mueves. Si tiene menor probabilidad, te mueves con probabilidad proporcional a cuánto menor es. Esto hace que la cadena visite regiones del espacio proporcionales a su probabilidad posterior.
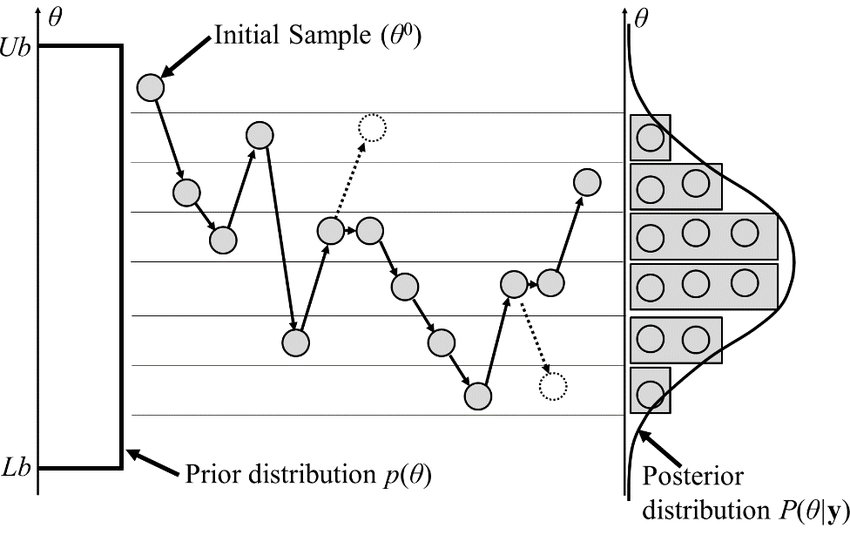
La siguiente figura ilustra exactamente este mecanismo:
El prior \(p(\theta)\) es uniforme entre \(Lb\) y \(Ub\): cualquier valor de \(\theta\) es igualmente plausible antes de ver los datos. La cadena arranca en \(\theta^0\), una muestra inicial arbitraria dentro de ese rango.
Las flechas sólidas muestran movimientos aceptados. Las flechas punteadas muestran propuestas rechazadas: el candidato fue evaluado, pero la cadena decidió quedarse donde estaba.
A la derecha, el histograma que se va formando con cada muestra aceptada converge a la distribución posterior \(P(\theta|y)\). Nadie calculó esa campana: emergió del proceso de caminar.
Los rechazos no son ineficiencia. Son lo que da forma a la distribución: la cadena pasa más tiempo en la zona central porque propuestas hacia los extremos se rechazan con más frecuencia.
Samplers modernos#
Metropolis-Hastings es la base, pero tiene limitaciones en dimensiones altas porque proponer movimientos aleatorios es ineficiente. De ahí surgieron algoritmos más sofisticados:
Gibbs Sampling: en vez de mover todos los parámetros juntos, muestrea cada uno condicionado en los demás. Útil cuando las distribuciones condicionales tienen forma conocida.
Hamiltonian Monte Carlo (HMC): usa el gradiente de la log-posterior para proponer movimientos inteligentes, como una partícula deslizándose por una superficie. Explora el espacio mucho más eficientemente.
NUTS (No-U-Turn Sampler): una versión adaptativa de HMC que ajusta automáticamente sus parámetros. Es el motor detrás de Stan y PyMC hoy en día.
Programación probabilística#
Implementar MCMC a mano implica: definir manualmente la log-posterior, gestionar propuestas y aceptaciones, diagnosticar convergencia, y repetir todo esto por cada nuevo modelo.
La programación probabilística invierte esto. En lugar de decirle a la computadora cómo muestrear, le dices qué modelo tienes, y el sampler corre automáticamente…
import matplotlib.pyplot as plt
import numpy as np
import arviz as az
import pymc as pm
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
Retomando el ejemplo 6 de la sesión 6, definamos el mismo problema ahora utilizando la librería PyMC.
Nivel 1: Datos Supongamos que tenemos un dato \(x=5\) que obtuvimos de una distribución normal con media \(\theta\) y varianza \(1\):
Nivel 2: Parámetro desconocido Supongamo que nuestra previa para el parámetro \(\theta\) es también una normal:
En la sesión 6 vimos que pudimos llegar a la solución analítica; sin embargo, ahora vamos a definir el mismo modelo pero con programación probabilística:
# Modelo
with pm.Model() as model:
theta = pm.Normal("theta",
mu=2,
sigma=1) # Previa
x = pm.Normal("x",
mu=theta,
sigma=1,
observed=[5]) # Verosimilitud
# Muestreo
idata = pm.sample(draws=2000)
Initializing NUTS using jitter+adapt_diag...
Sequential sampling (2 chains in 1 job)
NUTS: [theta]
Sampling 2 chains for 1_000 tune and 2_000 draw iterations (2_000 + 4_000 draws total) took 2 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
idata: el resultado del muestreo
El resultado del muestreo con pm.sample() es un objeto de tipo InferenceData, comúnmente almacenado en una variable llamada idata.
Este objeto contiene toda la información generada durante el muestreo.
Por ejemplo, si usamos 4 cadenas y cada una genera 2000 muestras,
en total tendremos 8 000 muestras de la distribución posterior.
En cada cadena se almacenan los valores que el muestreador fue aceptando para los parámetros. Así, para nuestro parámetro \(\theta\), idata.posterior["theta"] será una matriz con forma:
idata
<xarray.DataTree>
Group: /
├── Group: /posterior
│ Dimensions: (chain: 2, draw: 2000)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 16kB 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999
│ Data variables:
│ theta (chain, draw) float64 32kB 2.579 4.445 3.737 ... 1.337 3.48 3.593
│ Attributes:
│ created_at: 2026-06-18T14:23:37.980452+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.0.1
│ sample_dims: ['chain', 'draw']
│ sampling_time: 1.514402151107788
│ tuning_steps: 1000
├── Group: /sample_stats
│ Dimensions: (chain: 2, draw: 2000)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 16kB 0 1 2 3 4 ... 1996 1997 1998 1999
│ Data variables: (12/18)
│ lp (chain, draw) float64 32kB -4.936 -4.981 ... -4.097
│ step_size_bar (chain, draw) float64 32kB 1.352 1.352 ... 1.348
│ reached_max_treedepth (chain, draw) bool 4kB False False ... False False
│ perf_counter_diff (chain, draw) float64 32kB 8.829e-05 ... 0.0001602
│ n_steps (chain, draw) float64 32kB 1.0 3.0 3.0 ... 3.0 3.0
│ divergences (chain, draw) int64 32kB 0 0 0 0 0 0 ... 0 0 0 0 0 0
│ ... ...
│ perf_counter_start (chain, draw) float64 32kB 8.424e+03 ... 8.425e+03
│ index_in_trajectory (chain, draw) int64 32kB 1 -2 1 0 -2 ... -2 -1 -1 -1
│ step_size (chain, draw) float64 32kB 1.408 1.408 ... 1.886
│ max_energy_error (chain, draw) float64 32kB 0.1485 ... 0.003915
│ smallest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan
│ largest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan
│ Attributes:
│ created_at: 2026-06-18T14:23:37.993145+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.0.1
│ sample_dims: ['chain', 'draw']
│ sampling_time: 1.514402151107788
│ tuning_steps: 1000
└── Group: /observed_data
Dimensions: (x_dim_0: 1)
Coordinates:
* x_dim_0 (x_dim_0) int64 8B 0
Data variables:
x (x_dim_0) float64 8B 5.0
Attributes:
created_at: 2026-06-18T14:23:37.997601+00:00
creation_library: ArviZ
creation_library_version: 1.2.0
creation_library_language: Python
inference_library: pymc
inference_library_version: 6.0.1
sample_dims: []# Dimensiones de las posteriores
idata.posterior.dims
Frozen(ChainMap({'chain': 2, 'draw': 2000}, {}))
# Para mu, shape
idata.posterior["theta"].shape
(2, 2000)
# matriz
idata.posterior['theta']
<xarray.DataArray 'theta' (chain: 2, draw: 2000)> Size: 32kB
array([[2.57891169, 4.44517087, 3.73704377, ..., 3.59016843, 3.36832497,
3.63745053],
[2.25110433, 2.42984668, 3.19383933, ..., 1.33666894, 3.47982078,
3.59309844]], shape=(2, 2000))
Coordinates:
* chain (chain) int64 16B 0 1
* draw (draw) int64 16kB 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999plot_trace: visualización las cadenas y la distribución posterior
La función az.plot_trace() de ArviZ permite visualizar las trazas (los valores muestreados a lo largo de las iteraciones) y la distribución posterior estimada para cada parámetro.
# plot_trace
az.plot_trace(idata)
<arviz_plots.plot_collection.PlotCollection at 0x7aaf032197f0>
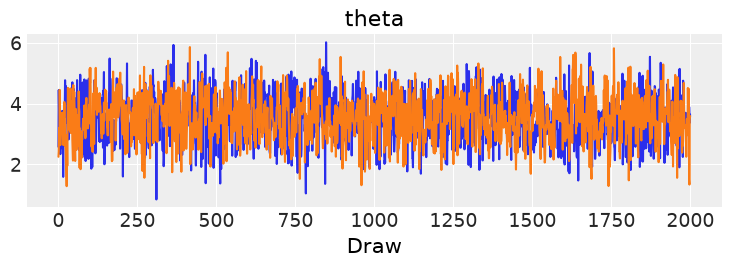
El gráfico que obtenemos muestra dos partes por cada parámetro (en este caso \(\theta\)):
Izquierda: el histograma y la densidad de las muestras, que representan la distribución posterior estimada.
Derecha: la traza o evolución de los valores muestreados en cada iteración (por todas las cadenas de Markov).
Si las cadenas se observan sin tendencias ni patrones persistentes, eso indica que la simulación ha convergido y que estamos muestreando correctamente la distribución posterior.
az.summary: Resumen estadístico
También podemos obtener información de forma tabular:
az.summary(idata, hdi_prob=0.89)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[10], line 1
----> 1 az.summary(idata, hdi_prob=0.89)
TypeError: summary() got an unexpected keyword argument 'hdi_prob'. Did you mean 'ci_prob'?
Columna |
Significado |
|---|---|
mean |
La media posterior de las muestras. Representa el valor esperado de \(\theta\) según la distribución posterior. |
sd |
Desviación estándar de las muestras. Indica la incertidumbre de la estimación. |
hdi_5.5% / hdi_94.5% |
Límites inferior y superior del Intervalo de Densidad Máxima (HDI) al 89% (definido por |
mcse_mean |
Error estándar Monte Carlo de la media. Mide la precisión de la estimación de la media a partir del número de muestras. Cuanto más pequeño, mejor. |
mcse_sd |
Error estándar Monte Carlo de la desviación. Igual que el anterior, pero aplicado a la estimación de la dispersión. |
ess_bulk |
Tamaño efectivo de muestra (Effective Sample Size) en la región central de la distribución. Cuanto mayor, más confiables las estimaciones. |
ess_tail |
Tamaño efectivo de muestra en las colas de la distribución (valores extremos). Indica qué tan bien se exploraron los extremos. |
r_hat |
Estadístico de convergencia de Gelman–Rubin. Si está cercano a 1.0, las cadenas han convergido correctamente. Valores mayores a 1.1 indican falta de convergencia. |
Diagramas
az.plot_forest
Los diagramas tipo forest son una forma compacta y visual de mostrar los intervalos de credibilidad (o HDI, Highest Density Interval) de la distribución posterior.
az.plot_forest(idata,
hdi_prob=0.89)
array([<Axes: title={'center': '89.0% HDI'}>], dtype=object)
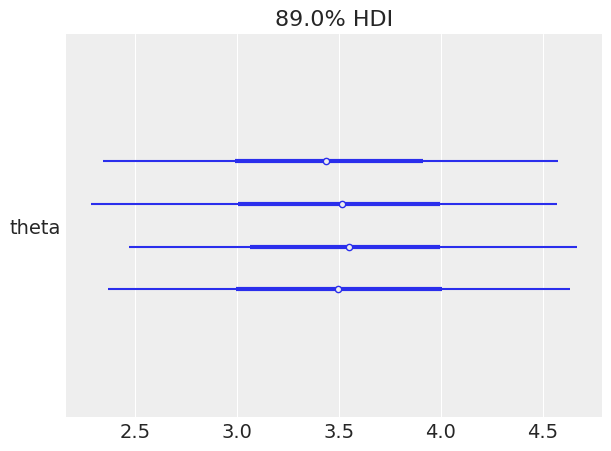
Cada línea azul representa una cadena diferente y los puntos marcan la media posterior estimada para cada una.
Si todas las líneas están alineadas y centradas aproximadamente en el mismo rango, eso indica que todas las cadenas convergieron al mismo resultado una señal de muestreo estable y confiable.
El rango horizontal de cada barra corresponde al intervalo donde se concentra el 89% más probable de los valores muestreados para \(\theta\).
Podemos graficar la posterior con kde:
az.plot_posterior(idata,
hdi_prob=0.95,
bw=0.5) #bandwidth
<Axes: title={'center': 'theta'}>
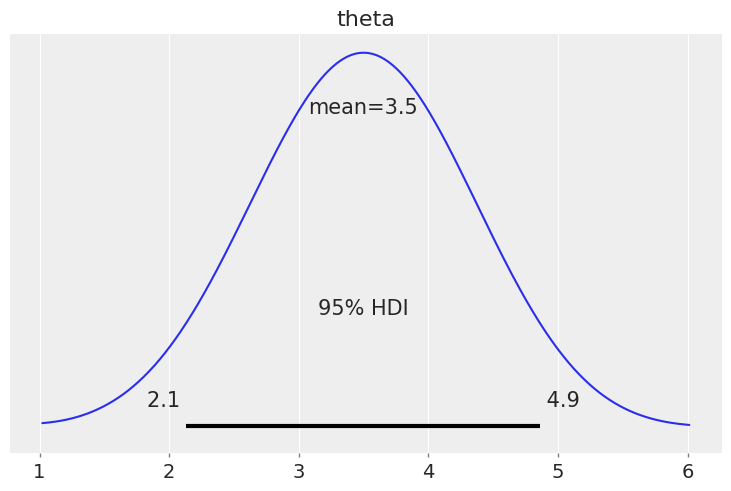
💡 En otras palabras:
No vemos la distribución posterior directamente,
pero la reconstruimos a partir de un gran número de muestras que la representan.
2. Muestreo posterior predictivo#
La posterior no es el fin, es el punto de partida#
Hasta ahora usamos los datos para aprender sobre \(\theta\), pero lo que normalmente queremos no es conocer \(\theta\) es sí mismo, sino hacer predicciones sobre nuevos datos.
Aquí entra la distinción clave:
La posterior \(p(\theta|X)\) responde: «¿qué aprendí sobre el parámetro?»
La predictiva posterior responde: «dado lo que aprendí, ¿qué datos nuevos esperaría ver?»
Ejemplo 2: Nuevo modelo, incluyendo previa para la desviación estándar#
import warnings
warnings.filterwarnings("ignore", module="threadpoolctl")
data = rng.standard_normal(100) # siempre N(0, 1)
with pm.Model() as model:
# Previas
mu = pm.Normal("mu",
mu=0,
sigma=1)
sd = pm.HalfNormal("sd",
sigma=1)
# Verosimilitud
obs = pm.Normal("obs",
mu=mu,
sigma=sd,
observed=data)
# Muestreo de las distribuciones posteriores
idata = pm.sample()
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, sd]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 0 seconds.
PyMC nos permite hacer esto automáticamente con la función pm.sample_posterior_predictive().
Esta función toma las muestras de la posterior (idata) y genera nuevas observaciones simuladas \(\tilde{y}\) según los valores de parámetros que obtuvimos durante el muestreo.
# Incluimos muestras de la posterior predictiva
with model:
idata.extend(pm.sample_posterior_predictive(idata))
Sampling: [obs]
idata
-
<xarray.Dataset> Size: 72kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 Data variables: mu (chain, draw) float64 32kB 0.1776 0.07686 ... 0.1801 0.06198 sd (chain, draw) float64 32kB 1.022 0.9735 0.9288 ... 1.117 1.015 Attributes: created_at: 2026-03-23T22:35:47.164547+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.3122408390045166 tuning_steps: 1000 -
<xarray.Dataset> Size: 3MB Dimensions: (chain: 4, draw: 1000, obs_dim_0: 100) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 * obs_dim_0 (obs_dim_0) int64 800B 0 1 2 3 4 5 6 7 ... 93 94 95 96 97 98 99 Data variables: obs (chain, draw, obs_dim_0) float64 3MB -1.225 0.1346 ... 1.303 Attributes: created_at: 2026-03-23T22:35:47.247155+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 -
<xarray.Dataset> Size: 528kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: (12/18) reached_max_treedepth (chain, draw) bool 4kB False False ... False False index_in_trajectory (chain, draw) int64 32kB 2 2 1 1 0 0 ... 0 -2 1 1 -1 step_size_bar (chain, draw) float64 32kB 1.179 1.179 ... 1.183 perf_counter_start (chain, draw) float64 32kB 7.469e+04 ... 7.469e+04 tree_depth (chain, draw) int64 32kB 2 2 2 1 1 1 ... 2 2 2 2 1 2 diverging (chain, draw) bool 4kB False False ... False False ... ... largest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan n_steps (chain, draw) float64 32kB 3.0 3.0 3.0 ... 1.0 3.0 smallest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan step_size (chain, draw) float64 32kB 0.9713 0.9713 ... 1.522 divergences (chain, draw) int64 32kB 0 0 0 0 0 0 ... 0 0 0 0 0 0 max_energy_error (chain, draw) float64 32kB -0.2451 0.117 ... -0.2183 Attributes: created_at: 2026-03-23T22:35:47.170469+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.3122408390045166 tuning_steps: 1000 -
<xarray.Dataset> Size: 2kB Dimensions: (obs_dim_0: 100) Coordinates: * obs_dim_0 (obs_dim_0) int64 800B 0 1 2 3 4 5 6 7 ... 93 94 95 96 97 98 99 Data variables: obs (obs_dim_0) float64 800B -0.2226 1.326 -0.571 ... 0.2766 0.4714 Attributes: created_at: 2026-03-23T22:35:47.172065+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1
posterior_predictive: guarda las simulaciones de datos nuevos generadas a partir
de los parámetros muestreados.
plot_pcc: visualización de la posterior predictiva
# Gráfica de las muestras de la posterior predictiva, la media de dichas muestras
fig, ax = plt.subplots()
az.plot_ppc(idata, ax=ax)
ax.axvline(data.mean(), ls="--", color="r", label="True mean")
ax.legend(fontsize=10)
<matplotlib.legend.Legend at 0x11b953ed0>
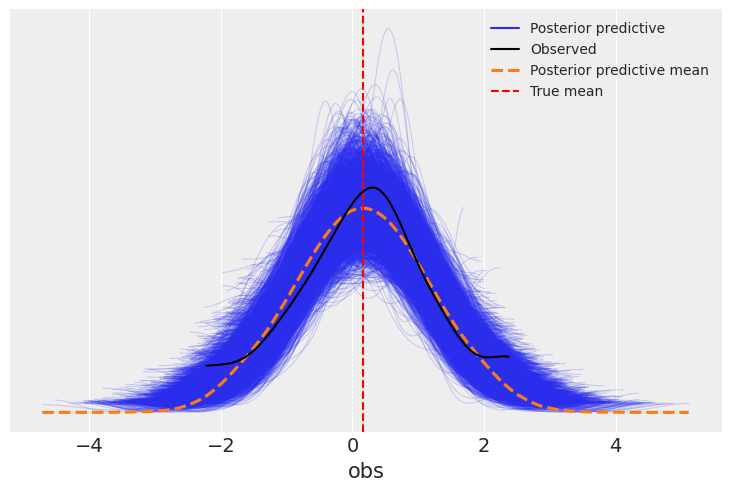
Elemento visual |
Representa |
Interpretación |
|---|---|---|
Líneas azules finas |
Muestras de la posterior predictiva |
Cada curva azul es una simulación de posibles datos según el modelo; muestra la variabilidad esperada. |
Línea negra |
Distribución observada |
Representa los datos reales que usamos para ajustar el modelo. |
Línea naranja discontinua |
Media de las simulaciones |
Promedio de todas las simulaciones; refleja lo que el modelo predice “en promedio”. |
Línea roja punteada |
Media verdadera (True mean) |
Valor real usado para generar los datos, sirve como referencia para evaluar el ajuste. |
# 1) Diagnósticos de muestreo
az.summary(idata, var_names=["mu", "sd"], hdi_prob=0.95)
# 2) Intervalos de credibilidad (numéricos)
# 2a) Parámetros
hdi_mu = az.hdi(idata.posterior["mu"], hdi_prob=0.95).to_array().values.squeeze()
hdi_sd = az.hdi(idata.posterior["sd"], hdi_prob=0.95).to_array().values.squeeze()
print("HDI 95% mu:", hdi_mu)
print("HDI 95% sd:", hdi_sd)
# 2b) Posterior predictiva (distribución de valores simulados)
ppc_flat = idata.posterior_predictive["obs"].values.reshape(-1)
hdi_ppc = az.hdi(ppc_flat, hdi_prob=0.95)
print("HDI 95% posterior predictiva (obs simuladas):", hdi_ppc)
HDI 95% mu: [-0.03760041 0.34849509]
HDI 95% sd: [0.87056994 1.14869343]
HDI 95% posterior predictiva (obs simuladas): [-1.80730147 2.15093678]
La pregunta es: ¿qué tan bien predice el modelo datos que nunca vio?
3. Predicciones sobre datos no vistos#
En esta sección veremos cómo realizar predicciones con un modelo de regresión logística bayesiana en PyMC, utilizando la API moderna (pm.Data y model.set_data) disponible desde la versión 5.25.1..
Ejemplo 3: Predicciones sobre datos no vistos#
1. Generación de datos simulados
Creamos un conjunto de datos simple: una variable x normal estándar y una variable binaria y que vale 1 cuando x > 1.
rng = np.random.default_rng(8927)
x = rng.standard_normal(100)
y = (x > 0).astype(int)
coords = {"idx": np.arange(len(x))}
x
array([-0.22264222, 1.32565874, -0.57097002, 0.6682492 , 1.14538102,
0.58734406, -0.05144329, -1.84504794, -0.30722036, -0.01176056,
0.63543926, 0.11328912, 1.41879627, 0.79941587, -0.42757956,
1.53468809, -2.22735876, 0.28241532, -1.12155038, 1.30086967,
0.51274112, -1.06199319, -0.09822517, 0.38922566, -1.95535676,
0.33735625, 0.47742834, -1.10327477, -0.49871424, 0.9157944 ,
-0.63225154, 0.52343605, 0.38268978, 0.17817512, -0.75581839,
-0.82961425, 0.54596355, 1.29121212, 0.49681212, -1.23673741,
-1.02877567, -0.38786421, -0.16475099, 0.02794133, 1.49207391,
-0.89280504, -0.40397156, 0.37053056, 0.18221169, 1.35578274,
0.06602347, -1.14783586, 1.20631292, 0.29378664, -0.24608568,
0.86234979, 0.93790114, 0.04664653, -1.18832372, -1.52583061,
1.33826815, 0.39615042, 0.26957478, -0.26209802, 0.54821982,
0.96664454, 0.44183477, 0.78746462, 0.01135201, 2.36723312,
0.12145769, -0.12243637, 0.61356696, 1.050127 , -0.21869854,
-0.61214246, 2.25982335, 0.9753006 , 0.13074342, -0.52673016,
0.37235444, 1.80332605, -0.6847884 , -1.76805194, 2.37781412,
0.64583684, -0.63103472, -0.28446738, 0.64951987, -0.38797732,
0.15729908, -1.99179537, -1.05243934, 2.27724135, 0.57458621,
-1.47882206, 1.84504272, 1.37135795, 0.27659513, 0.47136373])
y
array([0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0,
0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1,
1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1,
1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0,
1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1])
coords
{'idx': array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67,
68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84,
85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99])}
2. Definición del modelo
Prior sobre el coeficiente (conocimiento previo):
Función de enlace logística (para transformar valores reales en probabilidades):
Verosimilitud (modelo de generación de los datos observados):
Objetivo de la inferencia (distribución posterior):
with pm.Model(coords=coords) as model:
# Datos mutables
x_obs = pm.Data("x_obs", x, dims="idx")
y_obs = pm.Data("y_obs", y, dims="idx")
# Modelo de regresión logística
## Conocimiento sobre la distribución previa del coeficiente
coeff = pm.Normal("x",
mu=0,
sigma=1)
## La función sigmoide para obtener probabilidades
logistic = pm.Deterministic("p", pm.math.sigmoid(coeff * x_obs), dims="idx")
## Una distribución bernoulli para los datos observados
y_like = pm.Bernoulli("obs",
p=logistic,
observed=y_obs, #*** siempre que veamos "observed=", es una verosimilitud
dims="idx")
idata = pm.sample()
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [x]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 0 seconds.
pm.Datacrea contenedores mutables que permiten reemplazar los datos sin reconstruir el modelo.
pm.Deterministicalmacena la probabilidad estimada para cada observación.
pm.Bernoullidefine el modelo generativo binario.
3. Predicciones en datos nuevos
Supongamos que queremos predecir sobre tres nuevos valores de x:
Qué representan esos tres valores
x = -1.0: está en la zona negativa, donde esperamos que la probabilidad dey = 1sea baja (cercana a 0).x = 0.0: está justo en el límite, donde la probabilidad debería ser cercana a 0.5.x = 1.0: está en la zona positiva, donde la probabilidad debería ser alta (cercana a 1).
# nuevos datos
x_new = np.array([-1.0, 0.0, 1.0])
y_new = np.array([0, 0, 0])
coords_new = {"idx": np.array([1001, 1002, 1003])}
with model:
# actualizamos los datos observados y las coordenadas
model.set_data("x_obs", x_new, coords=coords_new)
model.set_data("y_obs", y_new)
# posterior predictiva para las nuevas observaciones
ppc = pm.sample_posterior_predictive(
idata, var_names=["p", "obs"], random_seed=8927
) # ***
# guardar estas predicciones dentro de idata original
idata.extend(ppc)
Sampling: [obs]
4. Análisis de resultados
Calculamos la probabilidad promedio predicha por el modelo para cada nuevo punto:
idata.posterior_predictive["obs"].mean(dim=["draw","chain"])
<xarray.DataArray 'obs' (idx: 3)> Size: 24B array([0.02475, 0.5015 , 0.97425]) Coordinates: * idx (idx) int64 24B 1001 1002 1003
5. Interpretación de los resultados
En el paso anterior calculamos la probabilidad promedio de \(y=1\) para cada nuevo valor de x_new, promediando sobre todas las cadenas y muestras de la posterior.
x_new |
\(P(y=1)\) estimada |
|---|---|
\(-1\) |
\(0.02725 \) |
\(0\) |
\(0.5015 \) |
\(1\) |
\(0.9735 \) |
Si aplicamos un umbral de decisión de \(0.5\), las clases predichas sería [0,1,1].