Sesión 3 B#
1. Repaso de probabilidad (parte 2B)#
1.1. Variables aleatorias#
Las variables aleatorias son funciones que asignan un valor numérico a cada resultado de un experimento aleatorio. Se clasifican en dos tipos:
Variables aleatorias discretas
➡️ Variables aleatorias continuas
Objetivos:
Repasar la definición de variables aleatorias continuas.
Definir la función de densidad de probabilidad y la función de distribución acumulada.
Definir el valor esperado y varianza de una variable aleatoria continua.
Variables aleatorias continuas#
Definición
Sea \(\Omega\) un espacio muestral continuo, es decir, un conjunto no numerable de posibles resultados de un experimento aleatorio.
Una variable aleatoria continua es una función que asigna un número real a cada resultado del espacio muestral:
A diferencia de las variables aleatorias discretas, los valores que puede tomar \(X\) no se pueden enumerar, ya que forman un subconjunto continuo de \(\mathbb{R}\). Esto significa que \(X\) puede asumir infinitos valores dentro de un intervalo real.
import numpy as np
from scipy import stats
from matplotlib import pyplot as plt
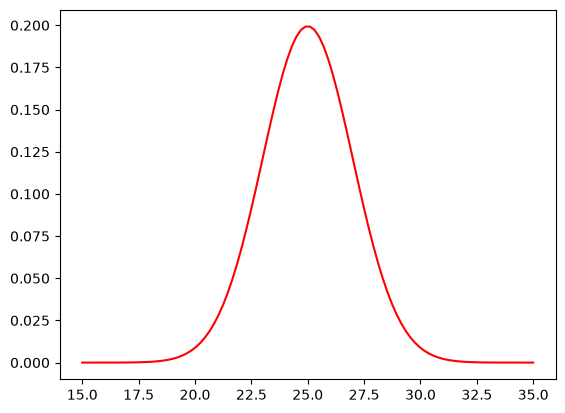
X = stats.norm(loc=25, scale=2)
x = np.linspace(15, 35, 100)
y = X.pdf(x)
plt.plot(x, y, 'r-', label='pdf')
[<matplotlib.lines.Line2D at 0x74aa129160d0>]
1.1.1. Función de densidad de probabilidad (PDF)#
Una PDF es una función matemática que describe cómo se distribuye la probabilidad de una variable aleatoria continua a lo largo de los valores que puede tomar.
En el contexto de variables aleatorias continuas no hablamos de «función de probabilidad», sino de una función de densidad de probabilidad p.d.f. \(p(x)\) que debe cumplir:
esta condición asegura que no haya probabilidades negativas.
Además:
esta segunda condición asegura que la «masa total de probabilidad» esté normalizada a 1.
Notemos que en este caso la densidad puede ser mayor a \(1\).
Variables aleatorias discretas |
Variables aleatorias continuas |
|---|---|
\(P(a) = P(X = a)\) |
\(p(x)\) |
\(0 \leq P(a) \leq 1\) |
\(0 \leq p(x)\) |
\(\sum_a P(a) = 1\) |
\(\int_{-\infty}^{\infty} p(x)\,dx = 1\) |
1.1.2. Función de distribución acumulativa (CDF)#
Definimos también la función de distribución acumulada (CDF) \(P(x)\) como:
y representa la probabilidad de que \(X\) tome un valor menor que \(x\), es decir:
Observaciones
Todo lo que vimos en el caso discreto se extiende al caso continuo:
La marginalización, la regla de la cadena, la regla de Bayes, aplican cambiando sumas por integrales y probabilidades por densidades de probabilidad:
\(p(x) = \int_{-\infty}^{\infty} p(x, y) \mathrm{d}y\): Marginalización
\(p(x, y) = p(y | x) p(x) = p(x | y) p(y)\): Regla de la cadena
\(p(x) = \int_{-\infty}^{\infty} p(x | y) p(y) \mathrm{d}y\): Probabilidad total
1.2. Distribuciones de probabilidad continuas#
1.2.1. Distribución uniforme#
Qué modela:
Una situación en la que todos los valores dentro de un intervalo son igualmente probables. No hay preferencia por ningún punto dentro del rango.
Ejemplo:
Medir el tiempo de llegada de un autobús que puede llegar en cualquier momento entre 10:00 y 10:30, con la misma probabilidad en todo ese intervalo.
Cualquier instante dentro del rango es igualmente probable.
Parámetros:
\(a\): límite inferior del intervalo
\(b\): límite superior del intervalo
Se requiere que \(a < b\)
Soporte:
Soporte: \([a, b]\), porque ahí es donde la función vive.
Se denota como:
Función de densidad (PDF):
Función de distribución acumulada (CDF):
Ejercicio 1
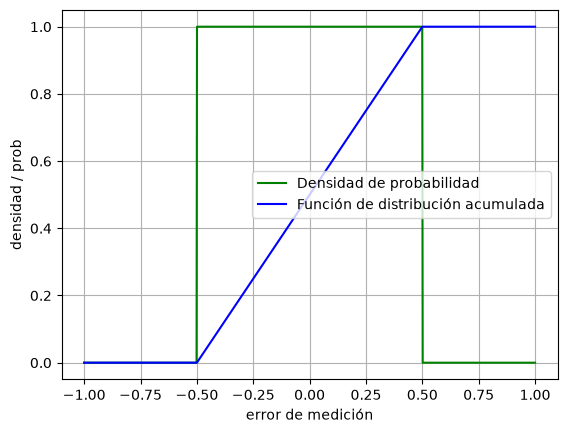
Se tiene una cinta de medir con resolución milimétrica. Si medimos la longitud de unas varillas que fueron cortadas a 1 metro de longitud, el error de medición estará uniformemente distribuido entre -0.5 y 0.5 milímetros.
Parámetros:
loces el inicio del intervalo, se interpreta como el parámetro \(a\) (límite inferior).scalees la longitud del intervalo, se interpreta como \(b - a\).
Entonces, la distribución se define sobre el intervalo:
stats.uniform?
# Variable aleatorio uniforme
X = stats.uniform(loc=-0.5, scale=1)
# Gráfico de pdf y cdf
x = np.linspace(-1, 1, 1000)
y1 = X.pdf(x)
y2 = X.cdf(x)
plt.plot(x, y1, color='green', label='Densidad de probabilidad')
plt.plot(x, y2, color='blue', label='Función de distribución acumulada')
plt.xlabel('error de medición')
plt.ylabel('densidad / prob')
plt.legend()
plt.grid()
1.2.2. Distribución exponencial#
Qué modela:
El tiempo entre eventos aleatorios que ocurren a una tasa constante. Es común en procesos de espera, como llamadas telefónicas, llegadas de clientes o tiempo de vida de componentes electrónicos.
Ejemplo:
Esperar el siguiente autobús, sabiendo que los autobuses llegan en promedio cada 10 minutos.
El tiempo de espera entre llegadas puede modelarse con una distribución exponencial.
Parámetros:
\(\lambda > 0\): tasa de ocurrencia de eventos (eventos por unidad de tiempo)
Soporte:
Soporte: \([0, \infty)\), ya que el tiempo o distancia entre eventos no puede ser negativo.
Se denota como:
Función de densidad (PDF):
Función de distribución acumulada (CDF):
Ejercicio 2
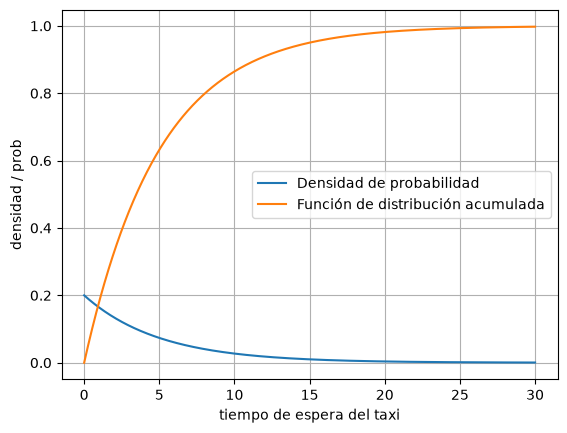
Si sales de tu casa para tomar un taxi, el tiempo que esperas hasta que llegue el siguiente taxi puede modelarse con una distribución exponencial.
Una manera práctica de estimar el parámetro \(\lambda\) es usando la duración promedio de espera observada. Por ejemplo, si normalmente esperas unos 5 minutos, puedes estimar:
Entonces podrías modelar el tiempo de espera con:
Esto significa que los tiempos cortos de espera son más probables que los largos, pero siempre existe la posibilidad de que haya esperas inusualmente largas.
# Lambda
lambda_ = 1/5
stats.expon?
# Variable aleatoria exponencial
X = stats.expon(scale=1/lambda_)
# Gráfico de pdf y cdf
x = np.linspace(0, 30, 1000)
y1 = X.pdf(x)
y2 = X.cdf(x)
plt.plot(x, y1, label='Densidad de probabilidad')
plt.plot(x, y2, label='Función de distribución acumulada')
plt.xlabel('tiempo de espera del taxi')
plt.ylabel('densidad / prob')
plt.legend()
plt.grid()
1.2.3. Distribución normal (Gaussiana)#
Qué modela:
La distribución normal describe fenómenos que tienden a agruparse alrededor de un valor promedio, con pequeñas variaciones hacia arriba y hacia abajo.
Ejemplo:
Las calificaciones de un grupo grande de estudiantes en un examen, donde la mayoría obtiene puntajes cercanos al promedio, y solo unos pocos puntajes muy altos o muy bajos.
Parámetros:
\(\mu\): media (valor central)
\(\sigma > 0\): desviación estándar (dispersión)
Soporte:
Soporte: \((-\infty, \infty)\), ya que una variable normal puede, en teoría, tomar cualquier valor real.
Se denota como:
Función de densidad (PDF):
Función de distribución acumulada (CDF):
No tiene una forma cerrada elemental, pero se define como:
Esta integral representa la probabilidad acumulada de que la variable tome un valor menor que \(x\).
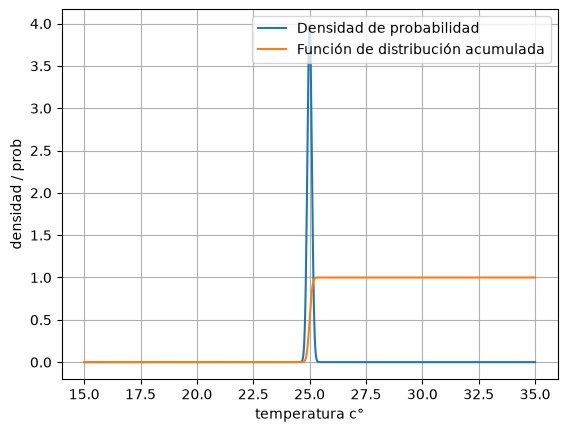
# Variable aleatoria normal
mu = 25
sigma = 0.1
X = stats.norm(loc=mu, scale=sigma)
Parámetros:
loces la media de la distribución, se interpreta como el parámetro \(\mu\).scalees la desviación estándar, se interpreta como \(\sigma\) (no la varianza).
Entonces, la distribución se define como:
# Gráfico de pdf y cdf
x = np.linspace(15, 35, 1000)
y1 = X.pdf(x)
y2 = X.cdf(x)
plt.plot(x, y1, label='Densidad de probabilidad')
plt.plot(x, y2, label='Función de distribución acumulada')
plt.xlabel('temperatura c°')
plt.ylabel('densidad / prob')
plt.legend()
plt.grid()
1.3. Valor esperado y varianza (continuas)#
1.3.1. Esperanza#
El valor esperado de una función \(f(x)\) con respecto a una distribución de probabilidad \(p(x)\) se denota por:
Esto representa una especie de “promedio” de \(f(x)\), donde los valores más probables (según \(p(x)\)) tienen mayor peso.
El valor esperado es una medida de tendencia central: nos indica el valor típico o representativo de la función aleatoria en el contexto de su distribución.
1.3.2. Varianza#
Una medida complementaria al valor esperado es la varianza, que mide qué tanto varía \(f(x)\) alrededor de su valor esperado. Se denota como:
y también puede escribirse como:
Esta forma alternativa resulta muy útil para el cálculo práctico de la varianza.
# Ejemplos: distribuciones normales con diff medias y varianzas
from scipy.stats import norm
import numpy as np
X = stats.norm(loc=25, scale=2)
Y = stats.norm(loc=25, scale=5)
Z = stats.norm(loc=30, scale=2)
x = np.linspace(15, 35, 1000)
y1 = X.pdf(x)
y2 = Y.pdf(x)
y3 = Z.pdf(x)
plt.plot(x, y1, label='X: N(25, 2)')
plt.plot(x, y2, label='Y: N(25, 5)')
plt.plot(x, y3, label='Z: N(30, 2)')
plt.xlabel('Temperatura [C]')
plt.ylabel('Densidad de probabilidad')
plt.legend()
plt.grid()
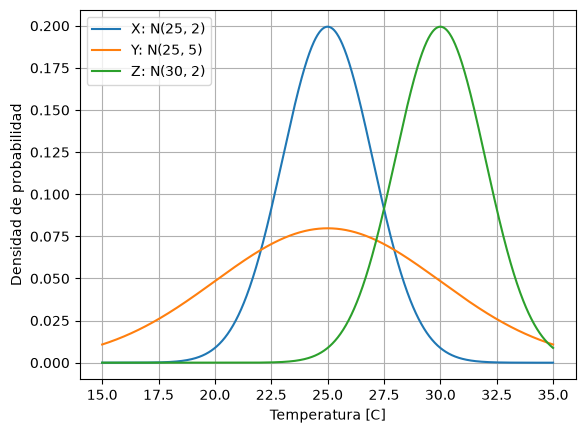
X.expect(), Y.expect(), Z.expect()
(np.float64(24.999999999999986),
np.float64(25.000000000000004),
np.float64(29.99999999999997))
X.std(), Y.std(), Z.std()
(np.float64(2.0), np.float64(5.0), np.float64(2.0))
Propiedades de la distribución normal#
Sea \(X \sim \text{Normal}(\mu, \sigma^2)\). Entonces se cumplen las siguientes propiedades fundamentales:
Valor esperado (media):
El valor esperado de \(X\) es igual al parámetro de media \(\mu\):\[ \mathbb{E}[X] = \mu \]Varianza:
La varianza de \(X\) corresponde al cuadrado de la desviación estándar \(\sigma\):\[ \mathrm{Var}(X) = \sigma^2 \]