Sesión 6 A#
Actualización bayesiana discreta y predicción probabilística#
Objetivos:
Repasar la regla de Bayes para calcular probabilidades.
Definir e identificar los roles de probabilidad previa, verosimilitud, probabilidad posterior, datos e hipótesis en la aplicación de la regla de Bayes.
Usar la regla de probabilidad total para calcular probabilidades predictivas previa y posterior.
1. Repaso de la regla de Bayes#
Recordemos que la regla de Bayes nos permite invertir probabilidades condicionales. Dadas V.A. \(X\) y \(Y\), tenemos que
¿cómo que invertirlas? Bueno, si conocemos la probabilidad condicional \(p(X | Y)\), es decir, la probabilidad de observar \(X\) dado que \(Y\) ha ocurrido, podemos calcular la probabilidad condicional inversa \(p(Y | X)\), es decir, la probabilidad de que \(Y\) haya ocurrido dado que hemos observado \(X\).
Ejemplo 1#
Descripción del problema#
Tenemos tres tipos de monedas con diferentes probabilidades de caer cara:
Tipo A: moneda justa, con probabilidad de cara de \(0.5\)
Tipo B: moneda cargada, con probabilidad de cara de \(0.6\)
Tipo C: moneda cargada, con probabilidad de cara de \(0.9\)
Tenemos un recipiente con cinco monedas, dos (2) de tipo A, dos (2) de tipo B y una (1) de tipo C. Seleccionamos una moneda del recipiente de forma aleatoria y, sin mirarla, la tiramos y obtenemos cara.
Pregunta#
¿Cuál es la probabilidad de que la moneda sea tipo A?, ¿tipo B?, ¿tipo C?
Desarrollo de la solución#
1. Primero, identifiquemos las variables aleatorias involucradas:
\(T\): tipo de moneda seleccionada, con valores posibles \(1\) (tipo A), \(2\) (tipo B) y \(3\) (tipo C).
\(D\): resultado del lanzamiento de la moneda, con valores posibles \(0\) (cruz) y \(1\) (cara).
2. Sea \(D\) la variable aleatoria que vale 1 si la moneda que sea cae cara y \(T\) la variable aleatoria que representa el tipo de la moneda. \(T\) vale:
\(T=1\) si la moneda es tipo A,
\(T=2\) si la moneda es tipo B,
\(T=3\) si la moneda es tipo C.
El problema nos pide encontrar
3. ¿qué información tenemos?
Información disponible:
\(p(D=1|T=1) = 0.5\) (probabilidad de cara con moneda tipo A).
\(p(D=1|T=2) = 0.6\) (probabilidad de cara con moneda tipo B).
\(p(D=1|T=3) = 0.9\) (probabilidad de cara con moneda tipo C).
También:
\(p(T=1) = 0.4\) (probabilidad de elegir moneda tipo A).
\(p(T=2) = 0.4\) (probabilidad de elegir moneda tipo B).
\(p(T=3) = 0.2\) (probabilidad de elegir moneda tipo C).
Veamos algo de terminología:
Experimento: (todo el proceso que se sigue hasta obtener el resultado) se selecciona una moneda aleatoriamente del recipiente, se tira y se guarda el resultado.
Datos: el resultado del experimento. En este caso \(D=1\). Pensemos que los datos vienen dados por la variable aleatoria \(D\).
Hipotesis: estamos probando tres hipótesis. La moneda es tipo A (\(T=1\)), B (\(T=2\)), o C (\(T=3\)).
Probabilidad previa: la probabilidad para cada hipótesis antes de tirar la moneda. Dado que el recipiente tiene cinco monedas, dos (2) de tipo A, dos (2) de tipo B y una (1) de tipo C, tenemos que:
\[ p(T=1) = \frac{2}{5} = 0.4, \qquad p(T=2) = \frac{2}{5} = 0.4, \qquad p(T=3) = \frac{1}{5} = 0.2 \]
Verosimilitud: esta es la misma verosimilitud que ya veníamos viendo. La función de verosimilitud \(p(D | T)\) es la probabilidad de los datos dada la hipótesis. En el contexto de inferencia Bayesiana, consideramos los datos fijos, y una hipótesis variante. Por ejemplo, en este caso:
Probabilidad posterior: la probabilidad posterior de cada hipótesis dado el (los) dato(s):
\[ p(T=1 | D=1), \qquad p(T=2 | D=1), \qquad p(T=3 | D=1) \]Esto es lo que el problema nos pide encontrar.
Si nosotros utilizamos la regla de Bayes, tenemos que:
Observa que el numerador ya lo conocemos.
El denominador, no lo conocemos; pero podemos calcularlo.
Si recordamos, en las primeras sesiones comentamos sobre probabilidad total.
Finalmente, tenemos que:
Una vez que conocemos el denominador, podemos calcular la probabilidad posterior para cada valor de T:
Lo importante es ver cómo cambiaron mis probabilidad de las previas a las posteriores. Antes de tirar la moneda, pensaba que era más probable que la moneda fuera tipo A o B (ambas con probabilidad 0.4), y menos probable que fuera tipo C (probabilidad 0.2). Después de tirar la moneda y ver que salió cara, mi creencia cambió: ahora pienso que es más probable que la moneda sea tipo B (probabilidad posterior 0.387), seguida de tipo A (0.322) y finalmente tipo C (0.290).
from matplotlib import pyplot as plt
previa = [[1,2,3], [0.4,0.4,0.2]]
posterior = [[1,2,3], [0.322,0.387,0.290]]
fig, ax = plt.subplots(figsize=(8, 5))
ax.bar(previa[0],
previa[1], alpha=0.5, label='Previas $p(T)$', color='blue', width=0.4, align='edge')
ax.bar(posterior[0],
posterior[1], alpha=0.5, label='Posteriores $p(T|D=1)$', color='orange', width=-0.4, align='edge')
plt.xlabel('Tipos de moneda')
plt.ylabel('Probabilidad')
plt.title('Probabilidades previas y posteriores')
plt.legend()
plt.show()
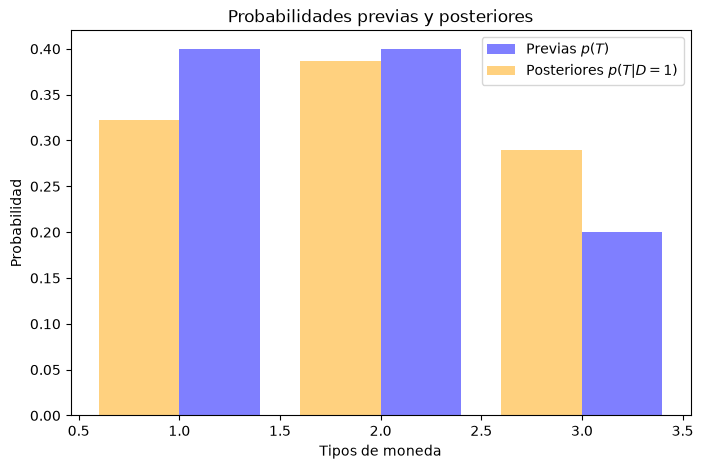
Tabla de actualización Bayesiana#
Notemos que la probabilidad total \(p(D=1)\) es la misma en todos los denominadores y que es la suma de los tres numeradores. Podemos organizar lo anterior en una tabla de actualización Bayesiana:
Hipótesis |
Previa |
Verosimilitud |
Numerador de Bayes |
Posterior |
|---|---|---|---|---|
\(T\) |
\(p(T)\) |
\(p(D = 1 | T)\) |
\(p(D = 1 | T) p(T)\) |
\(p(T | D = 1)\) |
1 |
0.4 |
0.5 |
0.2 |
(0.2/0.62) = 0.322 |
2 |
0.4 |
0.6 |
0.24 |
(0.24/0.62) = 0.387 |
3 |
0.2 |
0.9 |
0.18 |
(0.18/0.62) = 0.290 |
total |
\(1\) |
NO SE SUMA |
\(p(D = 1) = 0.62\) |
\(1 \) |
Observaciones
El numerador de Bayes es el producto de la previa y la verosimilitud.
Vemos en los cálculos que las probabilidades posteriores se obtienen dividiendo el numerador de Bayes entre \(p(D=1)=0.62\).
El denominador, que se obtiene por la ley de probabilidad total, es la suma de todos los numeradores de Bayes.
Observa que, al ser la suma de los numeradores, el denominador se mantiene constante para todas las hipótesis.
Esto nos hace pensar que estamos normalizando los numeradores de Bayes para obtener las probabilidades posteriores.
Actualización Bayesiana
El proceso de pasar de la probabilidad previa \(p(T)\) a la probabilidad posterior \(p(T|D=1)\) se conoce como actualización Bayesiana. Este proceso usa los datos y la regla de Bayes para actualizar nuestras probabilidades de cada una de las hipótesis.
Notas.
La probabilidad posterior para cada hipótesis en la útima columna, nos dice que ahora la moneda tipo B es la más probable, aunque su probabilidad bajó de la previa de 0.4 a la posterior de 0.39. La probabilidad de la moneda tipo C incrementó de 0.2 a 0.29.
El numerador de Bayes determina la probabilidad posterior, la cual se obtiene simplemente reescalando los numeradores para que sumen uno.
Si lo único que nos importara fuera la hipótesis más probable, el numerador de Bayes nos funcionaría igual de bien que la posterior normalizada.
Hipótesis |
Previa |
Verosimilitud |
Numerador de Bayes |
Posterior |
|---|---|---|---|---|
\(T\) |
\(p(T)\) |
\(p(D = 1 | T)\) |
\(p(D = 1 | T) p(T)\) |
\(p(T | D = 1)\) |
1 |
0.4 |
0.5 |
0.2 |
(0.2/0.62) = 0.322 |
2 |
0.4 |
0.6 |
0.24 |
(0.24/0.62) = 0.387 |
3 |
0.2 |
0.9 |
0.18 |
(0.18/0.62) = 0.290 |
total |
\(1\) |
NO SE SUMA |
\(p(D = 1) = 0.62\) |
\(1 \) |
Podríamos decir que el numerador de Bayes es una distribución no normalizada.
Con esto en mente, recuerda que la regla de Bayes también se puede escribir como:
\(p(datos)\) entonces, es una constante respecto a la hipóstesis y solo nos sirve para normalizar la probabilidad posterior.
Por tanto:
o equivalentemente:
2. Actualizamos…#
Modelos bayesianos pueden aprender online. Esto significa que pueden actualizar sus creencias a medida que reciben nuevos datos, en lugar de requerir un conjunto de datos completo para el entrenamiento. Este enfoque es especialmente útil en situaciones donde los datos llegan de manera secuencial o en tiempo real.
De hecho, los nuevos datos que se integran al cálculo de la probabilidad pueden ser deshechados después de la actualización, ya que la probabilidad posterior ya incorpora toda la información relevante de los datos previos. Esto permite que el modelo se adapte rápidamente a nueva información sin necesidad de almacenar todos los datos históricos.
Ejemplo 2#
Supongamos que elegimos una moneda como en el ejemplo anterior. La tiramos y obtenemos cara. Tomamos la misma moneda y la tiramos, y volvemos a obtener cara.
¿Cuál es la probabilidad de que la moneda sea tipo A?, ¿O tipo B?, ¿O tipo C?
Solución. Retomamos la tabla del ejemplo anterior, ahora llamando \(D_1\) a la variable que representa el primer tiro de la moneda y \(D_2\) a la variable que representa el segundo tiro:
Hipótesis |
Previa |
Verosimilitud |
Numerador de Bayes 1 |
Posterior |
|---|---|---|---|---|
\(T\) |
\(p(T)\) |
\(p(D_1 = 1 | T)\) |
\(p(D_1 = 1 | T) p(T)\) |
\(p(T | D_1 = 1)\) |
\(1\) |
\(0.4\) |
\(0.5\) |
\(0.2\) |
\(0.3226\) |
\(2\) |
\(0.4\) |
\(0.6\) |
\(0.24\) |
\(0.3871\) |
\(3\) |
\(0.2\) |
\(0.9\) |
\(0.18\) |
\(0.2903\) |
total |
\(1\) |
NO SE SUMA |
\(p(D_1 = 1) = 0.62\) |
\(1\) |
Podemos actualizar el calculo de la probabilidad posterior, pensando en que la previa es ahora la probabilidad posterior que obtuvimos en el primer tiro. Es decir, el resultado de la posterior del primer tiro es la previa del segundo tiro.
Hipótesis |
Previa |
Verosimilitud |
Numerador de Bayes (2) |
Posterior |
|---|---|---|---|---|
\(T\) |
\(p(T|D_1=1)\) |
\(p(D_2 = 1 | T, D_1=1)\) |
\(p(D_2 = 1 | T, D_1=1) p(T|D_1=1)\) |
\(p(T | D_1 = 1, D_2 = 1)\) |
\(1\) |
\(0.3226\) |
\(0.5\) |
\(0.1613\) |
\(0.2463\) |
\(2\) |
\(0.3871\) |
\(0.6\) |
\(0.2323\) |
\(0.3547\) |
\(3\) |
\(0.2903\) |
\(0.9\) |
\(0.2613\) |
\(0.3990\) |
total |
\(1\) |
NO SE SUMA |
\(0.6549\) |
\(1\) |
Como se señaló anteriormente, el numerador ya contiene toda la información. La posterior no es nada más que una renormalización del numerador.
Entonces, para la previa en lugar de utilizar la posterior anterior, bien podríamos haber utilizado el numerador de bayes anterior.
Podemos usar el numerador 1 para construir el numerador 2.
Hipótesis |
Numerador de Bayes 1 |
Verosimilitud |
Numerador de Bayes 2 |
Posterior |
|---|---|---|---|---|
\(T\) |
\(p(D_1 = 1 | T) p(T)\) |
\(p(D_2 = 1 | T)\) |
\(p(D_2 = 1 | T) p(D_1 = 1 | T) p(T)\) |
\(p(T | D_1 = 1, D_2 = 1)\) |
\(1\) |
\(0.2\) |
\(0.5\) |
\(0.1\) |
\(0.2463\) |
\(2\) |
\(0.24\) |
\(0.6\) |
\(0.144\) |
\(0.3547\) |
\(3\) |
\(0.18\) |
\(0.9\) |
\(0.162\) |
\(0.3990\) |
total |
\(0.62\) |
NO SE SUMA |
\(0.406\) |
\(1\) |
Notemos que en las dos tablas, la columna posterior tiene exactamente los mismos valores.
previa = [[1,2,3], [0.322,0.387,0.290]]
posterior = [[1,2,3], [0.246,0.354,0.399]]
fig, ax = plt.subplots(figsize=(8, 5))
ax.bar(previa[0],
previa[1], alpha=0.5, label='Previas $p(T|D_1=1)$', color='blue', width=0.4, align='edge')
ax.bar(posterior[0],
posterior[1], alpha=0.5, label='Posteriores $p(T|D_1=1,D_2=1)$', color='orange', width=-0.4, align='edge')
plt.xlabel('Tipos de moneda')
plt.ylabel('Probabilidad')
plt.title('Probabilidades previas y posteriores')
plt.legend()
plt.show()
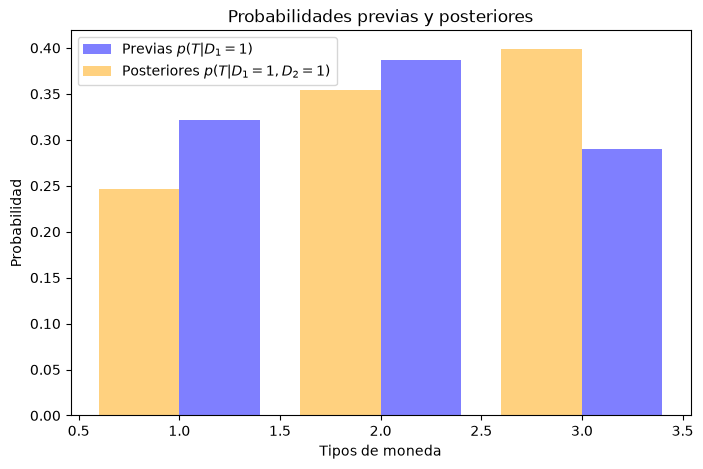
Como podemos observar, la hipótesis \(T=3\) es ahora lo más probable.
Probabilidad predictiva#
Conexión entre distribución posterior y probabilidades predictivas#
Hasta ahora hemos trabajado con la estimación de la distribución posterior. El objetivo era responder a la pregunta:
Dada la evidencia observada, (por ejemplo, que al lanzar la moneda salió cara), ¿cuál es la probabilidad de que la moneda sea de cierto tipo?
Con esto logramos actualizar nuestras creencias sobre las hipótesis (tipos de moneda) a partir de los datos observados.
Sin embargo, en muchos casos, no solo nos interesa identificar cuál hipótesis es más probable, sino también hacer predicciones sobre lo que ocurrirá en futuros experimentos.
Aquí es donde entran en juego dos conceptos nuevos y fundamentales: probabilidad predictiva previa y probabilidad predictiva posterior.
Probabilidad predictiva previa#
Se calcula antes de observar ningún dato.
Responde a: si tomo una moneda al azar del recipiente y la lanzo, ¿cuál es la probabilidad de que salga cara (o sello)?
Se obtiene combinando las probabilidades a priori con la ley de probabilidad total.
Ejemplo 3#
Retomamos el ejemplo que hemos venido trabajando, donde tenemos tres tipos monedas que son indistinguibles, solo tienen diferente probabilidad de caer en cara:
Tipo A: moneda justa, con probabilidad de cara de \(0.5\).
Tipo B: moneda cargada, con probabilidad de cara de \(0.6\).
Tipo C: moneda cargada, con probabilidad de cara de \(0.9\).
Tenemos un recipiente con CUATRO monedas, dos (2) de tipo A, una (1) de tipo B y una (1) de tipo C.
Previa
Probabilidad total
Pregunta. ¿Cuánto es \(p(D=0)\)?
Estas probabilidades dan una predicción (probabilística) de lo que sucederá si la moneda se tira. Dado que se calculan antes de obtener datos, con las probabilidades previas se conocen como probabilidades predictivas previas.
Probabilidad predictiva posterior#
Se calcula después de observar datos y actualizar las creencias sobre los tipos de monedas.
Responde a: dada la evidencia observada, ¿qué probabilidad hay de que en el próximo lanzamiento salga cara?
Se obtiene combinando las distribuciones posteriores con las probabilidades de cada tipo de moneda.
Ejemplo 4#
Retomando el Ejemplo 2, obtuvimos que la moneda más probable es la tipo C, con probabilidad posterior de 0.399.
Pregunta predictiva:
Cálculo numérico con numpy#
Probabilidad de cara según cada hipótesis:
import numpy as np
# Probabilidades de cara para cada tipo de moneda
p_cara = np.array([0.5, 0.6, 0.9])
p_cara
array([0.5, 0.6, 0.9])
Posterior sobre \(T\) después de dos caras:
# Posterior sobre T después de dos caras
posterior_T = np.array([0.246, 0.355, 0.399])
posterior_T
array([0.246, 0.355, 0.399])
Predicción:
Sustitución de valores
# Probabilidad predictiva
p_predictiva = np.sum(p_cara * posterior_T)
p_predictiva
np.float64(0.6951)
Resultado numérico
#print
Respuesta concreta
Con el ejemplo 2 obtuvimos que la moneda más probable es la tipo C, con probabilidad posterior de \(0.399\).
Aún cuando la moneda tipo C es la más probable, la probabilidad de que el tercer lanzamiento sea cara no es \(0.9\), sino un promedio ponderado de las posteriores: \(\approx 0.695\).
Estas nuevas probabilidades dan una predicción (probabilística) de lo que sucederá si la moneda se tira nuevamente. Dado que se calculan después de obtener datos y actualizar las previas a las posteriores, se conocen como probabilidades predictivas posteriores.
Conclusiones#
La posterior nos da información sobre las hipótesis dado un resultado.
Las predictivas nos permiten hacer pronósticos sobre nuevos resultados, ya sea antes de observar datos (previa) o después de actualizar con datos (posterior).