Sesion 2#
Repaso de teoría de probabilidad#
La incertidumbre es un aspecto inevitable en la mayoría de aplicaciones; incluso, el debate si el mundo es determinista o estocástico es un debate abierto. Aún en el supuesto que el mundo siguiera un comportamiento determinista, las fuentes de incertidumbre están ahí, ya sea por una medición ruidosa, que los datos sean finitos, entre otros.
En este sentido, es de vital importancia modelar esta incertidumbre dentro de los fenómenos de interés. Es por esto que los modelos que se consideran en este curso (y en gran parte de sus carreras profesionales) son probabilísticos.
Por esa razón haremos un breve repaso de los conceptos que necesitaremos de teoría de probabilidad.
Objetivos:
Repasar definiciones y resultados básicos de teoría de probabilidad.
Referencias:
Pattern Recognition and Machine Learning, by Christopher M. Bishop. Cap 1.2.
Bayesian Reasoning and Machine Learning by David Barber. Cap. 1.
Probabilistic Graphical Models: Principles and Techniques, by Daphne Koller and Nir Friedman. Cap. 2.
https://ocw.mit.edu/courses/18-05-introduction-to-probability-and-statistics-spring-2022/mit18_05_s22_probability.pdf
A) Probabilidad vs estadística#
Los campos de probabilidad y estadística están profundamente interrelacionados. De hecho, es común que no se establezca una distinción clara entre ambos. Esto se debe a que los métodos y resultados de la estadística se formulan, en última instancia, sobre fundamentos probabilísticos.
La probabilidad es el estudio lógico y matemático formal de la incertidumbre. Para ello, se apoya en un conjunto de reglas bien definidas (que estudiaremos en este cuaderno), a partir de las cuales las respuestas se derivan de manera lógica. Cabe señalar que, aunque las reglas sean precisas, los cálculos que se obtienen al aplicarlas pueden llegar a ser considerablemente complejos.
Por ejemplo, un problema probabilístico es el siguiente: se tiene una moneda justa (con igual probabilidad de cara y sello) y se lanza 100 veces. ¿Cuál es la probabilidad de obtener 60 o más caras? Este problema tiene una única respuesta correcta (aproximadamente 0.028444), y aprenderemos a calcularla.
La estadística, por su parte, utiliza la probabilidad como herramienta para extraer conclusiones a partir de datos observados.
Por ejemplo, un problema estadístico es el siguiente: se tiene una moneda de procedencia desconocida y, para investigar si es justa, se lanza 100 veces y se observa el número de caras obtenidas. Supongamos que se obtienen 60 caras. El objetivo del estadístico es entonces extraer conclusiones (inferencia) a partir de estos datos. Existen diversas formas de hacerlo, que dependen tanto del tipo de conclusión que se desea obtener como de los métodos y cálculos empleados.
Diferencia entre probabilidad y estadística
La probabilidad parte de un modelo conocido y bien definido, y a partir de él deduce qué resultados son más o menos plausibles. Su razonamiento va del modelo a los resultados: dados ciertos supuestos, calcula la probabilidad de eventos.
La estadística parte de datos observados, usualmente provenientes de un proceso desconocido, y utiliza la probabilidad para inferir propiedades de dicho proceso. Su razonamiento va de los datos al modelo: a partir de observaciones, se extraen conclusiones, estimaciones o decisiones.
Entonces,
Probabilidad: modelo conocido → conclusiones probabilísticas
Estadística: datos observados → inferencia sobre el modelo o la población
La probabilidad proporciona las reglas para cuantificar la incertidumbre, mientras que la estadística las utiliza para aprender de los datos y tomar decisiones bajo incertidumbre.
B) Interpretación frecuentista y bayesiana de la probabilidad#
Es importante notar que, en este punto, la probabilidad es un objeto estrictamente matemático, cuya definición está separada del proceso mediante el cual se asignan probabilidades a los eventos.
Pero surge una pregunta fundamental:
¿Cómo se asignan o calculan esos valores de probabilidad en la práctica?
La respuesta depende de la interpretación que adoptemos sobre qué representa una probabilidad en un contexto real.
A continuación, exploramos dos de las interpretaciones más influyentes y ampliamente utilizadas: la frecuentista y la bayesiana.
Interpretaciones de la probabilidad
Nivel formal (matemático): define qué es una probabilidad y cómo debe comportarse.
Nivel interpretativo (aplicado): explica cómo asignar probabilidades a eventos reales y cómo entender su significado.
B.1. Interpretación frecuentista#
Si repetimos un experimento muchas veces, el cociente entre el número de veces que ocurre un evento y el total de repeticiones se usa como una estimación de su probabilidad. Este valor es lo que se conoce como la frecuencia relativa.
Este valor se llama frecuencia relativa del evento:
A medida que el número de experimentos crece, esta frecuencia relativa tiende (bajo ciertas condiciones) a estabilizarse en un valor fijo. Este valor es interpretado como la probabilidad del evento desde el punto de vista frecuentista.
Frecuencia relativa
La frecuencia relativa es el cociente entre el número de veces que ocurre un evento y el número total de repeticiones del experimento. En el enfoque frecuentista, esta proporción se interpreta como la probabilidad del evento, especialmente cuando el número de repeticiones es grande.
Ejemplo
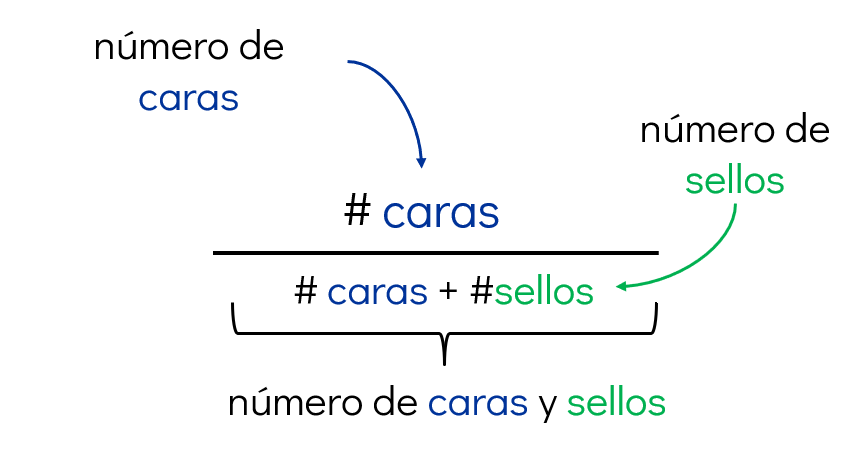
Si lanzamos una moneda 1000 veces y cae cara en 502 de ellas, entonces:
Al aumentar el número de repeticiones, esta estimación se estabiliza. Podemos observar este fenómeno en la Figura 1.
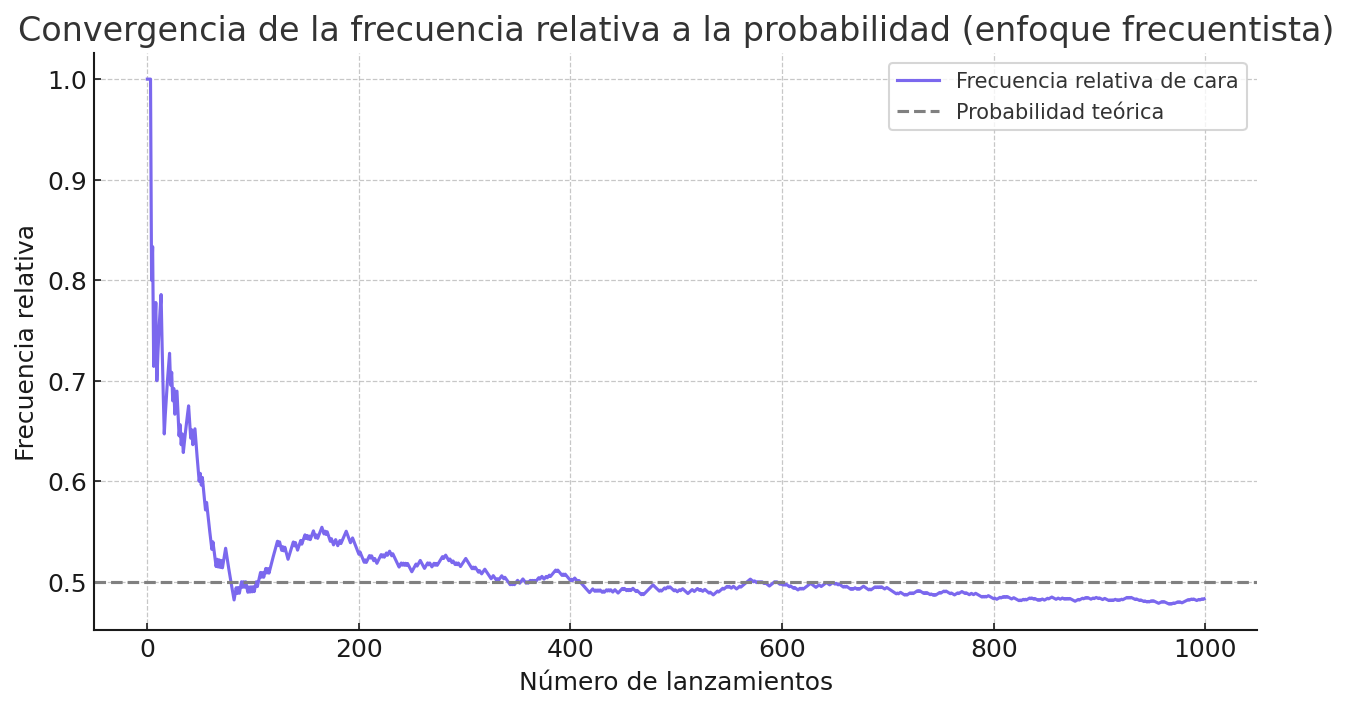
Figura 1. En el enfoque frecuentista, la probabilidad se interpreta como el valor al que tiende la frecuencia relativa de un evento (por ejemplo, «cara» en una moneda) conforme se incrementa el número de repeticiones del experimento.
¿Es sólo una fórmula?
Aunque el enfoque frecuentista utiliza la frecuencia relativa para estimar la probabilidad, no se reduce solamente a una fórmula.
Este enfoque implica una forma específica de entender qué es una probabilidad:
La probabilidad de un evento se define como el límite de su frecuencia relativa al repetir el experimento muchas veces.
Se asume que las probabilidades son propiedades objetivas del mundo, no creencias subjetivas.
No se habla de probabilidades en eventos únicos o no repetibles, como “la probabilidad de que llueva mañana”.
Por tanto, el frecuentismo es una postura matemática y filosófica, no solo un método de cálculo.
Fundamento teórico
El hecho de que la frecuencia relativa se estabilice a medida que aumenta el número de repeticiones está respaldado por un resultado matemático conocido como la ley de los grandes números.
B.2. Interpretación bayesiana#
¿Qué significa decir que algo tiene cierta probabilidad de ocurrir desde la perspectiva bayesiana?
El enfoque bayesiano propone una forma muy intuitiva de verlo:
La probabilidad es una medida de qué tanto creemos que algo es cierto, basándonos en lo que sabemos hasta ahora.
Así, para los bayesianos, la probabilidad no es una propiedad fija del mundo como “la gravedad”, sino más bien una forma de representar nuestra incertidumbre. Y lo más importante:
💡 Esa creencia puede cambiar si recibimos nueva información.
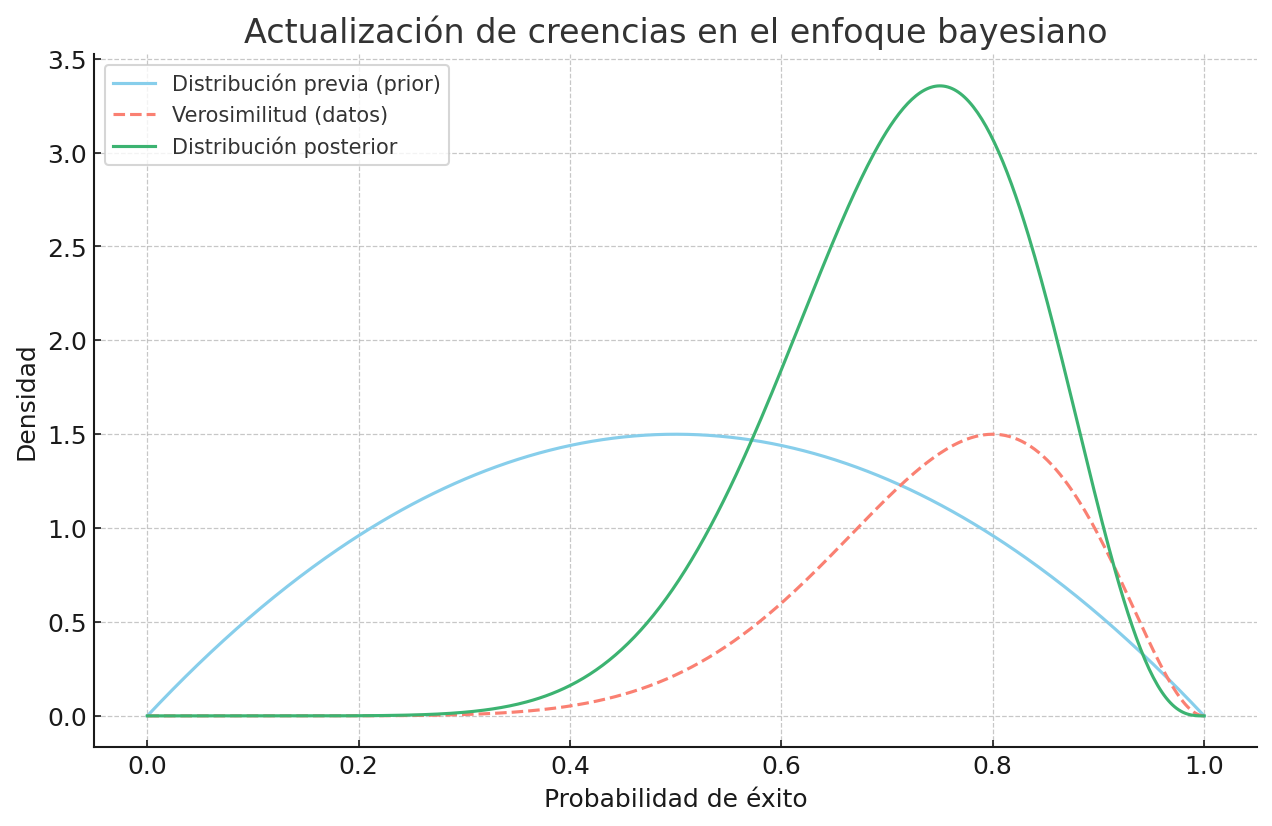
Figura 2. En el enfoque bayesiano, una creencia inicial (distribución prior, línea azul) se combina con la evidencia aportada por los datos (verosimilitud, línea roja) para producir una creencia actualizada (posterior, línea verde). Esto se realiza aplicando el Teorema de Bayes.
Históricamente, el enfoque frecuentista ha dominado áreas como la biología, la medicina, la salud pública y las ciencias sociales. En contraste, el enfoque bayesiano ha experimentado un fuerte resurgimiento en la era de las computadoras de alto rendimiento y el big data, donde su flexibilidad y capacidad para incorporar información previa resultan especialmente valiosas.
Es importante enfatizar que no se trata de dos bandos excluyentes entre los que haya que elegir. Ambos enfoques responden a preguntas distintas y pueden utilizarse de manera complementaria, aprovechando las fortalezas de cada uno según el problema y el contexto de análisis.
C) Introducción a probabilidad#
Para introducir algunos conceptos básicos de probabilidad, usamos un ejemplo bastante sencillo (tomado de Pattern Recognition and Machine Learning, by Christopher M. Bishop):
Supongamos que tenemos dos cajas: una roja y una azul.
En la caja roja hay 2 manzanas y 6 naranjas.
En la caja azul hay 3 manzanas y 1 naranja.
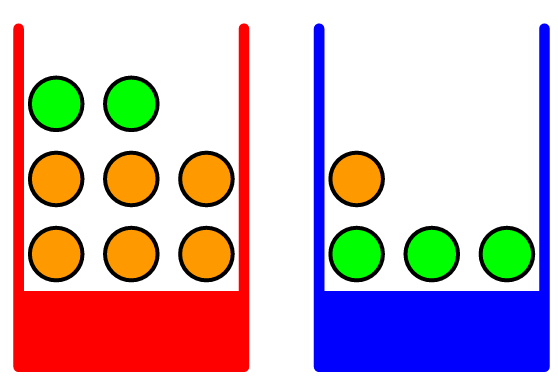
Experimento
Imaginemos que seleccionamos aleatoriamente una de las cajas, 40% de las veces seleccionamos la caja azul y el 60% de las veces seleccionamos la caja roja, y de la caja seleccionada tomamos aleatoriamente una fruta, con igual probabilidad de seleccionar cualquier cualquier elemento dentro de la caja. Finalmente devolvemos la fruta a la caja original.
Definimos la identidad de la caja que seleccionamos como una variable aleatoria (V.A.), la cual denotamos como \(C\), y puede tomar los valores r y a.
Similarmente, definimos la identidad de la fruta seleccionada como una V.A., denotada por \(F\), y que puede tomar los valores m y n.
¿cómo definimos la probabilidad de un evento?#
Definiremos la probabilidad de un evento como la fracción de veces que ocurre este evento entre la cantidad de repeticiones, cuando el número de repeticiones tiende a infinito.
En este sentido, las probabilidades de seleccionar:
La caja roja: \(p(C=r) = \frac{6}{10} = 0.6\)
La caja azul azul: \(p(C=a) = \frac{4}{10} = 0.4\)
A la luz de esta definición se intuyen dos reglas muy importantes:
Cualquier probabilidad debe ser un número en el intervalo \([0,1]\):
\[ 0 \leq p(X=x) \leq 1. \]Si los eventos son mutuamente excluyentes (la caja no puede ser roja y azul a la vez, por lo menos en este ejemplo), y son exhaustivos (la caja solo puede ser roja o azul), las probabilidades suman 1:
\[ \sum_{x} p(X=x) = 1. \]
Ejercicio intuitivo#
Podemos preguntarnos:
¿Cuál es la probabilidad de seleccionar una manzana?
Dado que elegimos una naranja, ¿Cuál es la probabilidad que la caja haya sido la azul?
Notemos que estas probabilidades no las conocemos de antemano. Incluso, notemos que son probabilidades que involucran más de una variable. Sin embargo, tenemos la información necesaria para inferir estas probabilidades, no sin antes conocer la regla de la suma (marginalización), y la regla del producto (regla de la cadena).
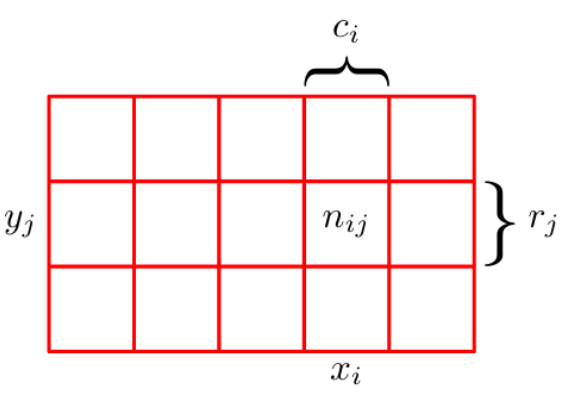
Para obtener estas reglas en nuestro modo intuitivo de estudiar probabilidad, consideremos el caso más general en que tenemos dos variables aleatorias \(X\) y \(Y\), las cuales pueden tomar los valores \(x^i\) para \(i=0,\dots,s\) y \(y^j\) para \(j=0,\dots,t\).
Supongamos que, de un total de \(N\) repeticiones,
en \(n_{ij}\) ocasiones obtuvimos \(X=x^i\) y \(Y=y^j\);
en \(c_{i}\) ocasiones obtuvimos \(X=x^i\), sin importar el valor de \(Y\);
en \(r_{j}\) ocasiones obtuvimos \(Y=y^j\), sin importar el valor de \(X\);
De nuestra definición de probabilidad, tenemos que (suponiendo que \(N \to \infty\)):
Probabilidad conjunta#
La probabilidad conjunta de que \(X=x^i\) y \(Y=y^j\) es:
\[ p(X=x^i, Y=y^j) = \frac{n_{ij}}{N}. \]
Probabilidad marginal#
La probabilidad marginal de que \(X=x^i\) sin importar el valor de Y es;
\[ p(X=x^i) = \frac{c_{i}}{N}. \]Notemos que \(c_i = \sum_j n_{ij}\), y en este sentido podemos establecer la regla de la suma (marginalización):
\[ p(X=x^i) = \sum_{j=0}^{t} p(X=x^i, Y=y^j). \]Similarmente, podemos definir la probabilidad marginal \(p(Y=y^j)\).
Probabilidad condicional#
Si en lugar de considerar todos los posibles repeticiones, consideramos solo aquellas para las que \(X=x^i\), entonces la fracción de dichas repeticionesoara las cuales \(Y=y^j\), la conocemos como probabilidad condicional de \(Y=y^j\) dado \(X=x^i\), y la escribimos como:
\[ p(Y=y^j | X=x^i) = \frac{n_{ij}}{c_i}. \]
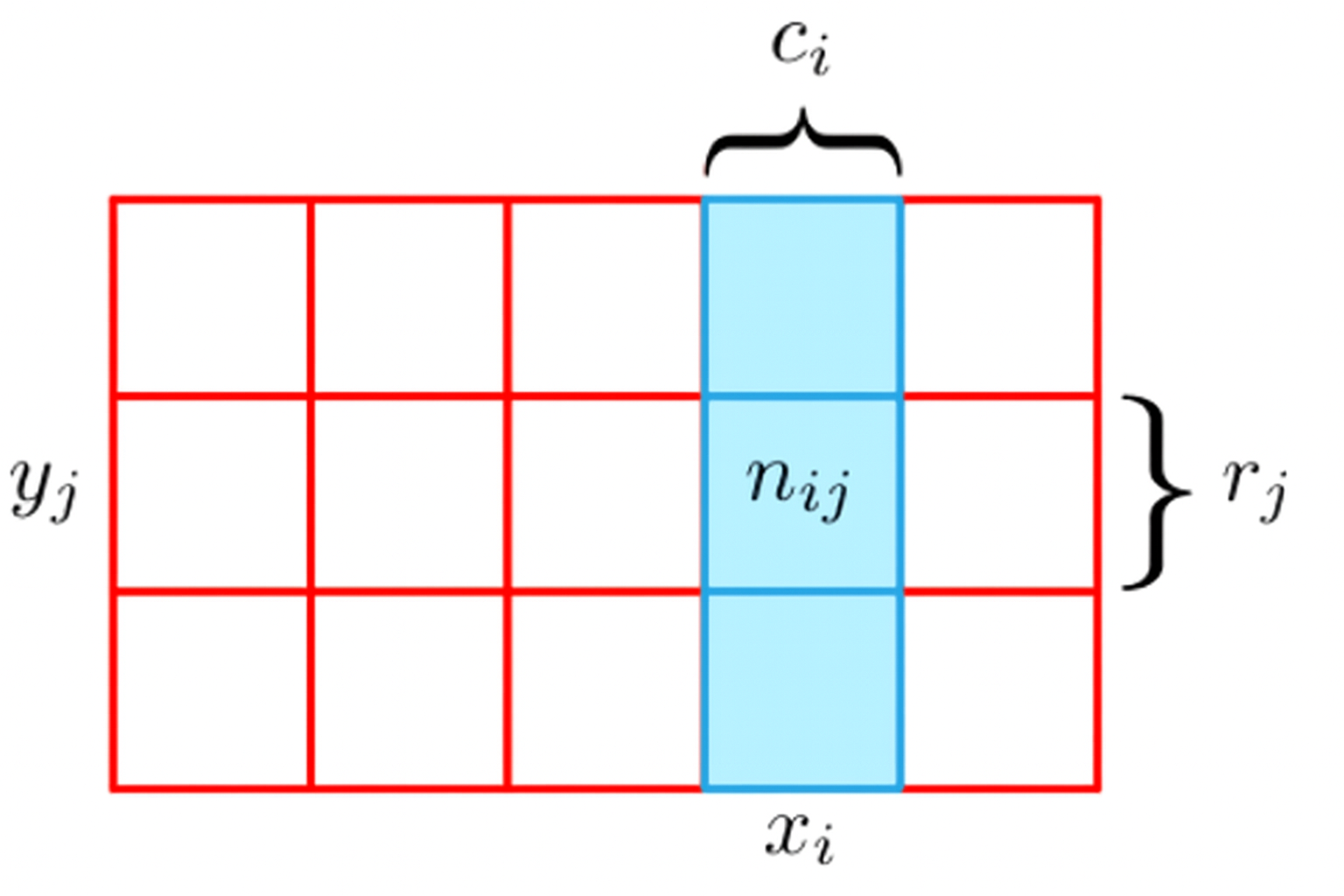
Podemos observar que la probabilidad conjunta, la podemos escribir como:
dando lugar a la regla del producto (regla de la cadena), y dando lugar a la definición de probabilidad condicional.
La probabilidad condicional de una variable aleatoria \(Y\) condicionada a que conocemos la variable aleatoria \(X\) (la probabilidad de \(Y\) dado \(X\)), se define como:
siempre que \(p(X)>0\). Si \(p(X)=0\), entonces \(p(Y|X)\) no está definida.
La probabilidad condicional es una distribución de probabilidad válida, en el sentido que:
\(0 \leq p(Y|X) \leq 1\), y
\(\sum_{Y} p(Y|X) = 1\).
Ejemplo.
Supongamos que se tira una moneda justa 3 veces.
¿Cuál es la probabilidad de obtener 3 caras?
Descubrir
Tenemos los siguientes posibles resultados, donde C denota cara y S denota sello: $\( \{CCC, CCS, CSC, SCC, CSS, SCS, SSC, SSS\} \)$
Todos los resultados son igualmente probables, de modo que \(p(\text{3 caras}) = \frac{1}{8}\).
Suponga que sabemos que el primer resultado del tiro fue cara. Con esta información, ¿Cómo podemos calcular la probabilidad de obtener 3 caras?
Descubrir
El conjunto de resultados se reduce a: $\( \{CCC, CCS, CSC, CSS\} \)$
Todos los resultados son igualmente probables, de modo que \(p(\text{3 caras} | \text{cara en primer tiro}) = \frac{1}{4}\).
Notemos que, a partir de la definición:
Observación en la notación. Originalmente, escribimos \(p(X=x)\) para referirnos al evento en que la variable aleatoria \(X\) toma el valor \(x\). Esta notación elimina «incertidumbre», pero es algo engorrosa. De manera que, en adelante, escribiremos simplemente \(p(x)\) para referirnos a la probabilidad del evento \(x\), y \(p(X)\) para referirnos a la distribución de probabilidad de la V.A. \(X\).
Regla de la cadena#
De la definición de probabilidad condicional, se desprende automáticamente lo que conocemos como la regla de la cadena en probabilidad:
Regla de probabilidad total#
Teniendo a la mano la regla de la cadena, y la marginalización, podemos escribir la regla de probabilidad total como:
y se puede entender como una constante de normalización para asegurar que la probabilidad condicional sea una distribución de probabilidad válida.
Resumen
\(0 \leq p(X) \leq 1\): Definición de probabilidad (i)
\(\sum_X p(X) = 1\): Definición de probabilidad (ii)
\(p(X) = \sum_{Y} p(X, Y)\): Marginalización
\(p(X, Y) = p(Y | X) p(X) = p(X | Y) p(Y)\): Regla de la cadena
\(p(X) = \sum_Y p(X | Y) p(Y)\): Probabilidad total: marginalización + r. cadena
Las preguntas iniciales eran:
¿Cuál es la probabilidad de seleccionar una manzana?
Primero que nada, las probabilidades que tenemos son:
Descubrir
En este sentido, y usando la regla de la probabilidad total:
Dado que elegimos una naranja, ¿Cuál es la probabilidad que la caja haya sido la azul?
Descubrir
Ahora, podemos usar la regla de Bayes:
de donde ya conocemos \(p(n | a)\) y la previa \(p(a)\). Adicionalmente,
Por lo cual:
La respuesta a la segunda pregunta es bastante interesante, y demuestra el proceso fundamental de incorporar evidencia en un problema.
Notemos que, antes de saber qué fruta elegimos, la probabilidad previa de elegir la caja azul es \(p(a) = \frac{4}{10}\).
Ahora, al incorporar la evidencia de que la fruta que elegimos fue una naranja, observamos que la probabilidad posterior de elegir la caja azul disminuyó considerablemente a \(p(a | n) = \frac{2}{11}\).
Lo anterior es intuitivo, dado que la proporción de naranjas es significativamente más alta en la caja roja (\(p(n | r) = \frac{3}{4}\)) que en la caja azul (\(p(n | a) = \frac{1}{4}\)).
Por esta bondad de añadir información de evidencia a nuestras inferencias es por lo que la regla de Bayes es tan relevante.
D) Teorema de Bayes#
El teorema de Bayes es un pilar fundamental de probabilidad y estadística. Aunque su derivación es sencilla, las implicaciones que tiene son bastante poderosas.
Dado que la probabilidad conjunta es simétrica, esto es \(p(X, Y) = p(Y, X)\), de la definición de probabilidad condicional obtenemos que:
De lo anterior, usando las igualdades de los extremos, obtenemos la regla de Bayes:
La regla de Bayes nos dice cómo invertir probabilidades condicionales, es decir, nos permite encontrar \(p(Y|X)\) a partir de \(p(X|Y)\).
En la práctica, es común calcular \(p(X)\) usando la regla de la probabilidad total: $\( p(Y | X) = \frac{p(X | Y) p(Y)}{p(X)} = \frac{p(X | Y) p(Y)}{\sum_{Y} p(X|Y)p(Y)} . \)$
Ejemplo. Se tira una moneda 5 veces. Queremos analizar los eventos
F: el primer tiro es cara
T: todos los 5 tiros son cara.
En particular \(p(T | F)\).
Es fácil observar que \(p(F | T) = 1\). También, sabemos que \(p(T) = \left(\frac{1}{2}\right)^5 = \frac{1}{32}\). Finalmente, \(p(F) = \frac{1}{2}\).
Finalmente, aplicando la regla de Bayes:
E) Concepto de independencia#
A partir de la definición y de la regla de la probabilidad condicional y suponiendo que \(p(X)>0\) y \(p(Y)>0\), podemos ver que de la definición de probabilidad condicional:
\(Y\) no me da información sobre \(X\).
y similarmente
\(X\) no me da información sobre \(Y\).
Sí, la independencia es una relación simétrica:
Ejemplo: independencia en una baraja#
Se selecciona una carta de una baraja de 52 cartas. Definimos los eventos:
\(A\): la carta es un As.
\(C\): la carta es de corazones.
\(R\): la carta es roja.
Descubrir
Sabemos que
\(p(A)=\frac{4}{52}=\frac{1}{13}\) (hay 4 A’s en una baraja),
\(p(A|C)=\frac{1}{13}\) (hay una A de los 13 corazones). Como \(p(A)=p(A|C)\), entonces sacar una A es independiente de sacar un corazón.
Similarmente,
\(p(A|R)=\frac{2}{26}=\frac{1}{13}\) (hay dos A’s de las 26 cartas rojas). Como \(p(A)=p(A|R)\), entonces sacar una A es independiente de sacar una carta roja.
¿Qué pasa con \(C\) y \(R\)? Tenemos que:
\(p(C)=\frac{13}{52}=\frac{1}{4}\)
\(p(C|R)=\frac{13}{26}=\frac{1}{2}\) Por lo que sacar una carta roja no es independiente de sacar un corazón. Esto es intuitivo.
Notar que el último caso, lo podríamos haber analizado en el otro sentido:
\(p(R)=\frac{26}{52}=\frac{1}{2}\)
\(p(R|H)=\frac{13}{13}=\frac{1}{1}\).
F) Independencia condicional#
La independencia es una propiedad útil, pero poco común en problemas reales: en la práctica, es raro que dos variables o eventos sean verdaderamente independientes.
Sin embargo, lo que sí ocurre con frecuencia es que dos variables sean independientes condicionalmente a una tercera.
Definición independencia condicional
Decimos que \(A\) y \(B\) son independientes condicionalmente a \(X\) si:
Esto significa que una vez que conocemos \(X\), la información sobre \(A\) ya no aporta nada adicional sobre \(B\) (y viceversa).
En otras palabras: \(X\) “rompe” la dependencia que pudieran tener \(A\) y \(B\).
A partir de la definición anterior, usando probabilidad condicional, se puede derivar:
Si sustituimos la definición de independencia condicional:
De manera simétrica:
Es decir, al condicionar en \(X\), \(A\) y \(B\) se comportan como si fueran independientes.
Ejemplo
Supón que queremos estimar la probabilidad de que una estudiante sea admitida a un posgrado en el ITAM o en el CINVESTAV.
Sea \(I\): «fue admitida al posgrado del ITAM»
Sea \(C\): «fue admitida al posgrado del CINVESTAV»
Normalmente, \(I\) y \(C\) no son independientes: saber que fue admitida al ITAM probablemente aumenta nuestra creencia de que también será admitida al CINVESTAV, porque sugiere que es una estudiante sobresaliente.
Ahora supongamos que sabemos que su promedio de licenciatura (\(G\)) es de 9.5 y que ambas instituciones basan su admisión únicamente en el promedio.
Entonces, dado \(G = 9.5\), los eventos \(I\) y \(C\) sí son independientes:
En este caso, decimos que \(C\) es condicionalmente independiente de \(I\) dado \(G\).