Sesión 5 B#
La distribución previa como regularizador#
Objetivos:
Comprender el principio de estimación Máximum A-Posteriori (MAP).
Entender el efecto de la distribución previa como regularizador.
I. Introducción#
En este cuaderno de trabajo exploraremos un enfoque intermedio entre la perspectiva bayesiana y la frecuentista.
Recordemos primero la visión frecuentista#
En el enfoque frecuentista aparece el concepto de estimadores puntuales.
Estimadores puntuales
Un estimador puntual es una función de los datos observados que proporciona una única estimación del valor de un parámetro desconocido.
Desde esta perspectiva:
Tenemos una situación con incertidumbre.
Para describirla, planteamos un modelo parametrizado por un conjunto de parámetros desconocidos.
El objetivo es encontrar el valor de esos parámetros que mejor se ajuste a los datos disponibles.
En notación matemática, podríamos escribir el modelo como:
Ideas clave en la visión frecuentista#
Los parámetros existen y son valores fijos, aunque no los conozcamos.
Lo que queremos es encontrar esos valores.
La incertidumbre no está en los parámetros, sino en los datos.
Como consecuencia, aparece la función de verosimilitud:
que mide qué tan probable es observar los datos bajo diferentes valores de \(\theta\).
La perspectiva bayesiana#
Veamos ahora el mismo problema desde la estadística bayesiana.
Partimos de la mismo situación:
Tenemos incertidumbre
Contamos con un modelo parametrizado
Y disponemos de un conjunto de datos observados
La diferencia clave está en cómo entendemos la fuente de la incertidumbre:
Para los frecuentistas, los datos son aleatorios y los parámetros son fijos (aunque desconocidos).
Para los bayesianos, sucede al revés:
Los datos ya están fijos (no hay incertidumbre en ellos una vez observados).
La incertidumbre está en los parámetros, porque no conocemos sus valores.
En otras palabras
Como bayesianos no nos preguntamos únicamente «¿cuál es el valor de \(\theta\) que mejor explica los datos?», sino «¿cuál es la probabilidad de cada posible valor de \(\theta\), dado lo que ya observamos?».
Matemáticamente, expresamos esta idea con la distribución posterior:
donde \(D\) son los datos (fijos) y \(\theta\) representa los parámetros (inciertos).
Un punto intermedio: el estimador MAP#
Hemos visto dos perspectivas:
Frecuentista: los parámetros son valores fijos (desconocidos) y la incertidumbre está en los datos.
Bayesiana: los parámetros tienen una distribución de probabilidad y la incertidumbre está en los parámetros, mientras que los datos observados son valores fijos.
Entre estos dos enfoques surge una visión intermedia, que da lugar a otros tipo de estimador: el estimador de máximo a posteriori (MAP).
¿qué significa el MAP?
Desde Bayes sabemos que la distribución posterior es proporcional a la verosimilitud multiplicada por la distribución previa:
En lugar de trabajar con toda la distribución posterior (como en Bayes puro), buscamos el valor de \(\theta\) que maximiza esta posterior.
Es decir, definimos el estimador MAP como:
II. Retomemos ajuste de curvas#
Con lo anterior dicho, volvamos a hablar del tema de ajuste de curvas con una perspectiva probabilística.
Partimos de nuevo modelando la relación entre nuestra variable de salida \(y\) y las variables de entrada \(x\) como un modelo lineal con incertidumbre, la cual suponemos normal:
con \(\epsilon \sim \mathcal{N}(0, \beta^{-1})\).
Equivalentemente, podemos decir que:
con esta suposición podemos determinar que la verosimilitud de un datos, sigue una distribución normal con:
Ya sabemos a donde nos conduce este modelo para la función de verosimilitud.
Alternativamente, encontremos una expresión para la distribución posterior de los parámetros, usando la regla de Bayes:
En este contexto, tenemos que:
\(p(w | y, X)\) es la distribución posterior de los parámetros dados los datos.
\(p(y | X, w) = \mathcal{L}(w) = \prod_{i=1}^{N} \mathcal{N}(y_i | \phi(x_i)^T w, \beta^{-1})\) es la función de verosimilitud.
\(p(y | X)\) es la distribución de evidencia.
\(p(w | X)\) es la distribución previa. Para este punto, una suposición que hace bastante sentido es que conocer únicamente las variables de entrada \(X\) no nos dice absolutamente nada acerca de los parámetros \(w\). Es decir, son independientes. Por tanto,
\[ p(w | X) = p(w). \]
Maximizar la distribución posterior (MAP)#
Aquí convergen los dos mundos, es decir, razonamos acerca de la distribución posterior de los parámetros con Bayes, pero tomaremos un valor puntual del parámetro más probable.
Maximizamos la distribución posterior:
El término de log-verosimilitud ya lo conocemos:
Conexión con la regularización#
Aquí aparece algo muy interesante que veremos a continuación, pero antes introduzcamos la distribución normal multivariable, puesto que nos será útil para obtener la función de densidad de probabilidad normal multivariada:
con parámetros \(\mu \in \mathbb{R}^d\): vector de medias de la V.A. \(X\) y \(\Sigma \in \mathbb{R}^{d \times d}\): matriz de covarianzas de la VA X (simétrica y definida positiva).
from scipy import stats
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
X = stats.multivariate_normal(
mean=[0, 0],
cov=[
[1, 0],
[0, 1]
]
)
Y = stats.multivariate_normal(
mean=[1, 1],
cov=[
[1, -0.8],
[-0.8, 1]
]
)
Intuición
Una normal multivariada puede imaginarse como una campana en varias dimensiones.
La media marca el centro de la campana.
La covarianza define la forma:
sin correlación → contornos circulares,
con correlación → contornos elípticos e inclinados.
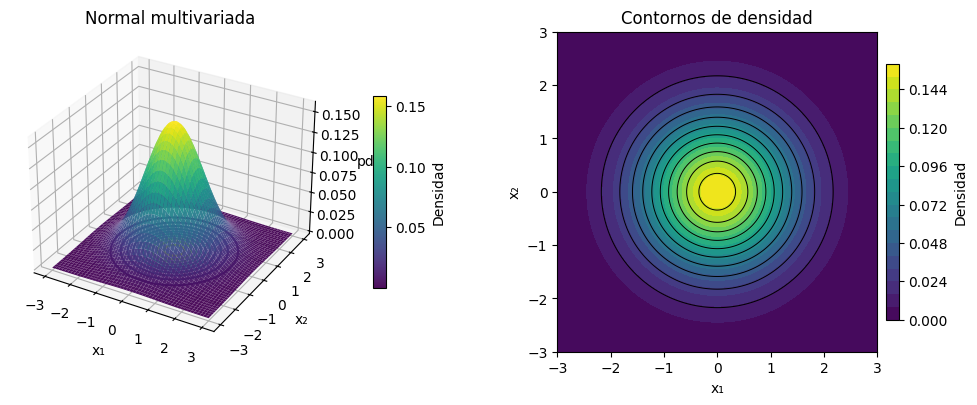
Figura 1. Distribución normal bivariada con media en \((0,0)\) y matriz de covarianza diagonal. Los contornos circulares reflejan independencia y dispersión igual en todas las direcciones.
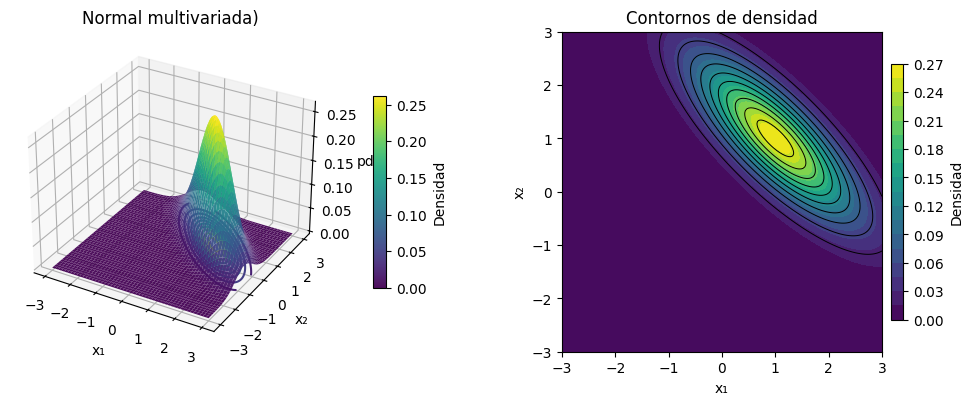
Figura 2. Distribución normal bivariada con media en \((1,1)\) y covarianza no diagonal. Los contornos elípticos inclinados muestran la correlación negativa entre las variables.
Matriz de covarianzas
La matriz de covarianza describe cómo varían las variables entre sí:
Diagonal → varianzas de cada variable (qué tan dispersas están).
Fuera de la diagonal → covarianzas (si aumentan o disminuyen juntas).
Valores positivos → relación directa,
Valores negativos → relación inversa,
Ceros → independencia (sin relación lineal).
En una normal multivariada, esta matriz es la que da forma y orientación a los contornos (círculos o elipses).
La pregunta es, ¿Qué es la distribución previa \(p(w)\)?
Este término nos permite expresar todo nuestro conocimiento previo acerca de los parámetros \(w\) de una manera probabilística, es decir, a través de una distribución de probabilidad.
Previa normal#
Una elección común es:
En este caso, podemos usar el parámetro \(\alpha\) para expresar cuanta certeza tenemos de que \(w\) está cercano a cero.
De lo anterior, observamos que:
Reemplazando en la expresión anterior y descartando todos los sumandos que no dependen de \(w\):
Entonces, observamos que la estimación de parámetros por MAP, usando una previa Gaussiana nos conduce a nuestra intuición detrás de mínimos cuadrados regularizados con norma-\(2\) (Ridge).
Previa de Laplace#
Otra previa común en este caso, es modelar la incertidumbre en los parámetros como una distribución de Laplace:
con lo cual, suponiendo que los parámetros son independientes:
En este caso, observamos que:
Con lo cual
Entonces, observamos que la estimación de parámetros por MAP, usando una previa de Laplace nos conduce a nuestra intuición detrás de mínimos cuadrados regularizados con norma-\(1\) (Lasso).
III. Conclusiones#
Desde la perspectiva probabilística, podemos reinterpretar el problema de ajuste de curvas y recuperar resultados clásicos de forma intuitiva.
Los estimadores de máxima verosimilitud (MLE) funcionan bien con muchos datos, pero tienden a sufrir de overfitting cuando la muestra es pequeña.
Los estimadores de máxima a posteriori (MAP) incorporan información previa sobre los parámetros mediante una distribución prior, lo que actúa como un mecanismo natural de regularización.