Apéndice B#
Lenguaje de modelos probabilísticos#
Objetivos:
Adoptar un lenguaje estándar para definir modelos probabilísticos.
Revisitar el modelo Gaussiano.
Aprenderemos a expresar modelos probabilísticos de forma estructurada y comprensible, usando el lenguaje estándar que emplean las y los científicos y estadístic@s.
Si pusiéramos todo en una serie de pasos, serían los siguientes:
Paso 1: Identificar las variables#
Pregúntate: ¿qué estoy observando y qué no?
Observables (datos): lo que medimos o contamos. En el ejemplo: cuántas veces la moneda cayó cara → eso es \(C\).
No observables (parámetros): lo que gobierna el proceso pero no conocemos directamente. En el ejemplo: la probabilidad de que salga cara → eso es \(p\).
Paso 2: Elegir la distribución adecuada para cada variable#
Pregúntate: ¿qué tipo de variable es y qué patrón tiene?
Tipo de fenómeno |
Distribución típica |
Ejemplo |
|---|---|---|
Conteo de éxitos en intentos fijos |
Binomial(N, p) |
Lanzar una moneda N veces y contar caras |
Medición continua (tiempos, alturas) |
Normal(μ, σ) |
Peso de personas |
Tasa de ocurrencia (eventos por minuto) |
Poisson(λ) |
Número de llamadas en una hora |
Valor desconocido pero entre 0 y 1 |
Uniform(0,1) o Beta(a,b) |
Probabilidad de éxito, proporciones |
Así, cuando decimos:
significa:
“El número de veces que sale cara, \(C\), sigue una distribución Binomial, con \(N\) ensayos y probabilidad \(p\) de éxito en cada uno.”
Paso 3: Modelar la incertidumbre sobre los parámetros#
En la práctica, no sabemos cuál es el valor real de \(p\), así que le asignamos una distribución previa (prior).
Esto significa:
“Antes de ver datos, creemos que todas las probabilidades entre 0 y 1 son igualmente posibles.”
En modelos bayesianos, este paso es crucial: refleja tu creencia inicial antes de observar los datos.
Paso 4: Combinarlo en un modelo generativo#
Ahora unes todo el “relato”:
Escoge un valor de \(p\) (la probabilidad de cara) al azar del intervalo (0,1).
Lanza la moneda \(N\) veces y cuenta cuántas caras obtienes (\(C\)).
Eso se traduce a:
Y eso es exactamente lo que significa el modelo: una descripción probabilística completa de cómo los datos podrían generarse.
Resumen
Escribir un modelo probabilístico implica todas las suposiciones sobre los datos (por ejemplo, independencia en una binomial).
El lenguaje probabilístico permite expresar comportamientos complejos sin escribir fórmulas extensas.
Las relaciones estocásticas se indican con ~ y representan variables aleatorias.
Las relaciones deterministas se indican con = y expresan dependencias fijas.
Modelo Gaussiano#
Instrucciones:
Modelaremos una variable como una distribución Gaussiana (normal), la cual sabemos que tiene dos parámetros: la media (\(\mu\)) y la varianza (\(\sigma^2\)).
import pandas as pd
import os
from scipy.stats import norm, uniform
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings('ignore')
ruta = os.path.join('..', '..', '..', 'docs', 'source', 'data')
ruta_data = os.path.join(ruta, 'Howell1.csv')
df = pd.read_csv(ruta_data, sep=';')
df.head()
| height | weight | age | male | |
|---|---|---|---|---|
| 0 | 151.765 | 47.825606 | 63.0 | 1 |
| 1 | 139.700 | 36.485807 | 63.0 | 0 |
| 2 | 136.525 | 31.864838 | 65.0 | 0 |
| 3 | 156.845 | 53.041914 | 41.0 | 1 |
| 4 | 145.415 | 41.276872 | 51.0 | 0 |
# describe()
df.describe()
| height | weight | age | male | |
|---|---|---|---|---|
| count | 544.000000 | 544.000000 | 544.000000 | 544.000000 |
| mean | 138.263596 | 35.610618 | 29.344393 | 0.472426 |
| std | 27.602448 | 14.719178 | 20.746888 | 0.499699 |
| min | 53.975000 | 4.252425 | 0.000000 | 0.000000 |
| 25% | 125.095000 | 22.007717 | 12.000000 | 0.000000 |
| 50% | 148.590000 | 40.057844 | 27.000000 | 0.000000 |
| 75% | 157.480000 | 47.209005 | 43.000000 | 1.000000 |
| max | 179.070000 | 62.992589 | 88.000000 | 1.000000 |
Se observa una alta variabilidad en los datos de altura, en parte debido a que incluyen personas de diferentes edades. A partir de ahora, nos centraremos únicamente en la población adulta.
adultos = df[df.age >= 18].copy()
adultos.describe()
| height | weight | age | male | |
|---|---|---|---|---|
| count | 352.000000 | 352.000000 | 352.000000 | 352.000000 |
| mean | 154.597093 | 44.990486 | 41.138494 | 0.468750 |
| std | 7.742332 | 6.456708 | 15.967855 | 0.499733 |
| min | 136.525000 | 31.071052 | 18.000000 | 0.000000 |
| 25% | 148.590000 | 40.256290 | 28.000000 | 0.000000 |
| 50% | 154.305000 | 44.792210 | 39.000000 | 0.000000 |
| 75% | 160.655000 | 49.292693 | 51.000000 | 1.000000 |
| max | 179.070000 | 62.992589 | 88.000000 | 1.000000 |
Para iniciar la construcción de nuestro modelo, asumimos que la altura de cada individuo sigue una distribución normal con media \(\mu\) y desviación estándar \(\sigma\):
Aunque no lo escribamos explícitamente, la suposición de que las observaciones son iid (independientes e idénticamente distribuidas) está implícita en esta formulación.
Como en los ejemplos anteriores, esta relación define la función de verosimilitud.
Para completar los elementos necesarios en la regla de Bayes, debemos especificar la distribución previa de los parámetros \(\mu\) y \(\sigma\), denotada como \(P(\mu, \sigma)\).
Por simplicidad, se suelen considerar independientes entre sí, lo que implica:
De esta forma, el modelo completo puede escribirse como:
¿Qué significan estas previas?
La previa para \(\mu\) es una previa Gaussiana algo amplia, centrada en \(170\) cm y con el \(95\)% de probabilidad concentrada en el intervalo \(170 \pm 40\) cm.
adultos.height
0 151.765
1 139.700
2 136.525
3 156.845
4 145.415
...
534 162.560
537 142.875
540 162.560
541 156.210
543 158.750
Name: height, Length: 352, dtype: float64
# previa para mu
prior_mu = norm(loc=170, scale=20)
#grafica previa mu
x = np.linspace(100, 250, 200)
y = prior_mu.pdf(x)
plt.plot(x, y, label='Previa para $\mu$', color='blue')
plt.fill_between(x, y, alpha=0.2, color='blue')
plt.title('Distribución previa para $\mu$')
plt.xlabel('$\mu$ (Altura en cm)')
plt.ylabel('Densidad')
plt.legend()
plt.show()
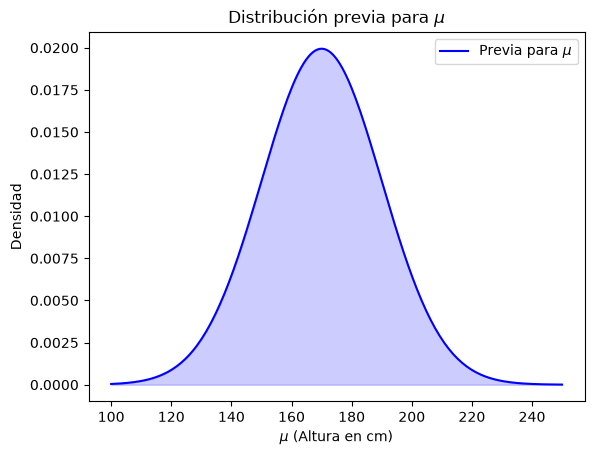
Esto significa que el modelo asume que la altura promedio está, con alta probabilidad, entre \(130\) cm y \(210\) cm.
La previa para \(\sigma\) es plana; una distribución uniforme. Esta distribución restringe a \(\sigma\) a estar entre cero y \(50\) con igual probabilidad:
# previa para sigma
prior_sigma = uniform(loc=0, scale=50)
#grafica previa sigma
x = np.linspace(-50, 100, 1000)
y = prior_sigma.pdf(x)
plt.plot(x, y, label='Previa para $\sigma$', color='green')
plt.fill_between(x, y, alpha=0.2, color='green')
plt.title('Distribución previa para $\sigma$')
plt.xlabel('$\sigma$ (Desviación estándar en cm)')
plt.ylabel('Densidad')
plt.legend()
plt.show()
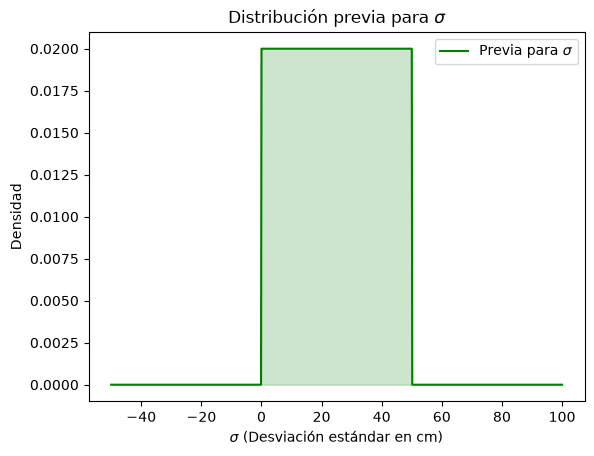
La desviación estándar debe ser necesariamente positiva, por lo que resulta lógico fijar cero como límite inferior de su distribución uniforme.
Ahora bien, ¿qué implica que esté acotada superiormente en \(50\) cm?
Esto significa que esperamos que la dispersión de las alturas no sea mayor que \(50\) cm.
Dado que, en una distribución normal, la mayoría de los valores se encuentran aproximadamente dentro de dos desviaciones estándar alrededor de la media, esta elección sugiere que las alturas individuales se concentrarán en un rango aproximado de:
Es decir, esperamos que prácticamente todas las observaciones se encuentren dentro de un intervalo de alrededor de 100 cm en torno a la altura promedio.
Simulación previa predictiva#
Para ver que tan razonables son nuestras previas, normalmente lo que hacemos es hacer simulaciones previas predictivas. Es decir, en este caso, muestreamos las previas y con eso vemos la distribución de alturas resultantes. Esto nos permite evaluar la calidad de nuestras previas.
import arviz as az
# Simulación previa predictiva
N = 1000
mu_samples = prior_mu.rvs(N)
sigma_samples = prior_sigma.rvs(N)
height_samples = norm(loc=mu_samples, scale=sigma_samples).rvs()
mu_samples→ son 1000 valores posibles de la media de la altura que tu modelo cree posibles antes de ver ningún dato (según la priorprior_mu).
sigma_samples→ son 1000 valores posibles de la desviación estándar que tu modelo cree posibles antes de ver ningún dato (segúnprior_sigma).
height_samples→ son valores de altura simulados a partir de esas combinaciones demu_samplesysigma_samples.En otras palabras:
height_samplesno son los datos reales ni derivados de ellos.
Son datos inventados por el modelo bajo tus priors.
height_samples.shape
(1000,)
height_samples[:10]
array([192.40159213, 166.84829503, 157.22160609, 177.53416254,
198.10025195, 281.80630407, 191.21941658, 147.17823404,
148.01497735, 155.66601354])
az.plot_kde(height_samples)
plt.xlabel('height')
plt.ylabel('Density')
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[16], line 1
----> 1 az.plot_kde(height_samples)
2 plt.xlabel('height')
3 plt.ylabel('Density')
File ~/checkouts/readthedocs.org/user_builds/modelos-graficos-probabilisticos/envs/v2026/lib/python3.13/site-packages/arviz/__init__.py:118, in __getattr__(name)
110 warnings.warn(
111 "arviz.InferenceData is no longer available on the "
112 "arviz package; ArviZ now uses xarray's DataTree for the same "
113 f"role. See the migration guide: {_MIGRATION_GUIDE_URL}",
114 MigrationWarning,
115 )
117 return DataTree
--> 118 raise AttributeError(f"module {__name__!r} has no attribute {name!r}")
AttributeError: module 'arviz' has no attribute 'plot_kde'
Notemos que la distribución previa para la altura no es una distribución gaussiana en sí misma.
Esto es correcto: representa la distribución de probabilidad sobre las posibles alturas antes de observar los datos, es decir, nuestras creencias iniciales acerca de los valores plausibles de la altura promedio y su variabilidad.
La simulación predictiva previa es una herramienta muy útil para evaluar la calidad de estas suposiciones.
Mediante ella, podemos visualizar qué tipo de datos esperaríamos observar si nuestras previas fueran ciertas. Esto nos permite detectar previas poco realistas.
Por ejemplo, una previa como:
generaría alturas simuladas con una variabilidad excesiva, incluyendo valores poco plausibles (como alturas negativas o mayores a 3 metros), lo que indicaría que esta previa no es adecuada para el fenómeno que queremos modelar.
A continuación, realizamos una simulación previa predictiva para el modelo de alturas descrito anteriormente.
# mu ~ N(170, 100)
prior_mu = norm(loc=170, scale=100)
# Simulación previa predictiva
N = 1000
mu_samples = prior_mu.rvs(N)
sigma_samples = prior_sigma.rvs(N)
height_samples = norm(loc=mu_samples, scale=sigma_samples).rvs()
az.plot_kde(height_samples)
<Axes: >
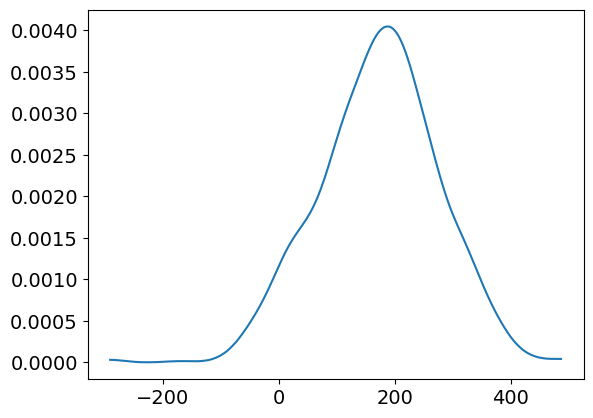
# Porcentaje de registros con altura negativa
(height_samples < 0).mean()
np.float64(0.051)
Con esta previa, estamos afirmando que, antes de ver los datos, el modelo espera que aproximadamente un 6 % de la población tenga una altura negativa.
Nota
¿Importa esto?
En principio, si contamos con una gran cantidad de datos, el impacto de una previa mal especificada será mínimo, ya que la información observada dominará la inferencia.
Sin embargo, esto no siempre ocurre: cuando los datos son escasos, las previas pueden influir significativamente en los resultados.
Por esta razón, siempre conviene elegir previas que reflejen de la mejor manera posible nuestro conocimiento previo y expectativas realistas sobre el fenómeno.
En este caso, nos quedaremos con nuestras previas originales, que representan de forma más coherente la variabilidad esperada en la altura humana.
Muestras Markov Chain Monte Carlo (MCMC)#
Recordamos el modelo:
adultos.shape
(352, 4)
import pymc as pm
with pm.Model() as modelo_altura_adultos:
mu = pm.Normal('mu',
mu=170,
sigma=20)
sigma = pm.Uniform('sigma',
lower=0,
upper=50)
height = pm.Normal('height',
mu=mu,
sigma=sigma,
observed=adultos['height'].values)
Hasta acá solo hemos definido el modelo. Si queremos muestrear la distribución posterior usando MCMC:
with modelo_altura_adultos:
idata = pm.sample()
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 0 seconds.
idata
-
<xarray.Dataset> Size: 72kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 Data variables: mu (chain, draw) float64 32kB 154.6 155.0 155.0 ... 154.7 154.7 154.3 sigma (chain, draw) float64 32kB 7.461 7.307 7.307 ... 7.666 7.666 7.539 Attributes: created_at: 2026-03-23T22:52:12.864413+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.33512020111083984 tuning_steps: 1000 -
<xarray.Dataset> Size: 528kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: (12/18) perf_counter_diff (chain, draw) float64 32kB 6.1e-05 ... 5.683e-05 process_time_diff (chain, draw) float64 32kB 6.1e-05 ... 5.8e-05 energy_error (chain, draw) float64 32kB 0.02446 0.4745 ... 0.1572 smallest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan largest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan acceptance_rate (chain, draw) float64 32kB 0.6497 0.6222 ... 0.885 ... ... divergences (chain, draw) int64 32kB 0 0 0 0 0 0 ... 0 0 0 0 0 0 perf_counter_start (chain, draw) float64 32kB 7.567e+04 ... 7.567e+04 n_steps (chain, draw) float64 32kB 3.0 1.0 1.0 ... 3.0 3.0 reached_max_treedepth (chain, draw) bool 4kB False False ... False False tree_depth (chain, draw) int64 32kB 2 1 1 2 2 2 ... 2 2 1 2 2 2 max_energy_error (chain, draw) float64 32kB 0.8209 0.4745 ... 0.1572 Attributes: created_at: 2026-03-23T22:52:12.870660+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.33512020111083984 tuning_steps: 1000 -
<xarray.Dataset> Size: 6kB Dimensions: (height_dim_0: 352) Coordinates: * height_dim_0 (height_dim_0) int64 3kB 0 1 2 3 4 5 ... 347 348 349 350 351 Data variables: height (height_dim_0) float64 3kB 151.8 139.7 136.5 ... 156.2 158.8 Attributes: created_at: 2026-03-23T22:52:12.872455+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1
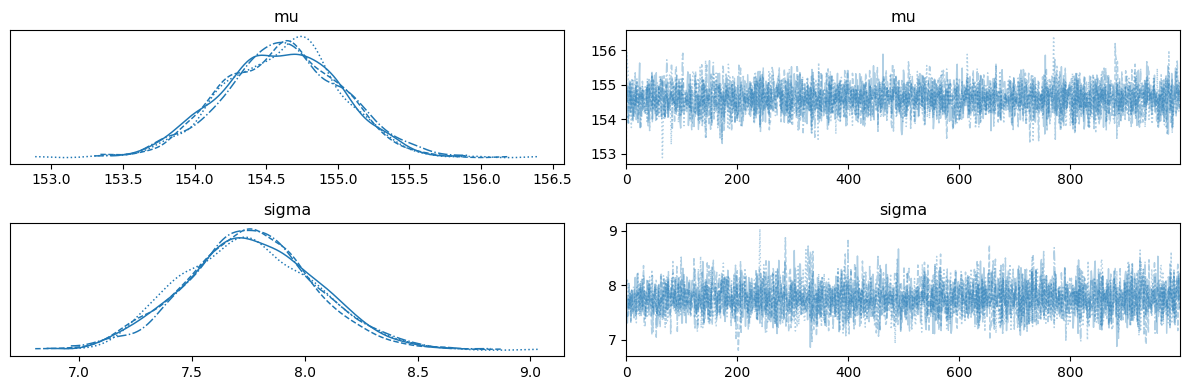
# az.plot_trace
az.plot_trace(idata)
plt.tight_layout()
# az.summary
az.summary(idata)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| mu | 154.609 | 0.409 | 153.836 | 155.350 | 0.007 | 0.007 | 3997.0 | 2841.0 | 1.0 |
| sigma | 7.759 | 0.288 | 7.233 | 8.308 | 0.005 | 0.005 | 4021.0 | 2736.0 | 1.0 |
adultos.describe()
| height | weight | age | male | |
|---|---|---|---|---|
| count | 352.000000 | 352.000000 | 352.000000 | 352.000000 |
| mean | 154.597093 | 44.990486 | 41.138494 | 0.468750 |
| std | 7.742332 | 6.456708 | 15.967855 | 0.499733 |
| min | 136.525000 | 31.071052 | 18.000000 | 0.000000 |
| 25% | 148.590000 | 40.256290 | 28.000000 | 0.000000 |
| 50% | 154.305000 | 44.792210 | 39.000000 | 0.000000 |
| 75% | 160.655000 | 49.292693 | 51.000000 | 1.000000 |
| max | 179.070000 | 62.992589 | 88.000000 | 1.000000 |
Simulación posterior predictiva#
¿Qué hacemos con la simulación posterior predictiva?
La simulación posterior predictiva nos permite evaluar qué tan bien nuestro modelo, después de ver los datos, puede reproducir los patrones observados.
Mientras que en la simulación previa predictiva generábamos datos hipotéticos a partir de las previas (antes de observar nada), en la posterior predictiva generamos nuevos datos a partir de la distribución posterior, es decir, usando lo que el modelo aprendió de los datos reales.
En otras palabras:
La previa predictiva responde a la pregunta:
¿Qué tipo de datos esperaría ver si mis creencias iniciales fueran ciertas?
La posterior predictiva responde a la pregunta:
¿Qué tipo de datos esperaría ver si mi modelo y mis datos observados describen correctamente la realidad?
De esta manera, la simulación posterior predictiva es una herramienta clave para evaluar el ajuste del modelo, pues nos permite comparar los datos simulados a partir de la posterior con los datos observados y detectar posibles discrepancias.
with modelo_altura_adultos:
idata.extend(pm.sample_posterior_predictive(idata))
Sampling: [height]
idata
-
<xarray.Dataset> Size: 72kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 Data variables: mu (chain, draw) float64 32kB 154.6 155.0 155.0 ... 154.7 154.7 154.3 sigma (chain, draw) float64 32kB 7.461 7.307 7.307 ... 7.666 7.666 7.539 Attributes: created_at: 2026-03-23T22:52:12.864413+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.33512020111083984 tuning_steps: 1000 -
<xarray.Dataset> Size: 11MB Dimensions: (chain: 4, draw: 1000, height_dim_0: 352) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 993 994 995 996 997 998 999 * height_dim_0 (height_dim_0) int64 3kB 0 1 2 3 4 5 ... 347 348 349 350 351 Data variables: height (chain, draw, height_dim_0) float64 11MB 150.8 147.7 ... 148.9 Attributes: created_at: 2026-03-23T22:52:13.261448+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 -
<xarray.Dataset> Size: 528kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: (12/18) perf_counter_diff (chain, draw) float64 32kB 6.1e-05 ... 5.683e-05 process_time_diff (chain, draw) float64 32kB 6.1e-05 ... 5.8e-05 energy_error (chain, draw) float64 32kB 0.02446 0.4745 ... 0.1572 smallest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan largest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan acceptance_rate (chain, draw) float64 32kB 0.6497 0.6222 ... 0.885 ... ... divergences (chain, draw) int64 32kB 0 0 0 0 0 0 ... 0 0 0 0 0 0 perf_counter_start (chain, draw) float64 32kB 7.567e+04 ... 7.567e+04 n_steps (chain, draw) float64 32kB 3.0 1.0 1.0 ... 3.0 3.0 reached_max_treedepth (chain, draw) bool 4kB False False ... False False tree_depth (chain, draw) int64 32kB 2 1 1 2 2 2 ... 2 2 1 2 2 2 max_energy_error (chain, draw) float64 32kB 0.8209 0.4745 ... 0.1572 Attributes: created_at: 2026-03-23T22:52:12.870660+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1 sampling_time: 0.33512020111083984 tuning_steps: 1000 -
<xarray.Dataset> Size: 6kB Dimensions: (height_dim_0: 352) Coordinates: * height_dim_0 (height_dim_0) int64 3kB 0 1 2 3 4 5 ... 347 348 349 350 351 Data variables: height (height_dim_0) float64 3kB 151.8 139.7 136.5 ... 156.2 158.8 Attributes: created_at: 2026-03-23T22:52:12.872455+00:00 arviz_version: 0.23.4 inference_library: pymc inference_library_version: 5.28.1
ax = az.plot_ppc(idata)
plt.tight_layout()
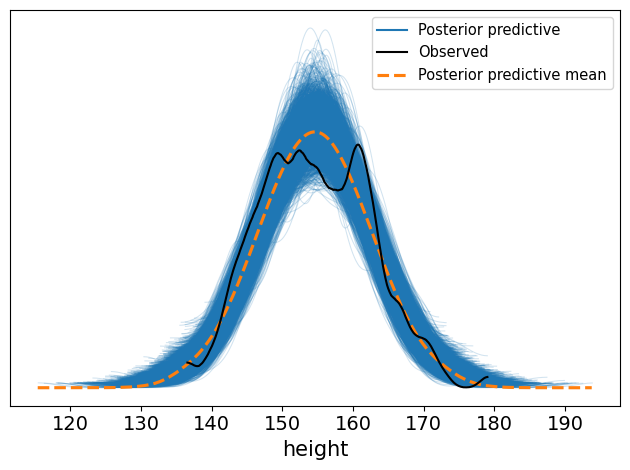
Este modelo te ayuda a entender y validar la historia que cuentan tus datos.
Aún no estás prediciendo, sino comprendiendo el proceso que podría haber generado tus observaciones.